Python数据分析(1)——数据加载与简单描述性分析
Python数据分析(1)——数据加载与简单描述性分析
- 1.读入文件
-
- 1.1 通过Python标准库导入
- 1.2 通过Pandas导入
- 1.3 逐块读取数据
- 2.初步分析
-
- 2.1 简单描述性统计
- 2.2提取特定行列
- 2.3对数据进行排序
-
- 友情链接
1.读入文件
本文通过kaggle泰坦尼克号数据进行分析介绍。(这里利用-Titanic - Machine Learning from Disaster数据https://www.kaggle.com/c/titanic/overview)
1.1 通过Python标准库导入
此处读取的文件为csv格式,Python中提供了一个表准的类库来处理csv文件。其读取方式如下,导入的数据按Numpy生成一个元组。
import numpy as np
import pandas as pd#导入numpy与pandas
from csv import reader
df='train.csv'
with open(df,'rt',encoding='UTF-8') as raw_data:
readers = reader(raw_data, delimiter=',')#界定符 ' ,'
x = list(readers)
data = np.array(x)
print(data)
print(data.shape)

1.2 通过Pandas导入
-
通过pandas.read_csv()函数实现,该函数返回DataFrame(读取文件的方式有绝对路径与相对路径两种)。
-
或通过pandas.read_table()函数实现,该函数返回DataFrame,与read_csv不同的是其中sep分隔符不同,read_csv默认’,'而read_table默认为tab制表符,而txt与csv相比的优势在于体积更小。
#data1 = pd.read_csv('train.csv')
#data1.head(3)
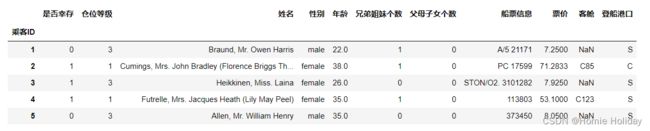
data1=pd.read_table('train.csv',sep=',', names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口'],index_col='乘客ID',header=0)
data1.head()#将英文表头转为中文
1.3 逐块读取数据
对于较大的cxv文件使用read_csv打开时可能会出现:MemoryError的报错,所以我们在读时采用chunk分块读取,再把所有chunk拼接成一个DataFrame(通过concat)。
chunker = pd.read_csv('train.csv',iterator = True , chunksize = 1000)
type(chunker)
list_c = list()
for chunk in chunker:
list_c.append(chunk)
#print(chunk, type(chunk))
res = pd.concat(list_c,axis=0,ignore_index=False)
print(res)

此外chunk还可以指定某一块进行读取。
2.初步分析
2.1 简单描述性统计
data1.info()#查看基本信息
data1.isnull().head()#查看缺失值
data1.head(10)#查看前10行
data1.tail(10)#查看后10行
#或者直接调用describe函数
data1.describe()#该函数返回数量、均值、最大最小值、标准差及四分位点,为查找异常值提供信息

test_1 = pd.read_csv('test.csv')#导入测试集
test_1.head(3)
#del test_1['a']# 删除某一列
#test_1.head(3)
data1.drop(['PassengerId','Name','Age','Ticket'],axis=1).head(3)#将['PassengerId','Name','Age','Ticket']这几个列元素隐藏

2.2提取特定行列
利用reset_index:重置索引和其他level
参数:reset_index(level=None,drop=False,inplace=False,col_level=0,col_fill=‘’)
- drop: 重新设置索引后是否将原索引作为新的一列并入DataFrame,默认值False 。
- inplace: 是否在原有DataFrame上改动,默认值False 。
- level: 如果索引(index)有多个列,仅从索引中删除level指定的列,默认删除所有列 。
- col_level: 如果列名(columns)有多个级别,决定被删除的索引将插入哪个级别,默认插入第一级。
- col_fill: 如果列名(columns)有多个级别,决定其他级别如何命名。
midage = test_1[(test_1["Age"]>10)& (test_1["Age"]<50)]#以"Age"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
midage.head(3)
midage = midage.reset_index(drop = True)#drop:False表示重新设置索引后将原索引作为新的一列并入DataFrame,True表示删除原索引
midage.loc[[100,105,108],['Pclass','Name','Sex']] #若不进行上述reset_index,此处会报错不存在 108 该索引

2.3对数据进行排序
sort_values()用于对数据进行排序
- by:指定需要排序的行或者列
- axis:指明需要排序的是还是列
- ascending:指明升序还是降序,默认升序
data1.sort_values(by=['票价', '年龄'], ascending=False).head(3)

本文就先到这里叭
友情链接
欢迎拜访(https://github.com/datawhalechina/hands-on-data-analysis/)