网络爬虫笔记—图形验证码获取
网络爬虫笔记—图形验证码获取
1、验证码获取思路
- 1)使用
selenium库操作谷歌浏览器,打开目标网站; - 2)对目标网站进行截图,并将图片保存到本地;
- 3)获取验证码元素节点在屏幕上的位置,即横纵坐标;
- 4)使用
Image库读取2)中保存的截图; - 5)利用3)获取的元素节点位置,对4)中读取的截图,再次进行局部截图,只截取元素节点位置对应部分。
2、执行步骤
2.1、导入所需库和打开目标网站
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from PIL import Image
browser = webdriver.Chrome()#创建谷歌浏览器
myurl="https://my.cnki.net/Register/CommonRegister.aspx?returnUrl=https://www.cnki.net"
browser.get(myurl)#打开目标网站
browser.maximize_window()#将浏览器全屏
time.sleep(2)#代码停止2秒
- 目标网站:知网注册页面
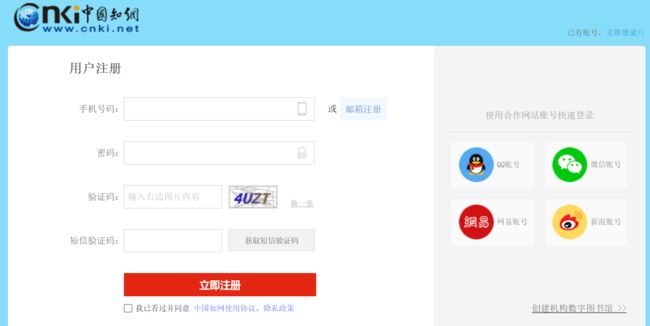
- 代码解析
1)browser.maximize_window():该代码可以将浏览器全屏显示,其目的是为了方便后面截图,如不全屏会影响后面元素节点的截取;
2)time.sleep(2):该代码可使程序暂停2秒执行,其目的是给网页加载预留足够的时间,以保证截图时,网页已加载完成。
2.2、网页截图保存
browser.save_screenshot("screenshot.png")#网页截图,保存
- 代码解析
browser.save_screenshot("screenshot.png"):此代码可以对创建的谷歌浏览器进行截图,并保存到本地,图片名称为:“screenshot.png”。因为我用的Spyder编辑器,当保存截图不指定路径时,系统会自动将图片保存到代码文件路径。如指定路径,则会保存到对应文件夹下,如:将screenshot.png修改为D:\宏蜘蛛\screenshot.png,则截图就会保存到D盘的“宏蜘蛛”文件夹下。
2.3、获取验证码元素位置
code_element = browser.find_element(By.XPATH,'//*[@id="phoneCheckCode"]')#通过Xpath方法获取验证码元素
left = code_element.location['x']*1.5#返回一个字典格式,里面有两个参数x和y,代表元素的位置,1.5表示的电脑缩放比例
top = code_element.location['y']*1.5
right = code_element.size['width']*1.5+left#验证码元素右边的点位置
height = code_element.size['height']*1.5+top#验证码元素左上边点位置
- 代码解析
1)code_element = browser.find_element(By.XPATH,'//*[@id="phoneCheckCode"]')
通过Xpath方法获取验证码节点元素,针对元素的获取方法,大家可参考我此前发布的文章:网络爬虫笔记—Selenium—3、查找节点。
2)left = code_element.location['x']*1.5
a)位置示意
code_element.location会返回一个字典格式的数据,字典的key是x和y。对x和y的理解,大家可结合下图,进行理解。
以截图的左下角作为原点(0,0),截图最下方的边缘作为X轴,截图最左边的边缘作为Y轴。下图中的A点对应的位置坐标就是验证码元素.location方法返回的x和y的值。可以看出.location方法返回的是元素左下角点所对应的位置(图中的A点)。

b)为何后面要乘1.5
.location方法返回的坐标点位置,是基于电脑显示器无缩放的情况的坐标,但我的电脑是以150%缩放显示的,所以后面要乘以1.5,从而将坐标位置调整为我的电脑显示的位置,要不然后面截图的时候,会截取不到验证码图片。

3)right = code_element.size['width']*1.5+left
code_element.size会返回元素节点的宽和高,是一个字典格式,两个key分别为width和height。其目的为了后面截取验证码图片使用。
2.4、读取截图、截取验证码图片和保存验证码图片
im = Image.open("screenshot.png")#读取全屏截图
img = im.crop((left, top, right, height))#截取验证码图片
img.save("mycode.png")#保存验证码图片
- 代码解析
1)im = Image.open("screenshot.png"):该代码可以读取截取的图片,"screenshot.png"为图片名,如果代码文件和图片不在同一个文件夹下,需要在图片名称前加上图片路径。
2)img = im.crop((left, top, right, height)):该代码可以根据指定位置,对图片进行截图。括号中的参数,就是我们在“2.3、获取验证码元素位置”获取的验证码在图片中的位置。
3)img.save("mycode.png"):该代码可以保存图片到本地,这里是保存获取的验证码图片。同时也可以指定存储位置,默认保存在代码文件夹下。
以上就是验证码获取的方法,获取验证码之后会涉及到验证码识别,针对验证码识别的问题,大家可参考我之前写的这篇文章:网络爬虫笔记—图形验证码识别。
- 本篇笔记首先在微信公众号“宏蜘蛛”上发布,链接为:网络爬虫笔记—图形验证码获取
—End—
参考资料
1、python实现获取登录验证码图片 - Tester_Jhm - 博客园 (cnblogs.com)
2、问题解决:selenium中定位元素后使用location获取坐标值出现偏差_我敲的贼快的博客-CSDN博客_元素的location获取的不对