CVPR2022学习-人脸识别:An Efficient Training Approach for Very Large Scale Face Recognition
论文地址: https://arxiv.org/pdf/2105.10375.pdf
代码地址: GitHub - tiandunx/FFC: Official code for fast face classification
看标题大概的理解-其解决的问题:
现阶段我们训练人脸提特征网络,随着人脸ID数据的增加,dataloader和fc层的计算导致硬件开销极大。训练过程中理论上希望将大量数据集中的ID都用上,作者提出这篇文章,能够在一定层度上缓解大数据量情况下,dataloader和fc层参数量的限制。
读文章前大致看了下代码,作者提出数据存储加载方式以使用迭代器加载2个dataloader(该方式在多任务以及多标签中也会经常使用,感觉算是技巧吧,具体论文中的内容后续阅读记录)。
Abstract :
大致理解:随着人脸识别数据集的不断扩充,设计一种高效的训练方法,降低全连接(FC)层的百万级维数所致的计算和内存损耗。提出了一种新的训练方法人脸分类(F2C),目的:在不牺牲性能的情况下减轻时间和成本。提出采用动态类池(DCP)来动态存储和更新身份的特征,替代现有fc 方法。 DCP后续在论文中需研读!
Introduction
介绍了现阶段DNN和人脸识别训练近期的发展历程、相关大规模数据的简单说明、magin的作用描述。webface260为例引出目前人脸数据的量级,举例:当人脸id达到1000万时,整个网络中FC预测层的计算成本和内存占用相当大,在现阶针对FC的优化分两类:1.将fc分布式的搞在不同gpu上做运算;2.通过一定方法降低fc层的一些神经元参数来实现,但该方法仍然需要缓存fc层参数(参考VFCF)。
文中思考的方法是:如何有效地降低由高维FC层造成的计算和内存成本。

为解决图示问题:论文提出了一种有效的超大型人脸数据集的训练方法(F2C)。
论方法理解:
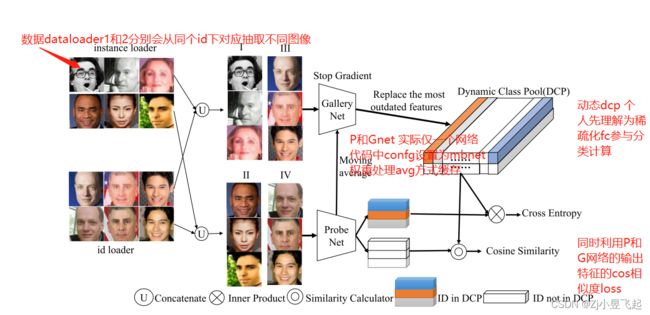
1.设计了两个dataloader 使用迭代器的方式实现交替训练
##---------ins dataloader--------------------------------------
instance_db = MultiLMDBDataset(conf.source_lmdb, conf.source_file)
instance_sampler = DistributedSampler(instance_db)
instance_loader = DataLoader(instance_db, conf.batch_size, False, instance_sampler,
num_workers=8, pin_memory=False, drop_last=True)
##----------id dataloader-------------------------------------
id_db = PairLMDBDatasetV2(conf.source_lmdb, conf.source_file)
id_sampler = DistributedSampler(id_db)
id_loader = DataLoader(id_db, conf.batch_size, False, id_sampler, num_workers=8,
pin_memory=False, drop_last=True)
##-----------------------------------------------------------------
#训练技巧 利用python next iter 方法,在多任务或者多分枝中常用此方法迭代多个dataloader
try:
images1, images2, id_indexes = next(id_iter)
except:
id_iter = iter(id_loader)
images1, images2, id_indexes = next(id_iter)
2.设计量个分支网络(PNet 和GNet)处理两个dataloader的数据,并缓存权重
class FFC(Module):
def __init__(self, net_type, feat_dim, queue_size=7409, scale=32.0, loss_type='AM',
margin=0.4, momentum=0.99,
neg_margin=0.25, pretrained_model_path=None, num_class=None):
super(FFC, self).__init__()
assert loss_type in ('AM', 'Arc', 'SV')
self.probe_net = create_net(net_type, feat_dim=feat_dim, fp16=True)
self.gallery_net = create_net(net_type, feat_dim=feat_dim, fp16=True)
3 PNet和GNe使用相同网络权重如何共享:Moveing avg
权重mov avg计算:
##-------------------Pnet 和Gnet params 如何整合输出到一个网络中
for param_p, param_g in zip(self.probe_net.parameters(), self.gallery_net.parameters()):
param_g.data = param_g.data * self.m + param_p.data * (1. - self.m)
##-----------参数copy 出-------------------------------
for param_p, param_g in zip(self.probe_net.parameters(), self.gallery_net.parameters()):
param_g.data.copy_(param_p.data) # initialize
param_g.requires_grad = False # not update by gradient
4.DCP
如图和代码所示,因打他loader可根据同id选出不同图像集,因此可分出正样本例和负样本例,所以在处理时可以用该方法替换原有fc 映射对多类算误差loss 的方法:
if pos_label_idx.numel() > 0:
pos_cos_theta = cos_theta[pos_label_idx].float()
pos_label = label[pos_label_idx]
batch_size = pos_cos_theta.shape[0]
gt = pos_cos_theta[torch.arange(0, batch_size), pos_label].view(-1, 1)
sin_theta = torch.sqrt(1.0 - torch.pow(gt, 2))
cos_theta_m = gt * math.cos(self.margin) - sin_theta * math.sin(self.margin)
pos_cos_theta.scatter_(1, pos_label.data.view(-1, 1), cos_theta_m)
cls_loss = F.cross_entropy(pos_cos_theta * self.scale, pos_label)
else:
cls_loss = 0
if outlier_label.numel() > 0:
outlier_cos_theta = cos_theta[outlier_label]
outlier_idx = torch.argsort(outlier_cos_theta, dim=1, descending=True)[:, :self.hard_neg]
hard_negative = torch.clip(torch.gather(outlier_cos_theta, 1, outlier_idx), 0)
neg_loss = torch.mean(hard_negative)
else:
neg_loss = 0
loss = cls_loss + neg_loss
return loss5.其他:
训练数据加载加速,将数据先生成lmdb;相关脚本代码中,该方法类caffe训练也算人脸实际训练中偶用方法吧;
注:下班后扫读,如果个人理解有误,再及时更正。