【ResNet】Pytorch从零构建ResNet50
Pytorch从零构建ResNet
第一章 从零构建ResNet18
第二章 从零构建ResNet50
文章目录
- Pytorch从零构建ResNet
- 前言
- 一、Res50和Res18的区别?
-
- 1. 残差块的区别
- 2. ResNet50具体结构
- 二、ResNet分步骤实现
- 三、完整例子+测试
- 总结
前言
-
ResNet 目前是应用很广的网络基础框架,所以有必要了解一下,并且resnet结构清晰,适合练手.
-
有了前面resnet18的经验,现在搭建50就没那么难了,如果没有看,请移步 第一章 从零构建ResNet18
-
本文使用以下环境构筑
torch 1.11 torchvision 0.12.0 python 3.9
一、Res50和Res18的区别?
1. 残差块的区别
-
如下图
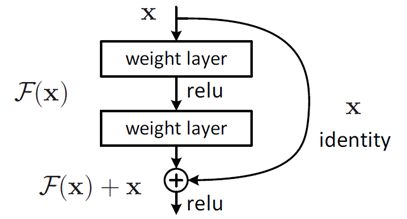
这种跳跃连接就叫做shortcut connection(类似电路中的短路)。上面这种两层结构的叫BasicBlock,一般适用于ResNet18和ResNet34
而ResNet50以后都使用下面这种三层的残差结构叫Bottleneck
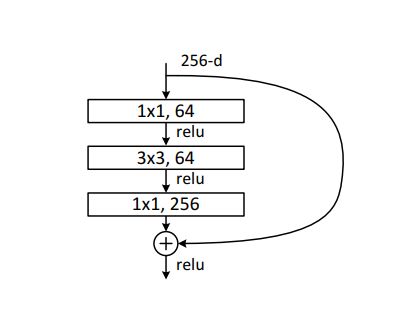
最明显的区别就是,Bottleneck中有三层,中间层是kernel为3的卷积层,一头一尾则是kernel为1的卷积,明显是用来做通道数的变换。 -
残差块个数的变化
刚才说的是残差块内部的个数变化,现在这个指的是,整个残差块数量的变化,很容易理解,就不多说了。
2. ResNet50具体结构
上面简单说了一下ResNet1818和ResNet50的区别,接下来用图来看一下ResNet50网络的结构
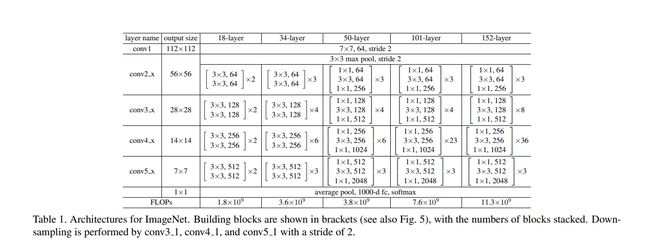
可以看到,50层的网络也是有五个部分组成,从conv2开始,每层都有不同个数的残差块,分别为3,4,6,3. 接下来再具体50层的具体结构
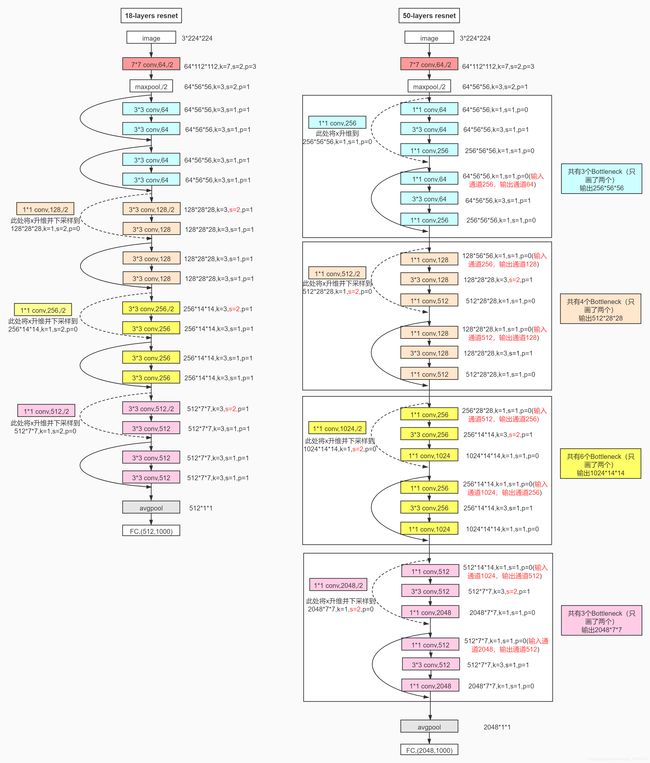
其中,蓝色部分为conv2,然后往下依次按颜色划分为conv3、conv4,conv5。
需要注意的地方有以下几点:
- 与18层不同的是,50层的ResNet在第一次池化之后,就需要将X升维,也就是虚线对应的部分,不可以直接相加
- Bottleneck的最后一层是进行升维操作的,所以在几个相同Bottleneck堆叠的时候,需要注意输入维度的转变。例如conv2有三个Bottleneck,将这三个编号为a,b,c,则这三个的输入输出分别为
- a的输入维度:64,64,64,输出维度:64,64,256
- b的输入维度:256,64,64,输出维度:64,64,256
- c的输入维度:256,64,64,输出维度:64,64,256
二、ResNet分步骤实现
首先实现残差块:
class Bottleneck(nn.Module):
def __init__(self,in_channels,out_channels,stride=[1,1,1],padding=[0,1,0],first=False) -> None:
super(Bottleneck,self).__init__()
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size=1,stride=stride[0],padding=padding[0],bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), # 原地替换 节省内存开销
nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=stride[1],padding=padding[1],bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), # 原地替换 节省内存开销
nn.Conv2d(out_channels,out_channels*4,kernel_size=1,stride=stride[2],padding=padding[2],bias=False),
nn.BatchNorm2d(out_channels*4)
)
# shortcut 部分
# 由于存在维度不一致的情况 所以分情况
self.shortcut = nn.Sequential()
if first:
self.shortcut = nn.Sequential(
# 卷积核为1 进行升降维
# 注意跳变时 都是stride==2的时候 也就是每次输出信道升维的时候
nn.Conv2d(in_channels, out_channels*4, kernel_size=1, stride=stride[1], bias=False),
nn.BatchNorm2d(out_channels*4)
)
def forward(self, x):
out = self.bottleneck(x)
out += self.shortcut(x)
out = F.relu(out)
return out
接下来是ResNet50的具体实现
# 采用bn的网络中,卷积层的输出并不加偏置
class ResNet50(nn.Module):
def __init__(self,Bottleneck, num_classes=10) -> None:
super(ResNet50, self).__init__()
self.in_channels = 64
# 第一层作为单独的 因为没有残差快
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3,bias=False),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# conv2
self.conv2 = self._make_layer(Bottleneck,64,[[1,1,1]]*3,[[0,1,0]]*3)
# conv3
self.conv3 = self._make_layer(Bottleneck,128,[[1,2,1]] + [[1,1,1]]*3,[[0,1,0]]*4)
# conv4
self.conv4 = self._make_layer(Bottleneck,256,[[1,2,1]] + [[1,1,1]]*5,[[0,1,0]]*6)
# conv5
self.conv5 = self._make_layer(Bottleneck,512,[[1,2,1]] + [[1,1,1]]*2,[[0,1,0]]*3)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(2048, num_classes)
def _make_layer(self,block,out_channels,strides,paddings):
layers = []
# 用来判断是否为每个block层的第一层
flag = True
for i in range(0,len(strides)):
layers.append(block(self.in_channels,out_channels,strides[i],paddings[i],first=flag))
flag = False
self.in_channels = out_channels * 4
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.avgpool(out)
out = out.reshape(x.shape[0], -1)
out = self.fc(out)
return out
可以输出网络结构看一下
res50 = ResNet50(Bottleneck)
print(res50)
ResNet50(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
(2): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(conv3): Sequential(
(0): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
(2): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
(3): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(conv4): Sequential(
(0): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
(2): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
(3): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
(4): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
(5): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(conv5): Sequential(
(0): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
(2): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=10, bias=True)
)
至此,Resnet50就构建好了
三、完整例子+测试
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, utils
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data.dataset import Dataset
from torchvision.transforms import transforms
from pathlib import Path
import cv2
from PIL import Image
import torch.nn.functional as F
%matplotlib inline
%config InlineBackend.figure_format = 'svg' # 控制显示
transform = transforms.Compose([ToTensor(),
transforms.Normalize(
mean=[0.5,0.5,0.5],
std=[0.5,0.5,0.5]
),
transforms.Resize((224, 224))
])
training_data = datasets.CIFAR10(
root="data",
train=True,
download=True,
transform=transform,
)
testing_data = datasets.CIFAR10(
root="data",
train=False,
download=True,
transform=transform,
)
class Bottleneck(nn.Module):
def __init__(self,in_channels,out_channels,stride=[1,1,1],padding=[0,1,0],first=False) -> None:
super(Bottleneck,self).__init__()
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size=1,stride=stride[0],padding=padding[0],bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), # 原地替换 节省内存开销
nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=stride[1],padding=padding[1],bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), # 原地替换 节省内存开销
nn.Conv2d(out_channels,out_channels*4,kernel_size=1,stride=stride[2],padding=padding[2],bias=False),
nn.BatchNorm2d(out_channels*4)
)
# shortcut 部分
# 由于存在维度不一致的情况 所以分情况
self.shortcut = nn.Sequential()
if first:
self.shortcut = nn.Sequential(
# 卷积核为1 进行升降维
# 注意跳变时 都是stride==2的时候 也就是每次输出信道升维的时候
nn.Conv2d(in_channels, out_channels*4, kernel_size=1, stride=stride[1], bias=False),
nn.BatchNorm2d(out_channels*4)
)
# if stride[1] != 1 or in_channels != out_channels:
# self.shortcut = nn.Sequential(
# # 卷积核为1 进行升降维
# # 注意跳变时 都是stride==2的时候 也就是每次输出信道升维的时候
# nn.Conv2d(in_channels, out_channels*4, kernel_size=1, stride=stride[1], bias=False),
# nn.BatchNorm2d(out_channels)
# )
def forward(self, x):
out = self.bottleneck(x)
out += self.shortcut(x)
out = F.relu(out)
return out
# 采用bn的网络中,卷积层的输出并不加偏置
class ResNet50(nn.Module):
def __init__(self,Bottleneck, num_classes=10) -> None:
super(ResNet50, self).__init__()
self.in_channels = 64
# 第一层作为单独的 因为没有残差快
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3,bias=False),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# conv2
self.conv2 = self._make_layer(Bottleneck,64,[[1,1,1]]*3,[[0,1,0]]*3)
# conv3
self.conv3 = self._make_layer(Bottleneck,128,[[1,2,1]] + [[1,1,1]]*3,[[0,1,0]]*4)
# conv4
self.conv4 = self._make_layer(Bottleneck,256,[[1,2,1]] + [[1,1,1]]*5,[[0,1,0]]*6)
# conv5
self.conv5 = self._make_layer(Bottleneck,512,[[1,2,1]] + [[1,1,1]]*2,[[0,1,0]]*3)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(2048, num_classes)
def _make_layer(self,block,out_channels,strides,paddings):
layers = []
# 用来判断是否为每个block层的第一层
flag = True
for i in range(0,len(strides)):
layers.append(block(self.in_channels,out_channels,strides[i],paddings[i],first=flag))
flag = False
self.in_channels = out_channels * 4
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.avgpool(out)
out = out.reshape(x.shape[0], -1)
out = self.fc(out)
return out
# 定义网络
res50 = ResNet50(Bottleneck)
# 保持数据集和测试机能完整划分
batch_size=64
train_data = DataLoader(dataset=training_data,batch_size=batch_size,shuffle=True,drop_last=True)
test_data = DataLoader(dataset=testing_data,batch_size=batch_size,shuffle=True,drop_last=True)
images,labels = next(iter(train_data))
print(images.shape)
img = utils.make_grid(images)
img = img.numpy().transpose(1,2,0)
mean=[0.5,0.5,0.5]
std=[0.5,0.5,0.5]
img = img * std + mean
print([labels[i] for i in range(64)])
plt.imshow(img)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = res50.to(device)
cost = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
print(len(train_data))
print(len(test_data))
epochs = 10
for epoch in range(epochs):
running_loss = 0.0
running_correct = 0.0
model.train()
print("Epoch {}/{}".format(epoch+1,epochs))
print("-"*10)
for X_train,y_train in train_data:
# X_train,y_train = torch.autograd.Variable(X_train),torch.autograd.Variable(y_train)
X_train,y_train = X_train.to(device), y_train.to(device)
outputs = model(X_train)
_,pred = torch.max(outputs.data,1)
optimizer.zero_grad()
loss = cost(outputs,y_train)
loss.backward()
optimizer.step()
running_loss += loss.item()
running_correct += torch.sum(pred == y_train.data)
testing_correct = 0
test_loss = 0
model.eval()
for X_test,y_test in test_data:
# X_test,y_test = torch.autograd.Variable(X_test),torch.autograd.Variable(y_test)
X_test,y_test = X_test.to(device), y_test.to(device)
outputs = model(X_test)
loss = cost(outputs,y_test)
_,pred = torch.max(outputs.data,1)
testing_correct += torch.sum(pred == y_test.data)
test_loss += loss.item()
print("Train Loss is:{:.4f}, Train Accuracy is:{:.4f}%, Test Loss is::{:.4f} Test Accuracy is:{:.4f}%".format(
running_loss/len(training_data), 100*running_correct/len(training_data),
test_loss/len(testing_data),
100*testing_correct/len(testing_data)
))
数据的可视化,是没有问题的

然后看看跑的结果,这里因为配置原因,只跑了五轮

到目前为止,pytorch构建resnet50就完成了。有什么问题可以评论或者私信,欢迎各位指出问题
总结
通过手写ResNet18和50,可以加深对残差网络的理解,同时运用pytorch更加熟练。
PS: 此博客同时更新于个人博客