搞懂激活函数(Sigmoid/ReLU/LeakyReLU/PReLU/ELU)
1. 简介
在深度学习中,输入值和矩阵的运算是线性的,而多个线性函数的组合仍然是线性函数,对于多个隐藏层的神经网络,如果每一层都是线性函数,那么这些层在做的就只是进行线性计算,最终效果和一个隐藏层相当!那这样的模型的表达能力就非常有限 。
实际上大多数情况下输入数据和输出数据的关系都是非线性的。所以我们通常会用非线性函数对每一层进行激活,大大增加模型可以表达的内容(模型的表达效率和层数有关)。
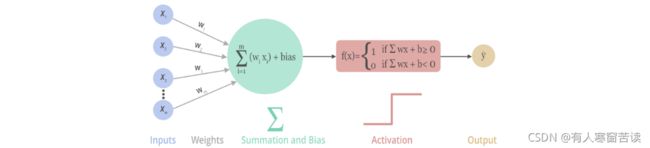
这时就需要在每一层的后面加上激活函数,为模型提供非线性,使得模型可以表达的形式更多,同时也可以更改模型的输出值,使模型可以实现回归或者分类的功能。激活函数是连续的(continuous),且可导的(differential)。常见的激活函数有Sigmoid、Tanh、ReLU和Leaky ReLU。下面分别对其进行介绍。
2. 函数饱和性
假设 f ( x ) f(x) f(x) 是一个激活函数。
- 右 饱 和 右饱和 右饱和:
当 x x x 趋向于正无穷时,激活函数的导数趋近于 0 0 0,此时称为右饱和激活函数。 lim x → + ∞ f ′ ( x ) = 0 \displaystyle \lim_{x \to +\infty}{f'(x)}=0 x→+∞limf′(x)=0 - 左 饱 和 左饱和 左饱和:
当 x x x 趋向于负无穷时,激活函数的导数趋近于 0 0 0,此时称为左饱和激活函数。 lim x → − ∞ f ′ ( x ) = 0 \displaystyle \lim_{x \to -\infty}{f'(x)}=0 x→−∞limf′(x)=0 - 饱 和 函 数 饱和函数 饱和函数:
当一个函数既满足右饱和,又满足左饱和,则称为饱和激活函数,否则称为非饱和激活函数。 - 硬 饱 和 硬饱和 硬饱和:
对于任意的 x x x,如果存在常数 c c c,当 x > c x>c x>c 时,恒有 f ′ ( x ) = 0 {f'(x)}=0 f′(x)=0,则称其为右硬饱和。如果对于任意的 x x x,如果存在常数 c c c,当 x < c x左硬饱和。既满足左硬饱和又满足右硬饱和的函数称之为硬饱和函数。 - 软 饱 和 软饱和 软饱和:
对于任意的 x x x,如果存在常数 c c c,当 x > c x>c x>c 时,恒有 f ′ ( x ) {f'(x)} f′(x) 趋近于 0 0 0,则称其为右软饱和。如果对于任意的 x x x,如果存在常数 c c c,当 x < c x左软饱和。既满足左软饱和又满足右软饱和的函数称之为软饱和函数。 - 常 用 的 饱 和 激 活 函 数 和 非 饱 和 激 活 函 数 常用的饱和激活函数和非饱和激活函数 常用的饱和激活函数和非饱和激活函数:
饱和激活函数有如 S i g m o i d Sigmoid Sigmoid 和 T a n h Tanh Tanh,非饱和激活函数有 R e L U ReLU ReLU;相较于饱和激活函数,非饱和激活函数可以解决“梯度消失(梯度弥散)”的问题,加快收敛。
3. 以零为中心
3.1 收敛速度
首先,我们需要给收敛速度做一个诠释。模型的最优解即是模型参数的最优解。通过逐轮迭代,模型参数会被更新到接近其最优解。这一过程中,迭代轮次多,则我们说模型收敛速度慢;反之,迭代轮次少,则我们说模型收敛速度快。
3.2 参数更新
 3.3 更新方向
3.3 更新方向
 3.4 以零为中心的影响
3.4 以零为中心的影响

![]()
4. Sigmoid(S 型生长曲线)


import torch
import matplotlib.pyplot as plt
# sigmoid 函数图像
x = torch.arange(-10,10,0.1)
y = torch.sigmoid(x)
# sigmoid 导数图像
dev_y = y*(1-y)
plt.figure()
plt.xlabel('x',loc='right')
plt.ylabel('y',loc='top',rotation=0)
# Get current axis 获得整张图表的坐标对象
ax = plt.gca()
# 隐藏右侧与上面两条边
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.yaxis.set_ticks_position('left')
# 指定 x轴 和 y轴 的绑定
ax.spines['bottom'].set_position(('data', 0))
ax.spines['left'].set_position(('data', 0))
plt.grid(color='b', linewidth='0.15' ,linestyle='-.')
plt.plot(x, y)
plt.plot(x,dev_y)
plt.xticks(torch.arange(-9,10,1))
plt.yticks(torch.arange(0,1.1,0.1))
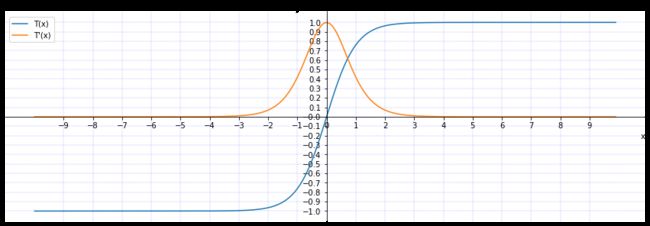
plt.show()5. Tanh(双曲正切函数)


import torch
import matplotlib.pyplot as plt
# sigmoid 函数图像
x = torch.arange(-10,10,0.1)
y = torch.tanh(x)
# sigmoid 导数图像
dev_y = 1-torch.square(y)
plt.figure(figsize=(15,5))
plt.xlabel('x',loc='right')
plt.ylabel('y',loc='top',rotation=0)
# Get current axis 获得整张图表的坐标对象
ax = plt.gca()
# 隐藏右侧与上面两条边
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.yaxis.set_ticks_position('left')
# 指定 x轴 和 y轴 的绑定
ax.spines['bottom'].set_position(('data', 0))
ax.spines['left'].set_position(('data', 0))
plt.grid(color='b', linewidth='0.15' ,linestyle='-.')
plt.xticks(torch.arange(-9,10,1))
plt.yticks(torch.arange(-3,1.1,0.1))
l1, = plt.plot(x, y)
l2, = plt.plot(x,dev_y)
plt.legend(handles=[l1,l2],labels=['T(x)','T\'(x)'],loc='best')
plt.show()6. ReLU(Rectified Linear Unit,整流线性单元函数)

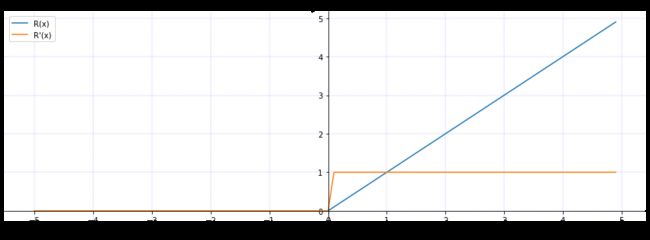

import torch
import matplotlib.pyplot as plt
# relu 函数图像
x = torch.arange(-5,5,0.1)
y = torch.relu(x)
# relu 导数图像
dev_y = torch.ge(x,0)
plt.figure(figsize=(15,5))
plt.xlabel('x',loc='right')
plt.ylabel('y',loc='top',rotation=0)
# Get current axis 获得整张图表的坐标对象
ax = plt.gca()
# 隐藏右侧与上面两条边
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.yaxis.set_ticks_position('left')
# 指定 x轴 和 y轴 的绑定
ax.spines['bottom'].set_position(('data', 0))
ax.spines['left'].set_position(('data', 0))
plt.grid(color='b', linewidth='0.15' ,linestyle='-.')
plt.xticks(torch.arange(-5,6,1))
plt.yticks(torch.arange(-1,6,1))
l1, = plt.plot(x, y)
l2, = plt.plot(x,dev_y)
plt.legend(handles=[l1,l2],labels=['R(x)','R\'(x)'],loc='best')
plt.show()7. Leaky ReLU(Leaky Rectified Linear Unit,渗漏整流线性单元函数)

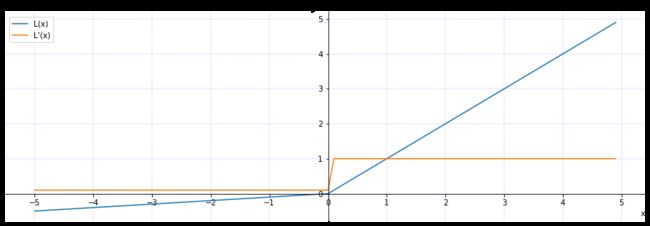
import torch
import matplotlib.pyplot as plt
# relu 函数图像
x = torch.arange(-5,5,0.1)
a = torch.tensor(0.1)
l = torch.nn.LeakyReLU(a)
y = l(x)
# relu 导数图像
dev_y = torch.ge(x,0).float()
dev_y = torch.where(dev_y == 0, a, dev_y)
dev_y
plt.figure(figsize=(15,5))
plt.xlabel('x',loc='right')
plt.ylabel('y',loc='top',rotation=0)
# Get current axis 获得整张图表的坐标对象
ax = plt.gca()
# 隐藏右侧与上面两条边
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.yaxis.set_ticks_position('left')
# 指定 x轴 和 y轴 的绑定
ax.spines['bottom'].set_position(('data', 0))
ax.spines['left'].set_position(('data', 0))
plt.grid(color='b', linewidth='0.15' ,linestyle='-.')
plt.xticks(torch.arange(-5,6,1))
plt.yticks(torch.arange(-1,6,1))
l1, = plt.plot(x, y)
l2, = plt.plot(x,dev_y)
plt.legend(handles=[l1,l2],labels=['L(x)','L\'(x)'],loc='best')
plt.show()8. Sigmoid 和梯度消失(Vanishing Gradients)
8.1 梯度消失是如何发生的?
梯度消失是一个老生长谈的话题了,我们先通过一个最简单的网络回顾下梯度消失是如何发生的,该网络由4个神经元 线性组成,神经元的激活函数都为Sigmoid。

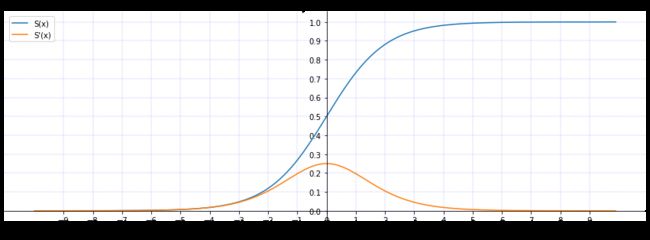
Sigmoid的函数图像和Sigmoid的梯度函数图像分别如下,从图像可以看出,函数两个边缘的梯度约为0,梯度的取值范围为(0,0.25)。:
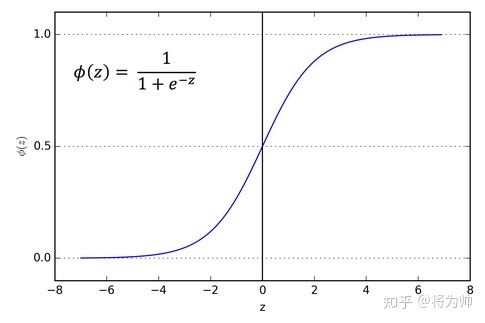
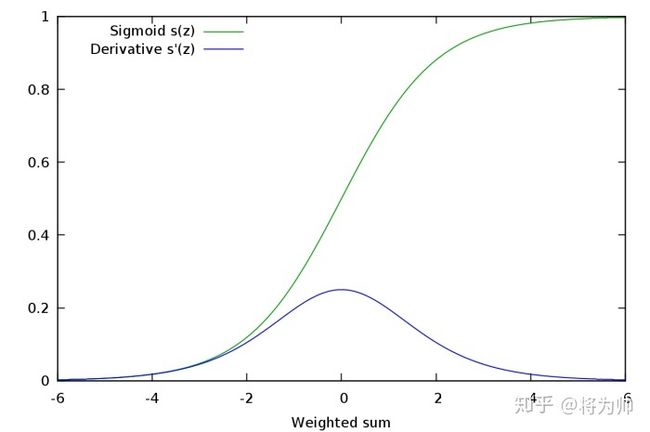
当我们求激活函数输出相对于权重参数w的偏导时,Sigmoid函数的梯度是表达式中的一个乘法因子。
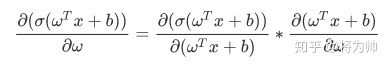
回到上文拥有4个神经元的网络上来,运用链式求导法则,得到Loss函数相对于a神经元的输出值的偏导表达式如下:
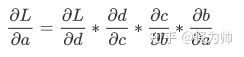
因为每个神经元(a/b/c/d)都是复合函数,所以上面式子中的每一项都可以更进一步展开,以d对c的导数举例,展开如下,可以看到式子的中间项是Sigmoid函数的梯度。那么拥有4个神经元的网络的Loss函数相对于第一层神经元a的偏导表达式中就包含4个Sigmoid梯度的乘积。而实际的神经网络层数少则数十多则数百,这么多范围在(0,0.25)的数的乘积,将会是一个非常小的数字。而梯度下降法更新参数完全依赖于梯度值,极小的梯度无法让参数得到有效更新,即使有微小的更新,浅层和深层网络参数的更新速率也相差巨大。该现象就称为“梯度消失(Vanishing Gradients)”
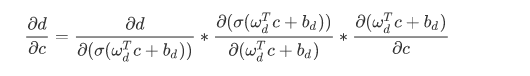
8.2 饱和神经元(Saturated Neurons)
饱和神经元会使得梯度消失问题雪上加霜,假设神经元输入Sigmoid的值特别大或特别小,对应的梯度约等于0,即使从上一步传导来的梯度较大,该神经元权重(w)和偏置(bias)的梯度也会趋近于0,导致参数无法得到有效更新。
9. ReLU 和神经元“死亡”(dying ReLU problem)
9.1 ReLU可以解决梯度消失问题
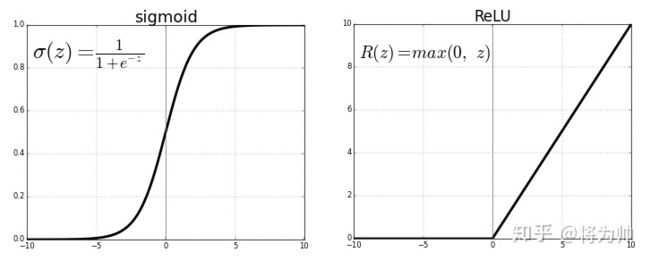
ReLU激活函数的提出就是为了解决梯度消失问题,LSTMs也可用于解决梯度消失问题(但仅限于RNN模型)。ReLU的梯度只可以取两个值:0或1,当输入小于0时,梯度为0;当输入大于0时,梯度为1。好处就是:ReLU的梯度的连乘不会收敛到0 ,连乘的结果也只可以取两个值:0或1 ,如果值为1 ,梯度保持值不变进行前向传播;如果值为0 ,梯度从该位置停止前向传播。Sigmoid和ReLU函数对比如下:
9.2 单侧饱和
Simoid函数是双侧饱和的,意思是朝着正负两个方向,函数值都会饱和;但ReLU函数是单侧饱和的,意思是只有朝着负方向,函数值才会饱和。严格意义上来说,将ReLU函数值为0的部分称作饱和是不正确的(饱和应该是取值趋近于0),但效果和饱和是一样的。单侧饱和有什么好处?
让我们把神经元想象为检测某种特定特征的开关,高层神经元负责检测高级的/抽象的特征(有着更丰富的语义信息),例如眼睛或者轮胎;低层神经元负责检测低级的/具象的特征,例如曲线或者边缘。当开关处于开启状态,说明在输入范围内检测到了对应的特征,且正值越大代表特征越明显。加入某个神经元负责检测边缘,则正值越大代表边缘区分越明显(sharp)。那么负值越小代表什么意思呢?直觉上来说,用负值代表检测特征的缺失是合理的,但用负值的大小代表缺失的程度就不太合理,难道缺失也有程度吗?
假设一个负责检测边缘的神经元,激活值为10相对于激活值为5来说,检测到的边缘区分地更明显;但激活值-10相对于-5来说就没有意义了,因为低于0的激活值都代表没有检测到边缘。所以用一个常量值0来表示检测不到特征是更方便合理的,像ReLU这样单侧饱和的神经元就满足要求。
单侧饱和还能使得神经元对于噪声干扰更具鲁棒性。假设一个双侧都不饱和的神经元,正侧的不饱和导致神经元正值的取值各不相同,这是我们所希望的,因为正值的大小代表了检测特征信号的强弱。但负值的大小引入了背景噪声或者其他特征的信息,这会给后续的神经元带来无用的干扰信息;且可能导致神经元之间的相关性,相关性(重复信息)是我们所不希望的。例如检测直线的神经元和检测曲线的神经元可能有负相关性。在负值区域单侧饱和的神经元则不会有上述问题,噪声的程度大小被饱和区域都截断为0,避免了无用信息的干扰。
使用ReLU激活函数在计算上也是高效的。相对于Sigmoid函数梯度的计算,ReLU函数梯度取值只有0或1。且ReLU将负值截断为0 ,为网络引入了稀疏性,进一步提升了计算高效性。
9.3 神经元“死亡”(dying ReLU problem)
但ReLU也有缺点,尽管稀疏性可以提升计算高效性,但同样可能阻碍训练过程。通常,激活函数的输入值有一项偏置项(bias),假设bias变得太小,以至于输入激活函数的值总是负的,那么反向传播过程经过该处的梯度恒为0,对应的权重和偏置参数此次无法得到更新。如果对于所有的样本输入,该激活函数的输入都是负的,那么该神经元再也无法学习,称为神经元”死亡“问题。
9.4 梯度更新方向的锯齿路径
无论ReLU的输入值是什么范围,输出值总是非负的,这也是一个缺点。采用ReLU激活函数的网络第n层的激活值的表达式为:
![]()
损失函数相对于参数的梯度表达式为:
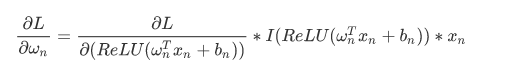
其中第二项指示函数(指示函数输入大于0,输出为1;否则,输出为0)。第三项是该层的输入(即上一层ReLU的输出),值范围是非负的。所以对于该层所有的w参数,梯度的符号都是一样的。这会带来什么问题?梯度的符号决定了参数的更新方向,因为该层所有w参数的梯度符号相同,所以在一次更新中,该层的w参数要么一起增大,要么一起减小。但理想的参数的更新情况可能是:一次更新时,该层一部分w参数增大,而另一部分w参数减小。使用ReLU无法做到。
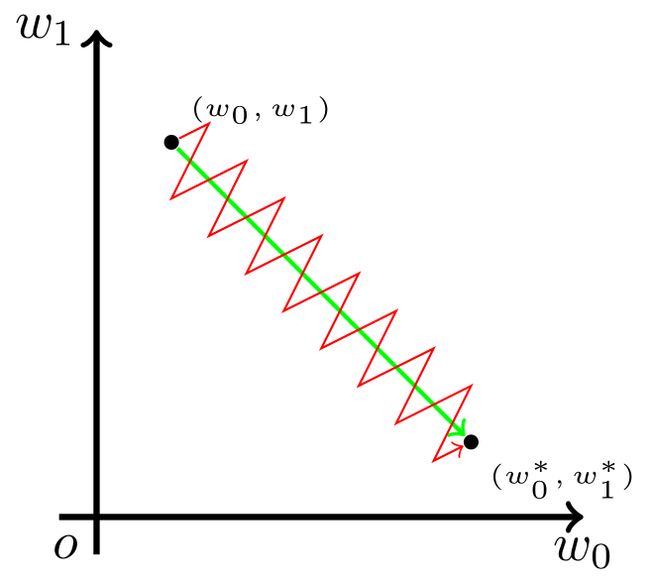
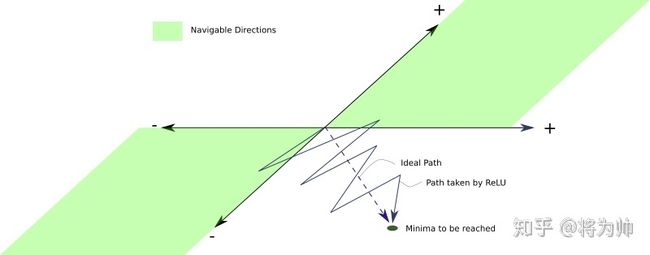
假设训练过程中的某一时刻:一部分参数w1需要减小,以到达理想的参数范围内;而另一部分参数w2却需要增大。然而此次迭代计算得到的梯度符号一致,参数更新后都将减小(满足w1不满足w2);下次迭代时,计算得到的梯度符号仍然一致但方向相反,参数更新后都将增大(满足w2不满足w1)。这将导致参数更新过程中,方向的锯齿问题,以下图理解更直观:从原地到达最优点,一部分参数需要减小(w1,以y轴表示),另一部分参数需要增大(w2,以x轴表示),但每次更新时,w1/w2 必须同时增大或减小,造成了更新方向的锯齿问题,减缓了训练过程。
10. LeakyReLU和PReLU
10.1 LeakyReLU可以解决神经元”死亡“问题
LeakyReLU的提出就是为了解决神经元”死亡“问题,LeakyReLU与ReLU很相似,仅在输入小于0的部分有差别,ReLU输入小于0的部分值都为0,而LeakyReLU输入小于0的部分,值为负,且有微小的梯度。函数图像如下图:
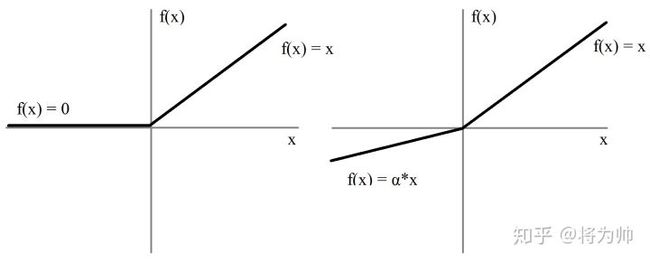
实际中,LeakyReLU的α取值一般为0.01。使用LeakyReLU的好处就是:在反向传播过程中,对于LeakyReLU激活函数输入小于零的部分,也可以计算得到梯度(而不是像ReLU一样值为0),这样就避免了上述梯度方向锯齿问题。
超参数α的取值也已经被很多实验研究过,有一种取值方法是 对α随机取值,α的分布满足均值为0,标准差为1的正态分布,该方法叫做随机LeakyReLU(Randomized LeakyReLU)。原论文指出随机LeakyReLU相比LeakyReLU能得更好的结果,且给出了参数α的经验值1/5.5(好于0.01)。至于为什么随机LeakyReLU能取得更好的结果,解释之一就是随机LeakyReLU小于0部分的随机梯度,为优化方法引入了随机性,这些随机噪声可以帮助参数取值跳出局部最优和鞍点,这部分内容可能需要一整篇文章来阐述。正是由于α的取值至关重要,人们不满足与随机取样α,有论文将α作为了需要学习的参数,该激活函数为PReLU(Parametrized ReLU)。
11. 集大成者ELU(Exponential Linear Unit)
通过上述的讨论可以看出,理想的激活函数应满足两个条件:
- 输出的分布是零均值的,可以加快训练速度。
- 激活函数是单侧饱和的,可以更好的收敛。
LeakyReLU和PReLU满足第1个条件,不满足第2个条件;而ReLU满足第2个条件,不满足第1个条件。两个条件都满足的激活函数为ELU(Exponential Linear Unit),函数图像如下图:
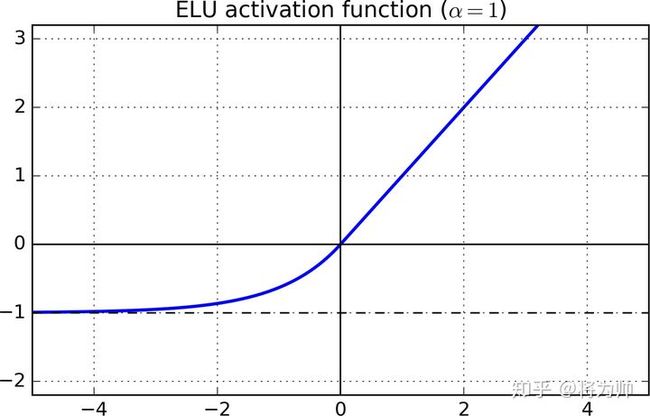
表达式为:
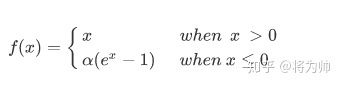
输入大于0部分的梯度为1,输入小于0的部分无限趋近于-α,超参数取值一般为1.
12. 如何选择合适的激活函数?
- 先试试ReLU的效果如何。尽管我们指出了ReLU的一些缺点,但很多人使用ReLU取得了很好的效果。根据”奥卡姆剃刀原理“,如无必要,勿增实体,也就是优先选择最简单的。ReLU相较于其他激活函数,有着最低的计算代价和最简单的代码实现。
- 如果ReLU效果不太理想,下一个建议是试试LeakyReLU或ELU。经验来看:有能力生成零均值分布的激活函数,相较于其他激活函数更优。需要注意的是使用ELU的神经网络训练和推理都会更慢一些,因为需要更复杂的指数运算得到函数激活值,如果计算资源不成问题,且网络并不十分巨大,可以事实ELU;否则,最好选用LeakyReLU。LReLU和ELU都增加了需要调试的超参数。
- 如果有很多算力或时间,可以试着对比下包括随机ReLU和PReLU在内的所有激活函数的性能。当网络表现出过拟合时,随机ReLU可能会有帮助。而对PReLU来说,因为增加了需要学习的参数,当且仅当有很多训练数据时才可以试试PReLU的效果。