神经网络 激活函数小结.2022.01
神经网络激活函数小结.2022.01
- Sigmoid函数
- H-Sigmoid函数
- Tanh函数
- ReLu函数
- Softplus函数
- Leaky ReLu函数
- PReLu(Parametric)函数
- Randomized Leaky ReLu函数
- ELU(Exponential Linear Units)函数
- ReLu6函数
- Swish函数(SiLU)
- H-Swish函数
- Mish函数
- 高斯误差线性单元(GELUs)
- Maxout函数
- FReLU函数
- AconC函数
-
- Meta-ACON
禁止转载!!!
一般激活函数有如下一些性质:
-
非线性
当激活函数是线性的,一个两层的神经网络就可以基本上逼近所有的函数。但如果激活函数是恒等激活函数的时候,即f(x)=x,就不满足这个性质,而且如果MLP使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的; -
可微性
当优化方法是基于梯度的时候,就体现了该性质; -
单调性
当激活函数是单调的时候,单层网络能够保证是凸函数; -
f(x)≈x
当激活函数满足这个性质的时候,如果参数的初始化是随机的较小值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要详细地去设置初始值; -
输出值的范围
当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的Learning Rate
现在介绍一下当前的激活函数:
Sigmoid函数
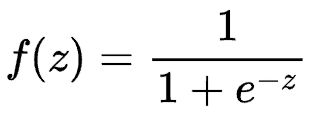
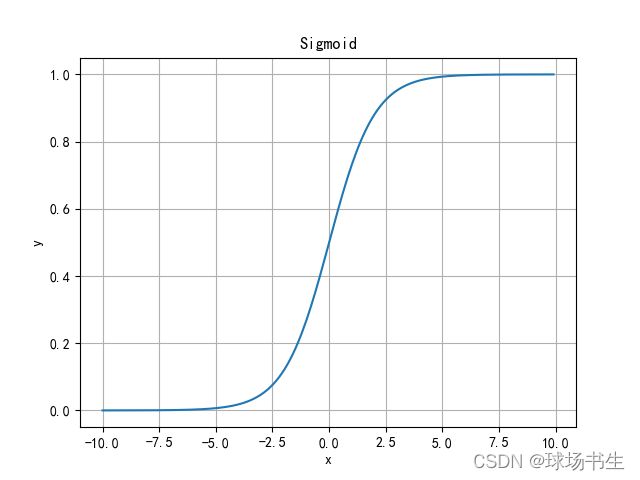
特点:它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。
缺点:在深度神经网络中梯度反向传递时导致梯度消失。Sigmoid 的输出不是0均值(即zero-centered),这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。其解析式中含有幂运算,会增加训练时间。
H-Sigmoid函数
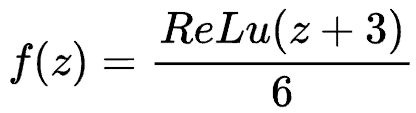
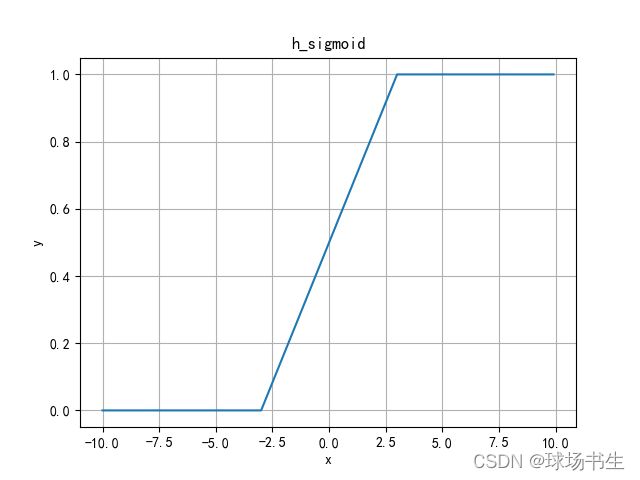
由于sigmoid函数的指数计算,特别耗时,使用ReLU6*(x+3)/6来近似替代。
Tanh函数
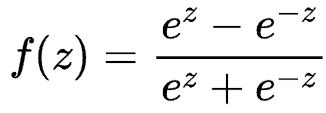

解决了Sigmoid函数的不以0为中心输出问题,然而,梯度消失的问题和幂运算的问题仍然存在。
ReLu函数

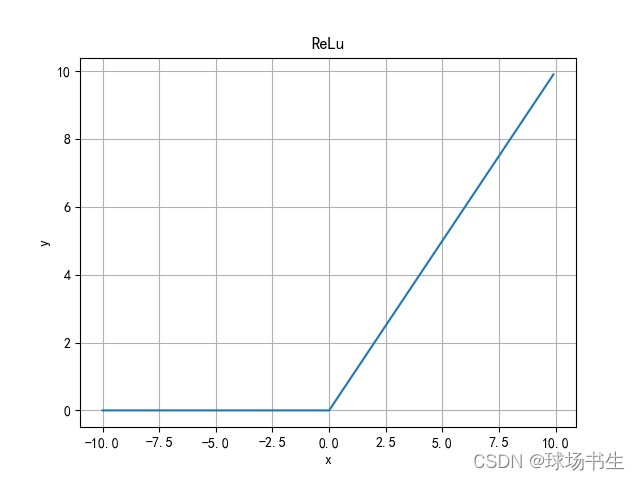
优点:当输入为正时,不存在梯度饱和问题。计算速度快得多。
缺点:神经元失活问题,当输入为负时,ReLU完全失效,在反向传播过程中,如果输入负数,则梯度将完全为零。ReLU函数也不是以0为中心的函数。正向输出为无穷大。函数求导不连续。
Softplus函数
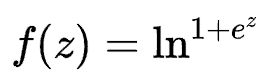
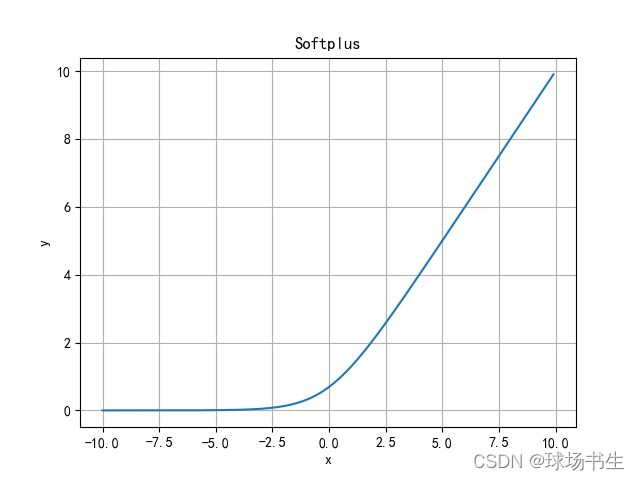
Softplus函数可以看作是ReLU函数的平滑。
Leaky ReLu函数
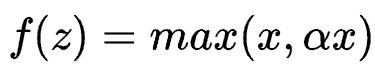
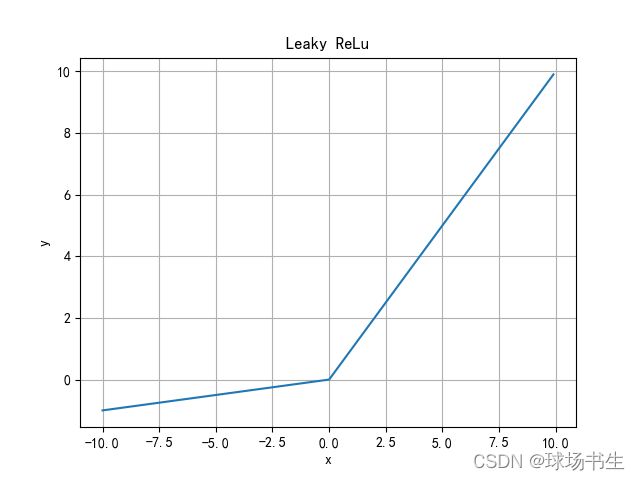
Leaky ReLU函数通过把非常小的线性分量给予负输入来调整负值的零梯度(神经元失活)问题。有助于扩大ReLU函数的范围,通常α的值为0.01左右。但,正向输出仍为无穷大。函数求导不连续。
PReLu(Parametric)函数

α可以学习
Randomized Leaky ReLu函数
Randomized Leaky ReLU 是 Leaky ReLU 的随机版本(α 是随机选取)。它首次是在NDSB 比赛中被提出。核心思想就是,在训练过程中,α是从一个高斯分布N中随机出来的,然后再测试过程中进行修正(与Dropout的用法相似)。在测试阶段,把训练过程中所有的αi取个平均值。NDSB冠军的α是从 N(3,8) 中随机出来的。
ELU(Exponential Linear Units)函数
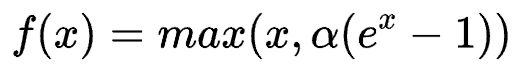
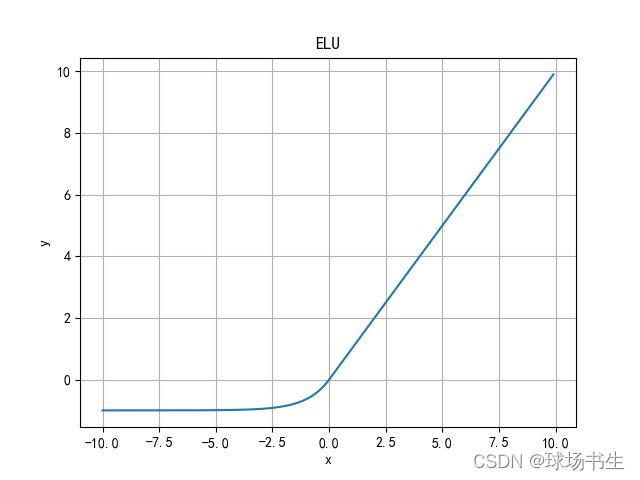
ELU函数的计算强度更高。与Leaky ReLU类似,尽管理论上比ReLU要好,但目前在实践中没有充分的证据表明ELU总是比ReLU好。
ReLu6函数
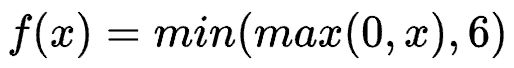
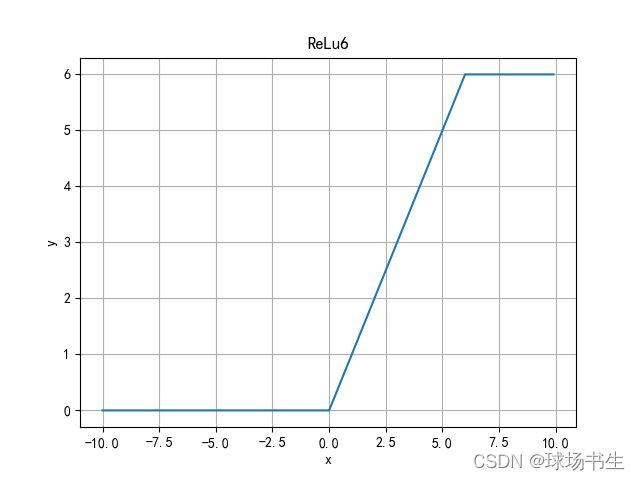
把最大值限制在6,解决ReLu正向输出为无穷大。
Swish函数(SiLU)
Sigmoid Weighted Liner Unit(SiLU)
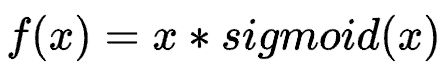
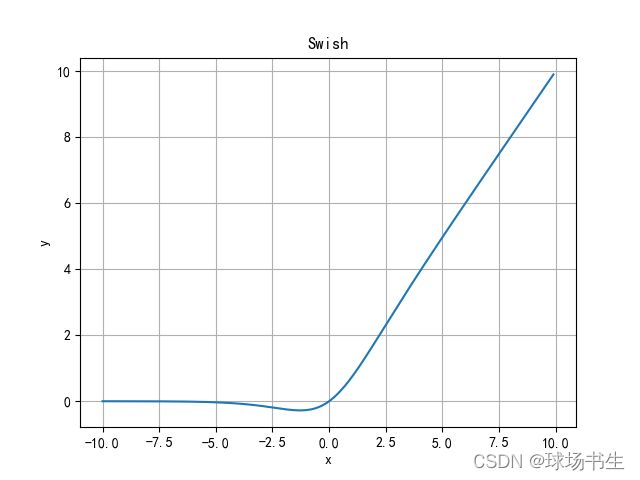
Swish 的设计受到了gating的sigmoid函数使用的启发。这里的sigmoid作为自控门。
H-Swish函数
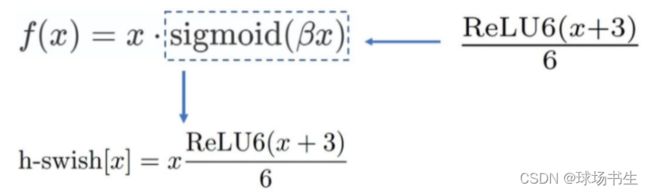

H-Swish作为用于轻量化网络的激活函数,出现于谷歌发表的ICCV 2019的MobileNet V3中 。在Swish函数中,由于sigmoid函数的指数计算,特别耗时,不适用于部署在移动端的网络。作者使用ReLU6*(x+3)/6来近似替代sigmoid,并命名为h-sigmoid。
Mish函数

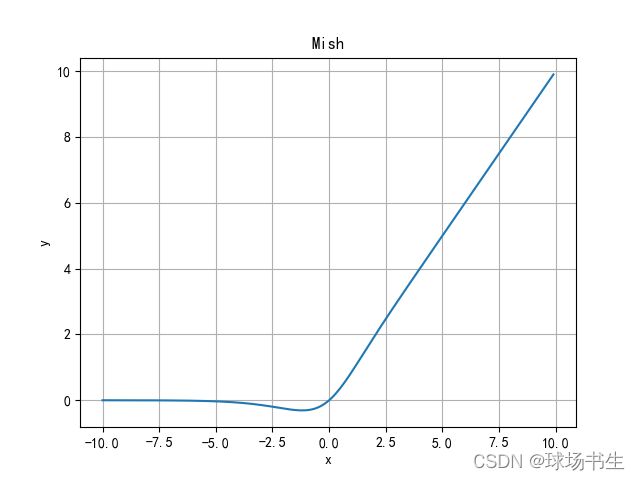
- 无上界有下界:无上界是任何激活函数都需要的特性,因为它避免了导致训练速度急剧下降的梯度饱和。因此,加快训练过程。有下界属性有助于实现强正则化效果(适当的拟合模型)。(Mish的这个性质类似于ReLU和Swish的性质,其范围是[≈0.31,∞))。
- 非单调函数:这种性质有助于保持小的负值,从而稳定网络梯度流。大多数常用的激活函数,不能保持负值,因此大多数神经元没有得到更新。
- 无穷阶连续性和光滑性:Mish是光滑函数,具有较好的泛化能力和结果的有效优化能力,可以提高结果的质量。然而,Swish和Mish,宏观上或多或少还是相似的。

class Mish(nn.Module):
@staticmethod
def forward(x):
return x * F.softplus(x).tanh()
class MemoryEfficientMish(nn.Module):
class F(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
sx = torch.sigmoid(x)
fx = F.softplus(x).tanh()
return grad_output * (fx + x * sx * (1 - fx * fx))
def forward(self, x):
return self.F.apply(x)
高斯误差线性单元(GELUs)

模型很重要的性质就是非线性,同时为了模型泛化能力,需要加入随机正则,例如dropout(其实也是一种变相的随机非线性激活)。
高斯误差线性单元GELU正是在激活中引入了随机正则的思想,是一种对神经元输入的概率描述。高斯分布的累计分布函数说人话就是对高斯函数从左到右积分,会得到一个S形曲线。
 高斯误差线性单元激活函数在最近的Transformer模型,包括谷歌的BERT和OpenAI 的GPT-2中得到了应用。
高斯误差线性单元激活函数在最近的Transformer模型,包括谷歌的BERT和OpenAI 的GPT-2中得到了应用。
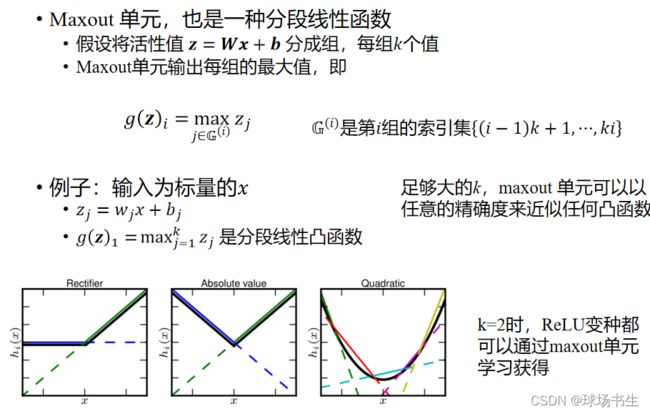
Maxout函数
Maxout函数来源于ICML上的一篇文献《Maxout Networks》,它可以理解为是神经网络中的一层网络,类似于池化层、卷积层一样。我们也可以把Maxout函数看成是网络的激活函数层。中心思想就是利用线性函数分段拟合出不同的函数。
FReLU函数
ECCV2020旷视提出一种新的激活函数,实现像素级空间信息建模。

使用深度可分离卷积 DepthWise Separable Conv + BN 实现T(x)
class FReLU(nn.Module):
def __init__(self, c1, k=3): # ch_in, kernel
super().__init__()
self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
self.bn = nn.BatchNorm2d(c1)
def forward(self, x):
return torch.max(x, self.bn(self.conv(x)))

AconC函数
ACON(Activate Or Not)激活函数。
我们常用的ReLU激活函数本质是一个MAX函数,而MAX函数的平滑,可微分变体我们称为Smooth Maximum。

β是一个平滑因子,当 趋近于无穷大时,Smooth Maximum就变为标准的MAX函数,而当β为0时,Smooth Maximum就是一个算术平均的操作

Swish激活函数是ReLU函数的一种平滑近似,称其为ACON-A。平滑形式可以推广到ReLU激活函数家族里(PReLU,Leaky-ReLU), ACON-B的变体。

最后提出最广泛的一种形式ACON-C,即它能涵盖之前的,甚至是更复杂的形式,在代码实现中,p1和p2使用的是两个可学习参数来自适应调整。
![]()
Meta-ACON
前面提到,ACON系列的激活函数通过β的值来控制是否激活神经元( β为0,即不激活)。因此我们需要为ACON设计一个计算β的自适应函数。而自适应函数的设计空间包含了layer-wise,channel-wise,pixel-wise这三种空间,分别对应的是层,通道,像素。
class AconC(nn.Module):
r""" ACON activation (activate or not).
AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
according to "Activate or Not: Learning Customized Activation" .
"""
def __init__(self, c1):
super().__init__()
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.beta = nn.Parameter(torch.ones(1, c1, 1, 1))
def forward(self, x):
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(self.beta * dpx) + self.p2 * x
class MetaAconC(nn.Module):
r""" ACON activation (activate or not).
MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network
according to "Activate or Not: Learning Customized Activation" .
"""
def __init__(self, c1, k=1, s=1, r=16): # ch_in, kernel, stride, r
super().__init__()
c2 = max(r, c1 // r)
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.fc1 = nn.Conv2d(c1, c2, k, s, bias=True)
self.fc2 = nn.Conv2d(c2, c1, k, s, bias=True)
# self.bn1 = nn.BatchNorm2d(c2)
# self.bn2 = nn.BatchNorm2d(c1)
def forward(self, x):
y = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
# batch-size 1 bug/instabilities https://github.com/ultralytics/yolov5/issues/2891
# beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(y))))) # bug/unstable
beta = torch.sigmoid(self.fc2(self.fc1(y))) # bug patch BN layers removed
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(beta * dpx) + self.p2 * x
这有论文附带的代码