机器学习一些必须库的功能简介
1、Numpy—基础科学计算库 主要功能:高维数组(array)计算、线性代数计算、傅里叶代数计算、傅里叶变换以及生产伪随机数等。Numpy对于scikit-learn来说是至关重要的。"}]
import numpy
#给变量i赋值为一个数组
i=numpy.array([[520,13,14],[25,9,178]])
#将i打印出来
print("i:\n{}".format(i))
2、Scipy—强大的科学计算工具集 主要功能:计算统计学分布、信号处理、计算线性代数方程等,其中用得最多的就是Scipy中的sparse函数。sparse函数用来生成稀疏矩阵。"}]
import numpy as np
from scipy import sparse
matrix=np.eye(6)
#上面用numpy的eye函数生成一个6行6列的对角矩阵
#矩阵中的对角线上的元素数值为1,其余都是0
sparse_matrix=sparse.csr_matrix(matrix)
#这一行把np数组转化为CSR格式的Scipy稀疏矩阵( sparse matrix)
#sparse 函数只会存储非0元素
print("对角矩阵:\n{}".format(matrix))
#将生成的对角矩阵打印出来
print("\nsparse存储的矩阵:\n{}".format(sparse_matrix))
#将sparse 函数生成的矩阵打印出来进行对比
3、pandas—数据分析的利器 pandas是用于进行数据分析的库,可以生成类似Excel表格式的数据表。可以从不同类的数据库提取数据,如SQL数据库、Excel表格甚至CSV文件。还可以在不同的列中使用不同类型的数据,如整数、浮点数、或是字符串。"}]
import pandas
#创建一个同学个人信息的数据集
data={"Name":["小钱","小于","小张","小韩"],
"City":["北京","上海","广州","深圳"],
"Age":["12","13","14","15"],
"Height":["145","146","147","148"]}
data_frame=pandas.DataFrame(data)
display(data_frame)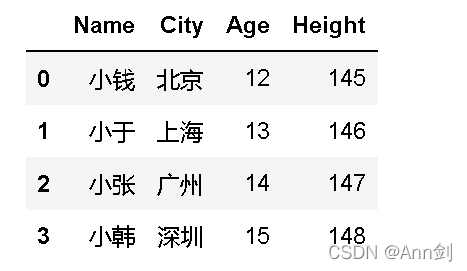
import pandas
#创建一个同学个人信息的数据集
data={"Name":["小钱","小于","小张","小韩"],
"City":["北京","上海","广州","深圳"],
"Age":["12","13","14","15"],
"Height":["145","146","147","148"]}
data_frame=pandas.DataFrame(data)
#显示不在北京的同学
display(data_frame[data_frame.City !="北京"])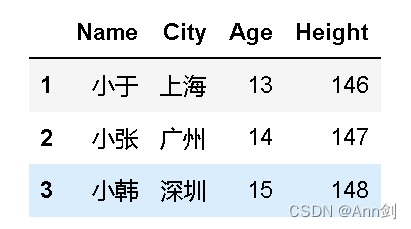
4、matplotlib—画出优美的图形
可以以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形,输出的图形包括折线图、散点图、直方图等。%matplotlib inline
#激活matplotlib
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
plt.figure(dpi=200)
import numpy as np
#下面先生成个从-20到20,元素数为10的等差数列
x =np.linspace(-20,20,10)
#再令y=x^3 + 2x^2 + 6x + 5
y = x**3 + 2*x**2 + 6*x + 5
#下面画出这条函数的曲线
plt.plot(x,y,marker="1")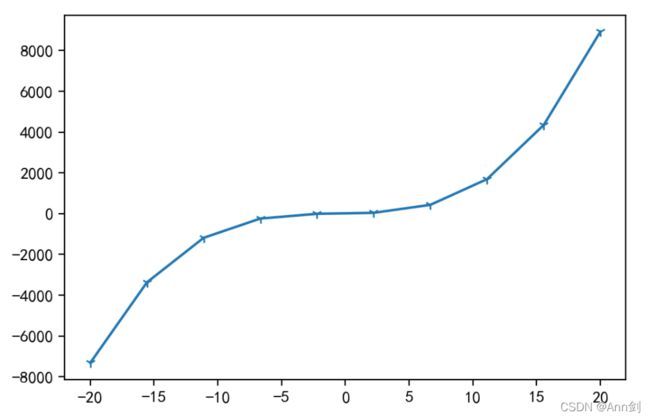
5、scikit-learn—非常流行的Python机器学习库
scikit-learn是一个建立在Scipy基础上的用于机器学习的Python模块,scikit-learn包含众多顶级机器学习算法,主要有六类的基本功能,分别是分类、回归、聚类、数据降维、模型选择和数据预处理