VAE for 文本生成
VAE详解:https://spaces.ac.cn/archives/5253
变分自编码器(Variational auto-encoder,VAE)是一类重要的生成模型(generative model),它于2013年由Diederik P.Kingma和Max Welling提出[1]。2016年Carl Doersch写了一篇VAEs的tutorial[2],对VAEs做了更详细的介绍,比文献[1]更易懂。
VAE的总体目标和GAN基本一致,都是希望通过构建一个从隐变量Z生成目标数据X的模型,他们假设Z服从某种常见分布(比如正态分布),然后训练一个模型X=g(Z),这个模型能够将原来的概率分布映射到训练集的概率分布,这样我们就通过这边模型生成与符合训练数据概率分布的新的数据了。
与自编码对比:
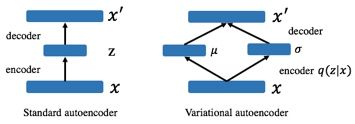
自编码通过编码器将输入x进行编码成z,然后通过解码器将z解码成x`,使得x`与x一样。缺陷:1.需要有原始输入,是有监督的;2.生成的结果是使得x`与原始输入一样,不能泛化生成多样的结果。3.主要用于获取输入的隐藏表示。
变分自编码结构与自编码类似,也是由编码器和解码器构成,不同的是在编码的目标是生成一个概率分布 q(z|x)代替确定性z来重建输入,强制模型将输入映射到空间的区域而不是单个点,。在这种情况下,实现良好重构误差的最直接方法是预测非常潜在的概率分布,有效地对应于潜在空间中的单个点(Raiko等人2014)。引入 KL divergence 让后验 q(z|x) 接近先验 p(z).
VAE在文本生成领域的应用:
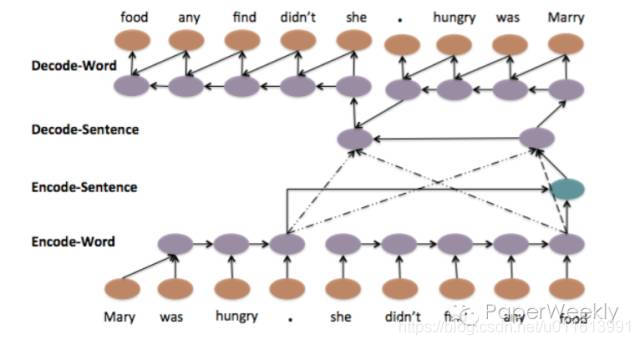
【 A Hierarchical Neural Autoencoder for Paragraphs and Documents】- ACL 2015
理解可参考博文: https://mp.weixin.qq.com/s/TsCnPxcVI0BTRcQClqDiCA
实质:以自编码框架为基础,通过分层编码和解码的方式将词与句子信息综合考虑。如下图,虚线部分为attention
【 Generating Sentences from a Continuous Space】-第20届计算自然语言学习大会 2016
参考博文: https://blog.csdn.net/lrt366/article/details/89388171
作者为了弥补传统的 RNNLM 结构缺少的一些全局特征(其实可以理解为想要 sentence representation)。其实抛开 generative model,之前也有一些比较成功的 non-generative 的方法,比如 sequence autoencoders[1],skip-thought[2] 和 paragraph vector[3]。但随着 VAE 的加入,generative model 也开始在文本上有更多 的可能性。
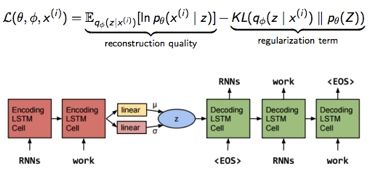
Loss 的组成还是和 VAE 一样。具体模型上,encoder 和 decoder 都采用单层的 LSTM,decoder 可以看做是特殊的 RNNLM,其 initial state 是这个 hidden code z(latent variable),z 采样自 Gaussian 分布 G,G 的参数由 encoder 后面加的一层 linear layer 得到。这里的 z 就是作者想要的 global latent sentence representation,被赋予了先验diagonal Gaussians,同时 G 就是学到的后验。
模型很简单,但实际训练时有一个很严重的问题:KL 会迅速降到0,后验失效了。原因在于,由于 RNN-based 的 decoder 有着非常强的 modeling power,直接导致即使依赖很少的 history 信息也可以让 reconstruction errors 降得很低,换句话说,decoder 不依赖 encoder 提供的这个 z 了,模型等同于退化成 RNNLM 。
这篇 paper 提出的解决方法:KL cost annealing 和 Word dropout。
1) KL cost annealing
![]()
作者引入一个权重 w 来控制这个 KL 项,并让 w 从 0 开始随着训练逐渐慢慢增大。作者的意思是一开始让模型学会 encode 更多信息到 z 里,然后随着 w 增大再 smooth encodings。其实从工程/代码的角度看,因为 KL 这项更容易降低,模型会优先去优化 KL,于是 KL 很快就降成 0。但如果我们乘以一开始很小的 w,模型就会选择忽视 KL(这项整体很小不用降低了),选择优先去降低 reconstruction errors。当 w 慢慢增大,模型也慢慢开始关注降低 KL 这项了。这个技巧在调参中其实也非常实用。 KL项退火可以看作是从传统确定性自动编码器到完整VAE的逐步过渡。
2) Word dropout
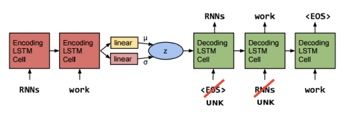
既然问题是 RNN-based 的 decoder 能力太强,那我们就来弱化它好了。具体方法是把 input 的词替换成 UNK(我可能是个假的 decoder),模型被迫只能去多多依赖 z。当然保留多少 input 也需要尝试,我们把全都不保留的叫做inputless decoder,实验表明,inputless VAE 比起 inputless RNN language model 不知道好到哪里去了。
受到 GAN 的启发,作者还提出了一个 Adversarial evaluation,用一半真一半假的数据作为样本训练出一个分类器,再对比不同模型生成的句子有多少能骗过这个分类器,这个 evaluation 被用在 Imputing missing words 这个任务上,VAE 的表现同样比 RNNLM 出色。
最后,作者展示模型的确学到了平滑的 sentence representation。选取两个sentence 的code z1和z2,z1 和 z2 可以看做向量空间的两个点,这两个点连线之间的点对应的句子也都符合语法且 high-level 的信息也保持局部一致。
【 A Hybrid Convolutional Variational Autoencoder for Text Generation 】- EMNLP 2017
参考博文: https://blog.csdn.net/msi_user/article/details/103434786?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
与以前引入的文本 vae 模型相比, 编码器和解码器都是 rnn 的 vae 模型, 我们提出了一种新的混合体系结构, 将完全前馈卷积和去卷积组件与重复语言模型融合在一起。我们的体系结构具有几个有吸引力的特性, 如更快的运行时间和收敛性, 能够更好地处理长序列, 更重要的是, 它有助于避免在文本数据上训练 vae 模型所带来的一些主要困难。
训练VAE模型的核心困难是潜在损失(以KL散度项表示)崩溃为零。 在这种情况下,生成器倾向于完全忽略潜在表示,而简化为标准语言模型。 这主要是由于基于RNN的解码器具有很高的建模能力,其历史记录非常短,可以在不依赖编码器提供的潜矢量的情况下实现较低的重构误差。
在本文中,我们提出了一种新颖的文本VAE模型,该模型可以更有效地迫使解码器使用潜在矢量。与既有编码器层又有解码器层均为LSTM的现有工作相反,我们模型的核心是由一维卷积和反卷积层组成的前馈体系结构(Zeiler等,2010)。这种架构选择有助于更好地控制KL术语,这对于训练VAE模型至关重要。鉴于很难以完全前馈的方式生成长序列,我们在网络上增加了RNN语言模型层。据我们所知,本文是在自然文本的潜在变量生成模型的解码器中成功应用反卷积的第一篇论文。我们凭经验证明,与完全循环的替代方法相比,我们的模型更易于训练,而在我们的实验中,该方法无法收敛于较长的文本。为了更好地理解为什么很难为文本训练VAE,我们进行了详细的实验,讨论了优化难题,并提出了解决这些难题的有效方法。最后,我们证明从我们的模型中采样可以得出真实的文本。
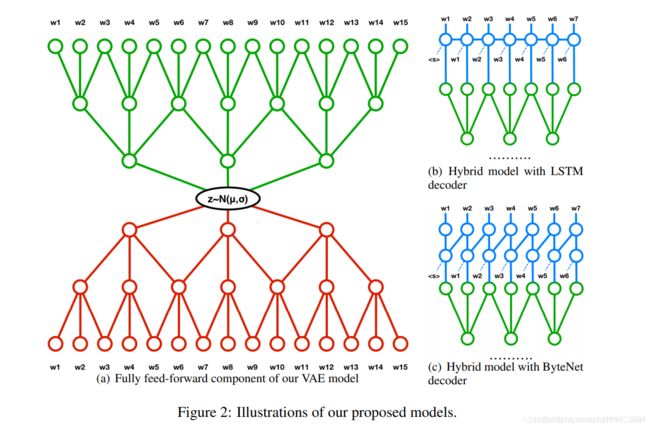
我们的模型由两个相对独立的模块组成。 第一个组件是标准VAE,其中编码器和解码器模块分别由卷积和反卷积层参数化(请参见图2(a))。 这种体系结构因其计算效率高和训练简单而具有吸引力。
另一个组件是循环语言模型,它消耗来自与前一个输出字符连接的反卷积解码器的激活。我们考虑了两种递归函数:传统的LSTM网络(图2(b))和一堆屏蔽卷积,也被Kalchbrenner等人称为ByteNet解码器。 (2016)(图2(c))。在解码器中具有循环组件的主要原因是捕获文本序列元素之间的依赖性,这对于完全前馈架构而言是一项艰巨的任务。实际上,生成的句子的条件分布P(x | z)= P(x1,…,xn | z)不能用前馈网络来丰富地表示。 相反,它的大小为:
![]()
其中组件彼此独立并且仅以z为条件。为了最小化重建成本,模型被迫对文本片段的每个细节进行编码。相反,循环语言模型对输出序列的完整联合分布进行建模,而不必进行独立性假设P(x1,…,xn | z)=
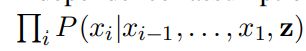
因此,在我们的完全前馈编码器-解码器体系结构之上添加循环层,可以避免将文本片段的各个方面编码为潜在向量,并使其专注于更高级的语义和样式特征。
我们发现以下启发式方法可以很好地起作用:首先运行KL权重固定为0的模型,以找到需要收敛的迭代次数。 然后,我们将退火时间表配置为在非正规模型收敛之后开始,并且持续时间不少于该数量的20%。
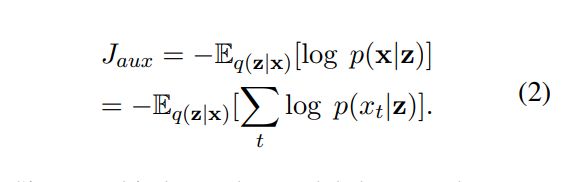
【 Kernelized Bayesian Softmax for Text Generation 】
现有的文本生成神经模型在解码阶段都依赖softmax层来选择合适的单词embedding。现在大多数方法都是在softmax层采取一个单词一一映射一个embedding的方式。然而,同样的单词在不同的上下文会有不同的语义。在本文作者提出了核化贝叶斯方法KerBS,他能够更好的学习文本生成中的embedding。KerBS的优势如下:它采用了embedding的贝叶斯组合来表征具有不同语义的单词;KerBS适用于解决一词多义带来的语义差异问题,并且通过核学习在embedding空间中捕捉语义的紧密程度,KerBS对极少出现的句子也能保持较高的鲁棒性。研究表明,KerBS显著提高几大文本生成任务的性能。
【 Topic-Guided Variational Auto-Encoder for Text Generation】- NAACL 2019
参考博文: https://blog.csdn.net/Forlogen/article/details/102815558
本文提出了一种基于主题指导的VAE模型(topic-guided variational autoencoder, TGVAE),它不再是从标准高斯分布中进行采样,而是将每一个主题模块都看作是一个高斯混合模型,即每一个混合成分都表示了一个对应的latent topic。那么直接从中进行采样,decoder在 解码的过程中过程中就会利用到latent code所表示的主题信息。另外,作者还采用了Householder Transformation 操作,使得latent code的近似后验具有较高的灵活性。实验证明TGVAE在无条件文本生成和条件文本生成任务中都可以取得更好的效果,并且模型可以生成不同主题下语义更加丰富的句子。而且通过主题信息的指导,使得模型在文本生成阶段所依赖的词汇表变小,从而减少解码过程的计算量。

【 Towards Generating Long and Coherent Text with Multi-Level Latent Variable Models . 】-ACL 2019
参考博文: https://zhuanlan.zhihu.com/p/86532302
本文利用multi-level structures 学习VAE模型以生成长文本。主要目的是利用长文本的高级抽象特征(如主题、情感等)和低级细粒度细节(如特定的词选择)来做长文本的生成。本文所做的改进:
-
1.在编码器和解码器之间采用了一个随机层结构来抽象出更多的语义丰富的隐含编码
-
2.利用一个多级解码器结构通过生成句子高层次的中间表示来捕获长文本中固有的长期结构
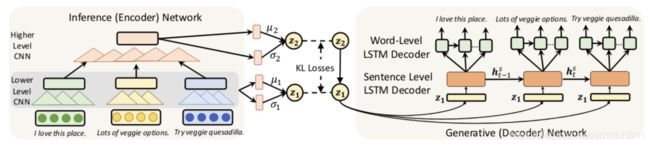
【 Long and Diverse Text Generation with Planning-based Hierarchical Variational Model 】
现有的数据到文本生成的神经方法仍然难以生成长而多样的文本: 它们不足以在生成过程中对输入数据进行动态建模、捕捉句子间的连贯性或生成多样化的表达式 。 为了解决这些问题,我们提出了一种基于规划的层次变分模型(PHVM)。 我们的模型首先规划一个组序列 (每个组是一个句子所涵盖的输入项的子集) ,然后根据规划结果和前面生成的上下文实现每个句子,从而将长文本生成分解为依赖的句子生成子任务。 为了捕获表达的多样性,我们设计了一个层次潜结构,其中全局规划潜变量对合理规划的多样性进行建模,局部潜变量序列控制句子的实现。
给定输入数据x = {d1, d2,…}其中每个di可以是一个属性-值对或一个关键字,我们的任务是生成一个长而多样的文本y = s1 s2…sT (sT是第t个句子)表示尽可能多地表示x。
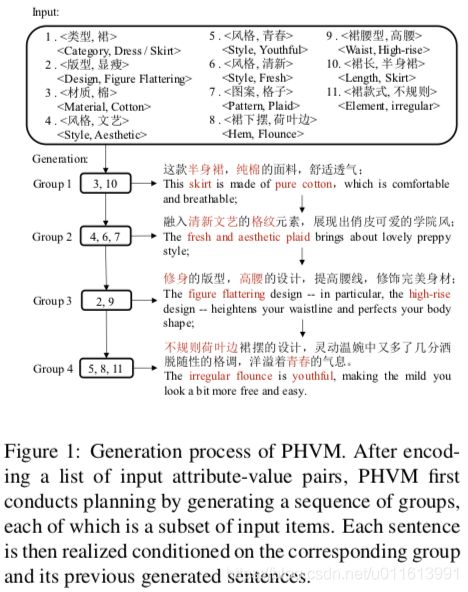
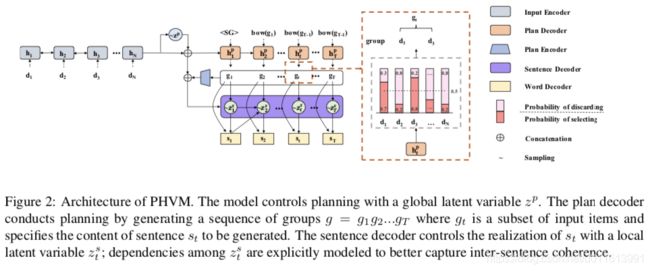
生成过程概述:
1.根据输入生成一组规划,g1,g2,..;gt是输入中的子项
2.结合规划子项,输入编码,生成子句编码
3.结合子项,子句编码进行子句的单词级生成,生成子句si
4.根据时间步,结合上步隐层信息,重复1-3步,生成其余的子句si+1,si+2 …
5.拼接所以子句si-N,形成最终的长句。
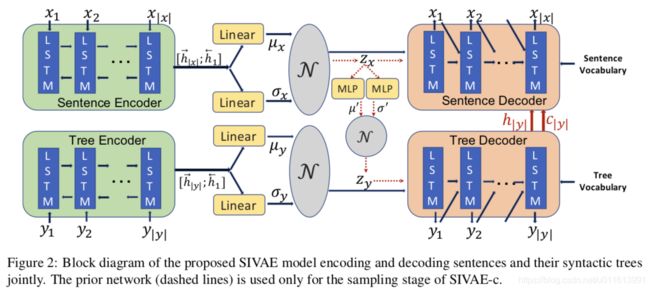
【 Syntax-Infused Variational Autoencoder for Text Generation 】- ACL 2019
博文参考: https://zhuanlan.zhihu.com/p/87355823
Syntax-Infused VAE顾名思义就是结合了语法信息的VAE文本生成,结合输入文本的语法树,可以提升生成句子的语法信息。作者分别为句子和语法树生成了隐变量,并且重写了变分下界的目标函数,以此优化2者的联合分布。