论文笔记(一)3D-R2N2 A Unified Approach for Single and Multi-view 3D Object Reconstruction
发表期刊:ECCV 发表时间:2016
摘要
受最近成功的利用形状先验实现鲁棒3D重构方法的启发,我们提出了一种新的循环神经网络架构,我们称之为3D循环重构神经网络(3D- R2N2)。该网络从大量合成数据中学习物体图像到其底层3D形状的映射。我们的网络从任意视点接收一个或多个对象实例的图像,并以3D占用网格的形式输出对象的重建。与之前的大多数工作不同,我们的网络不需要任何图像注释或对象类标签进行训练或测试。我们广泛的实验分析表明,我们的重建框架优于当前最先进的单视图重建方法,支持在传统SFM/SLAM方法失败(因为缺乏纹理和/或宽基线)的情况下对对象进行3D重建。
关键词:多视角,重构,递归神经网络
介绍
大多数最先进的三维物体重建方法都受到一些限制:
- 物体必须从密集的视图中观察,也就是说视图必须有一个相对较小的基线。
- 对象的外观(或其反射函数)被期望为兰伯(即为非反射),反照率被认为是非均匀的(也就是说丰富的非均匀纹理)。
为了规避与大基线或非兰伯曲面相关的问题,空间雕刻等三维体积重建方法及其概率扩展已成为流行的方法。然而,这些方法都假设物体从背景中被精确地分割出来,或者摄像机被校准过,这在许多应用中都不是这样的。另一种不同的理念是假设关于物体外观和形状的先验知识是可用的。使用先验的好处是,随后的重建方法不太依赖于在视图之间找到准确的特征对应。
本文与上面讨论的方法具有相同的精神,但有一个关键的区别。我们不是在观察物体之前尝试匹配一个合适的3D形状并可能适应它,而是使用深度卷积神经网络从大量训练数据集合中学习从观察到物体的潜在3D形状的映射。在我们的方法中,第一次利用深度神经网络的能力,以端到端方式自动学习从数据中适当的中间表示,以最少的监督从单张图像中恢复近似的3D对象重构。
受长短期记忆(LSTM)网络的成功以及使用卷积神经网络在单视图3D重建方面的最新进展的启发,我们提出了一种新的架构,我们称之为3D复发重建神经网络(3D-R2N2)。该网络从不同的视点接收一个物体实例的一个或多个图像,并以三维占用网格的形式输出该物体的重建。注意,在训练和测试中,我们的网络不需要任何对象类标签或图像注释(即,不需要分割、关键点、视点标签或类标签)。
3D-R2N2的一个关键属性是,它可以通过控制输入门和忘记门来选择性地更新隐藏表示。在训练中,当来自不同视点的信息(可能存在冲突)可用时,该机制允许网络自适应和一致地学习对象的合适3D表示。
文章主要贡献
- 提出了一个标准LSTM框架的扩展,称之为3D循环重建神经网络,它适用于在原则性的方式容纳多视图图像提要。
- 我们在单一框架中统一了单视图和多视图三维重建。
- 我们的方法在训练和测试中需要最少的监督(只需要边界框,但不需要分割、关键点、视角标签、摄像机校准或类别标签)。
- 通过广泛的实验分析表明,我们的重建框架优于最先进的单视图重建方法。
- 我们的网络能够在传统SFM/SLAM方法失败(因为缺乏纹理或宽基线)的情况下对对象进行3D重建。
递归神经网络
长短期记忆(LSTM)单元是RNN隐藏状态最成功的实现之一。LSTM单元显式控制从输入到输出的流,允许网络克服消失梯度问题。
LSTM单元由四个组件组成:
- 存储单元(一个存储单元和一个隐藏状态)
- 控制从输入到隐藏状态的信息流(输入门)
- 从隐藏状态到输出的信息流(输出门)
- 以及从之前的隐藏状态到当前隐藏状态的信息流(忘记门)
在时间步t处,当接收到一个新的输入xt时,LSTM单元的操作可以表示为:
it, ft, ot 分别指输入门、输出门和遗忘门。St和ht分别为存储单元和隐藏状态。我们使用⚪表示基于元素的乘法,下标t表示时刻t的激活。W(·)、U(·)分别是转换当前输入xt和之前隐藏状态ht−1的矩阵,b(·)表示偏差。
门控循环单元(GRU)是LSTM单元的一个变体提出的。与标准LSTM相比,GRU的一个优点是计算量更少。在GRU中,更新门同时控制输入门和忘记门。另一个区别是在非线性转换之前应用了复位门。
ut、rt、ht分别表示更新门、复位门和隐藏状态。
三维循环重建神经网络
该网络由三个部分组成:2D卷积神经网络(2D- cnn)、3D卷积LSTM (3DLSTM)和3D反卷积神经网络(3D- dcnn)。重建。其主要思想是利用LSTM的强大功能来保留以前的观测结果,并随着可用的观测结果的增多而逐步改进输出重构。
给定一个物体的任意视点的一张或多张图像,2D-CNN首先将每个输入图像x编码为低维特征T (x)。然后,给定编码后的输入,一组新提出的3D卷积LSTM (3D-LSTM)单元。要么选择性地更新其单元状态,要么通过关闭输入门保持状态。最后,3D- dcnn解码LSTM单元的隐藏状态,生成3D概率体素重建。使用基于lstm的网络的主要优势来自于当多个视图被馈送到网络时,它能够有效地处理对象自遮挡。网络有选择地更新与对象可见部分对应的内存单元。如果后续视图显示之前自遮挡的部分,且与预测不匹配,网络将更新之前遮挡部分的LSTM状态,但保留其他部分的状态。
3D-R2N2网络结构
编码器:2D-CNN
我们使用CNN将图像编码为特征。我们设计了两个不同的2D-CNN编码器:一个标准的前馈CNN和它的深度残差变化。第一个网络由标准卷积层、池层和泄漏校正线性单元组成,然后是完全连接层。受最近一项研究的启发,我们还创建了第一个由网络的深度残差变化组成。
根据这项研究,在标准卷积层之间添加残差连接可以有效地改善和加速非常深的网络的优化过程。编码器网络的深度残差变异除第4对卷积层外,每2个卷积层后都有恒等映射连接。为了匹配卷积后的通道数量,我们对剩余连接使用1 × 1卷积。然后将编码器输出压平并传递给一个完全连接的层,该层将输出压缩为1024维的特征向量。
循环:3D卷积LSTM
3D-R2N2网络的核心部分是一个循环模块,它允许网络保留它所看到的东西,并在看到新图像时更新内存。一种简单的方法是使用普通的LSTM网络。然而,如果没有任何正则化,预测如此大的输出空间(32 × 32 × 32)将是一项非常困难的任务。我们提出了一种新的架构,称为3D-Convolutional LSTM (3D-LSTM)。该网络由一组连接受限的结构化LSTM单元组成。3D- LSTM单元在空间上分布在3D网格结构中,每个单元负责重建最终输出的特定部分。在3D网格内部,有N个×N ×N 3D- lstm单元,其中N是3D- lstm网格的空间分辨率。每个3D-LSTM单元,索引为(i,j,k),具有独立的隐藏状态ht,(i,j,k)∈RNh。与第2节相同的符号,但ft、it、st、ht作为4D张量(N ×N ×N大小为Nh的向量),控制3D-LSTM网格的方程为:
与标准LSTM不同,3D-LSTM没有输出门,因为只在最后提取输出。通过去除冗余输出门,可以减少参数的数量。
实际上,这种配置迫使3D-LSTM单元处理预测重建的特定区域和地面真相模型之间的不匹配,这样每个单元学习重建体素空间的一部分,而不是贡献整个空间的重建。这种配置也赋予网络一种局部性,这样它就可以有选择地更新它对物体先前被遮挡部分的预测。
此外,三维卷积LSTM单元限制其隐藏状态与空间邻居的连接。对于普通LSTM,隐藏层ht−1中的所有元素都会影响当前隐藏状态ht,而空间结构的3D卷积LSTM只允许其隐藏状态ht,(i,j,k)受所有i,j和k的相邻3D-LSTM单元的影响。更具体地说,相邻连接由卷积核大小定义。例如,使用3 × 3 × 3内核,那么LSTM单元只受其近邻的影响。这样,单元可以共享权重,网络可以进一步规格化。
基于GRU的递归模块可以表示为:
解码器:3D反卷积神经网络
3D- LSTM在接收到输入图像序列x1, x2,····xT后,将隐藏状态hT传递给解码器,解码器通过应用3D卷积、非线性和3D解池来提高隐藏状态分辨率,直到达到目标输出分辨率。
与编码器一样,我们提出了一个具有5个卷积的简单解码器网络和一个具有4个剩余连接和最后一个卷积的深度残差版本。在激活达到目标输出分辨率的最后一层之后,我们使用体素-wise softmax将最终激活V∈RNvox×Nvox×Nvox×2转换为体素单元在(i,j,k)处的占用概率p(i,j,k)
LOSS:3D体素式Softmax
网络的损失函数被定义为体素横向熵的总和。设每个体素(i,j,k)的最终输出满足伯努利分布[1−p(i,j,k), p(i,j,k)],其中对输入X的依赖关系= {xt}t∈{1,…,T},设对应的基础真理占用为y(i,j,k)∈{0,1},则:
实施
数据增强:在训练中,我们使用3D CAD模型生成输入图像和地面真实体素占用图。我们首先使用透明背景渲染CAD模型,然后使用来自PASCAL VOC 2012数据集的随机裁剪来增强输入图像。此外,我们对模型的颜色进行着色,并随机翻译图像。请注意,所有视点都是随机采样的。
训练:在训练网络时,我们使用了从一幅图像到任意数量的图像的可变长度输入。更具体地说,单个小批次中每个训练示例的输入长度(视图数)保持不变,但不同小批次中的训练示例输入长度随机变化。这使得网络能够执行单视图和多视图重建。在训练过程中,为了节省计算能力和内存,我们只在输入序列结束时计算损失。另一方面,在测试期间,我们可以通过提取LSTM单元的隐藏状态来访问每个时间步的中间重建。
网络:输入图像大小设置为127×127。输出体素化重建的大小为32×32×32。实验中使用的网络经过了6万次迭代,批大小为36,除了[Res3D-GRU3],需要24个批大小才能适应NVIDIA Titan X GPU。对于LeakyReLU层,整个网络的泄漏斜率设置为0.1。对于反褶积,我们遵循了中介绍的非冷却方案。我们使用Theano实现网络,并使用Adam实现SGD更新规则
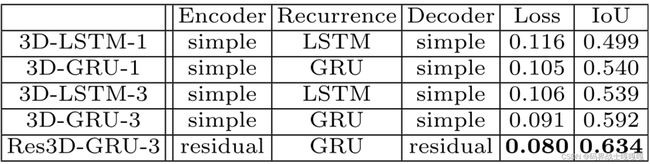
使用5个视图根据交叉熵损失和IoU重建3D-LSTM变化的性能
实验
数据集
ShapeNet:ShapeNet数据集是根据WordNet层次结构组织的3D CAD模型的集合。我们使用了ShapeNet数据集的一个子集,该数据集由50000个模型和13个主要类别组成。我们将数据集分成训练集和测试集,其中4/5 3D-R2N2 9用于训练,其余1/5用于测试。在整个实验部分中,我们将这两个数据集称为ShapeNet训练集和测试集。
PASCAL 3D:PASCAL三维数据集由PASCAL 2012检测图像和3D CAD模型对齐组成。
Online Products:数据集包含23000件在线销售商品的图像。由于基线超宽,MVS和SFM方法在这些图像上失败。由于数据集没有地面真实3D CAD模型,我们仅使用数据集进行定性评估。
MVS CAD Models:为了将我们的方法与多视图立体方法进行比较,我们收集了4种不同类别的高质量CAD模型。所有CAD模型都具有纹理丰富的表面,并放置在纹理丰富的纸张上,以帮助MVS方法的相机定位。
指标:我们在评估重建质量时使用了两个指标。主要度量是三维体素重建与其地面真实体素化模型之间的体素交集(IoU)。I(·)是一个指标函数,t是一个体素化阈值。IoU值越高,表示重建效果越好。我们还将交叉熵损失值为次要度量,较低的损失值表示较高的置信度重建。
网络结构比较
我们测试了3D-R2N2的5种变体,前四个网络是基于标准前馈CNN,第五个网络是残差网络。对于前四个网络使用GRU或LSTM单元,并将卷积核改为1 × 1 × 1 [3D-LSTM/GRU-3]或3 × 3 × 3 [3D-LSTM/GRU-3]。剩余网络使用GRU单元和3 × 3 × 3卷积[Res3D-GRU-3]。
这些网络在ShapeNet训练集上进行训练,并在ShapeNet测试集上进行测试。在实验中使用了5个视图观察到:
- 基于gru的网络优于基于lstm的网络
- 具有相邻循环单元连接(3 × 3 × 3卷积)的网络优于无相邻循环单元连接(1 × 1 × 1卷积)的网络
- 深度残差网络变异进一步提高了重构性能
单个真实世界图像重建
我们利用真实图像评估了网络在单视图重构中的性能,并与Kar等人最近提出的方法进行了性能比较。为了进行定量比较,我们使用了来自PASCAL VOC 2012数据集的图像和来自PASCAL 3D+数据集的相应3D模型。使用与Kar等人相同的配置运行实验,除了我们允许Kar等人的方法具有地面真相对象分割掩码和关键点标签作为额外的输入,用于训练和测试。

结果:
我们的方法在每个类别上都优于Kar的方法。然而我们注意到网络在重建椅子的细腿方面有一些困难。此外,当给显示器正面视图时,网络经常混淆薄平板和厚CRT屏幕。
除了性能更好之外还有几个优点。首先,我们的网络不需要训练和测试每个类别,在不知道对象类别的情况下进行训练和重建。其次,不需要对象分割掩码和关键点标签作为额外的输入。Kar等人通过估计分割和关键点,证明了在野生无标记图像上进行测试的可能性。然而,我们的网络优于他们的方法测试与地面真相标签。

多视点重建评估
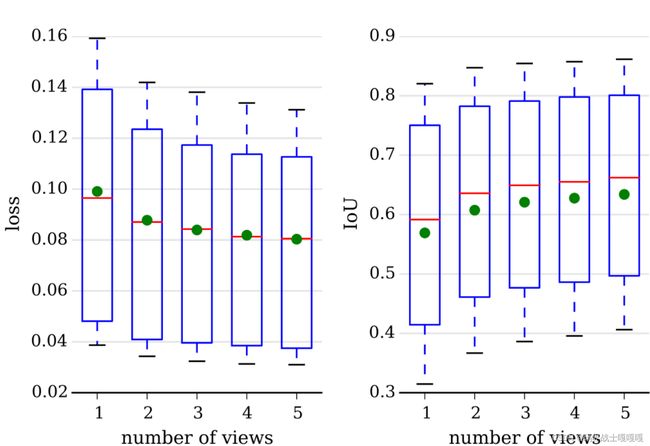
实验设置:在实验中使用了[Res3D-GRU-3]网络和ShapeNet测试集对网络进行了评估。该测试集由13大类8725个模型组成,我们为每个模型渲染了五个随机视图并且图像应用了统一的彩色背景。我们报告了软最大损失和交叉过并(IoU),预测的体素模型和地面真值体素模型之间的体素化阈值为0.4。
总体的结果:我们首先考察了不同浏览量下重构模型的质量。随着视图数量的增加,重构质量有所提高。边际增益减少的事实符合我们的假设,即每增加一个视图提供更少的信息,因为两个随机视图很可能有部分重叠。
重建真实世界的图像
我们在在线产品数据集上测试了网络,以进行定性评估。非方形的图像用白色像素填充。。结果表明,该网络仅使用合成数据作为训练样本就能重构真实世界的对象。它还证明了网络在看到对象的附加视图后改进了重构。一个典型的例子是沙发的重建。最初的沙发侧视图让网络认为这是一个单座沙发,但在看到沙发的正面后,网络立即改进了它的重建,以反映观察结果。类似的行为也出现在其他样本中。

多视点立体(MVS)vs.3D-R2N2
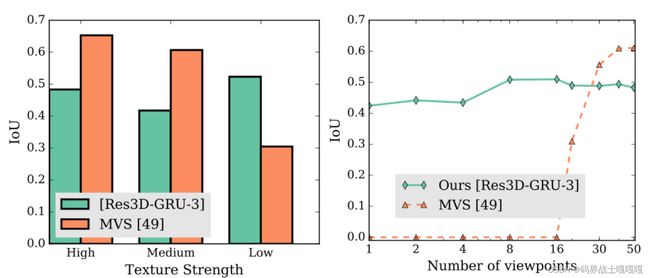
我们比较了3D-R2N2和MVS方法在重建不同纹理级别和不同视图数量的对象上的差异。MVS方法受限于不同视图间特征对应的准确性。因此,他们往往失败重建无纹理的物体或图像从稀疏的位置相机视点。相比之下,3D-R2N2不需要精确的特征对应或相邻的摄像机视点。
实验设置:我们使用基于补丁匹配的现成实例作为MVS方法。MVS方法使用全局SFM估计的图像及其摄像机位置,并输出重建模型。对于3D-R2N2,我们使用最多5个视图训练的[Res3D-GRU-3]网络。为了处理更多的视图,使用样本对3D-R2N2进行了微调,这些样本拥有最多24个视图,使用ShapeNet训练集进行5000次迭代。用体素的IoU来量化重建的质量。网络被体素化,占用概率阈值设置为0.1。将MVS方法重构的网格体素化为32 × 32 × 32的网格进行比较。
结果:我们观察到:
- 我们的模型在只有一个视图的情况下都能正常工作,而MVS方法在视图数小于20 (IoU=0)时完全失败
- 我们的模型无论对象的纹理级别都能正常工作,而MVS方法即使在提供大量视图的情况下也经常无法重构纹理级别较低的对象。这表明3D-R2N2可以在MVS方法执行不佳或完全失败的情况下工作。注意,我们的方法的重构性能在视图数量通过24之后下降。这是因为只在最多24个视图的样本上微调了我们的网络。
我们还发现了3D-R2N2一些局限性。首先,当给出超过30个不同的模型视图时,3D-R2N2不能像MVS方法那样重建那么多的细节。其次,在重构高纹理级别的对象时表现较差。这在很大程度上是因为ShapeNet训练集中的大多数模型都具有较低的纹理级别。
总结
本文提出了一个新颖的架构,将单视图和多视图三维重建统一到一个单一的框架中。3D-R2N2可以接受可变长度的输入并且在使用真实图像的单视图重建方面优于Kar等人的方法。进一步测试了网络在ShapeNet数据集和Online Products数据集上执行多视图重构的能力,结果表明,当网络看到一个对象的更多视图时,它能够逐步改进其重构。最后,分析了该网络在多视图重构中的性能,发现当MVS等技术失败时,3D-R2N2可以产生精确的重构。总之,3D-R2N2不需要最少数量的输入图像来产生合理的重建,并且能够克服过去处理纹理不足或基线视点宽的图像的挑战。
hapeNet数据集和Online Products数据集上执行多视图重构的能力,结果表明,当网络看到一个对象的更多视图时,它能够逐步改进其重构。最后,分析了该网络在多视图重构中的性能,发现当MVS等技术失败时,3D-R2N2可以产生精确的重构。总之,3D-R2N2不需要最少数量的输入图像来产生合理的重建,并且能够克服过去处理纹理不足或基线视点宽的图像的挑战。