模块、包与库
文章目录
-
- 一、模块及其导入方式
- 二、包及其定义
- 三、库的定义
- 四、常用标准库
-
-
- 1.time
- 2.datetime
- 3.copy
- 4.**os**
- 5.sys
- 6.random
- 随机产生四位验证码
- 7.re
- 8.pickle
- 9.Hashlib模块
-
- 相关文章
一、模块及其导入方式
模块:程序的组织形式,将彼此具有特定关系的一组python可执行代码,函数,类或变量组织到独立的文件里,可供其他程序使用。
导入模块的时候加载模块中的所有代码,如果模块中有函数调用的话,也会调用函数。如果不希望被调用就会使用到__name__,如果在自己的模块里,name=main,在其他模块中则为模块名
模块的三种导入方式
(1)import moduleName
(2)from moduleName import *
(3)from moduleName import object1[,object2,…]


我们定义一个calculate.py文件,将它作为一个模块,然后,我们再定义一个模块01文件,在这个文件中,我们可以调用模块(import calculate)
calculate.py文件:
#变量
number=100
name='calculate'
#函数
def add(*args):
if len(args)>1:
sum=0
for i in args:
sum+=i
return sum
else:
print("至少传入两个参数")
return 0
def minus(*args):
if len(args)>1:
m=0
for i in args:
m-=i
return m
else:
print("至少传入两个参数")
return 0
def multiply(*args):
pass
def divide(*args):
pass
#类
class Calculate:
def __init__(self,num):
self.num=num
def test(self):
print("正在使用calculate进行运算...")
@classmethod
def test1(cls):
print("------->calculate中的类方法")
def test():
print("我是测试。。。")
print("__name__",__name__) #在当前文件执行为__main__
#当在模块01.py文件执行则为:calculate
if __name__=='__main__': #在本文件运行,则执行下面代码
print(__name__) #__main__
test()
模块01.py文件:
list1=[4,2,7,8,9]
#导入模块
import calculate
#模块名.函数 模块名.变量 模块名.类
#使用模块的函数
result=calculate.add(*list1)
print(result)
#使用模块的变量
print(calculate.number)
#使用模块中的类
cal=calculate.Calculate(88)
cal.test()
calculate.Calculate.test1()
运行:
__name__ calculate
30
100
正在使用calculate进行运算...
------->calculate中的类方法
模块的循环导入
循环导入:模块之间,你导入我,我导入你,是一种错误的方式,由于
架构不当,会陷入死循环。
A:模块
def test():
f()
B:模块
def f()
test()
避免产生循环导入:
1.重新架构
2.将导入的语句放在函数里
3.将导入语句放到模块最后
文件:循环导入.py
from 循环导入1 import func
def task1():
print("task1")
def task2():
print("task2")
func()
task1()
循环导入1.py
from 循环导入 import task1
def func():
print("——————————循环导入2里面的func------1---")
task1() #Alt+回车导入该模块
print("——————————循环导入2里面的func------2---")
二、包及其定义
__init__文件的主要作用:
(1)作为包和普通目录的区别标识
(2)编写代码,定义类,函数,变量等对象
(3)定义__all__变量来确定采用from moduleName import *导入时,模块的名称
如下图:
我们设置两个文件夹,一个文件夹叫article一个叫user,我们在两个文件夹建立两个__init__文件变成两个包,我们可以知道,两个包中可以有相同名字的模块名。
当导入包,默认执行__init__文件内容


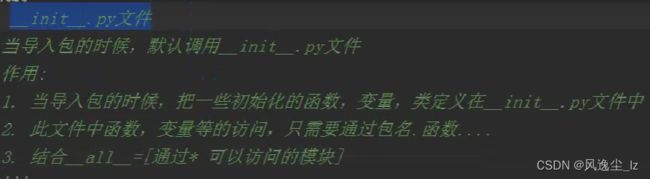
例如:在__init__文件中,定义了变量XX=5,YY=2,
函数Test1,Test2,然后定义了__all __=[‘XX’,‘YY’,‘Test1’],那么在用from moduleName import *时,我们可以使用除了Test2以外的对象,因为Test2未在__all__里面。
注:如果我们在D盘创建一个文件夹bao,里面再新建立一个__init__文件.txt,我们在里面写入love=520,然后这就可以看作是一个简单的包了,我们可以通过如下代码调用变量值
import sys
sys.path.append('d:/') #添加查找路径
import bao
print(bao.love)
如果我们在这个包文件夹,下面定义了除__init__
文件的其他文件others,并且在里面定义了函数Test()等对象。
那么我们通过如下方式调用该对象
import bao.others
print(bao.others.Test()
三、库的定义
- 库:实现某一功能模块和包的集合.
根据是否存在python的官方安装包中区分标准库和第三方库。
四、常用标准库
1.time
time库整理
2.datetime
datetime总结
3.copy
copy深复制、浅复制
4.os
import os
print(os.name) #当前操作系统的名称
print(os.getcwd()) #当前工作目录
print(os.listdir()) #当前工作目录的文件,文件夹
#['.idea', '函数.py', '列表.py', '包.py', '字典.py', '字符串.py', '常用标准库.py']
#os.mkdir('我创建的文件') #创建文件夹
print(os.listdir())
#['.idea', '函数.py', '列表.py', '包.py', '字典.py', '字符串.py', '常用标准库.py', '我创建的文件']
os.chdir('D:\\python') #切换目录
print(os.getcwd())
os.chdir(r'C:\Users\wind.LAPTOP-8EA5MEIP\PycharmProjects\Python基础')
#os.remove("包") #删除文件
print(os.listdir())
#os.rename("包子.py","包.py") #将文件重命名
#os.path.split() 将路径和文件名分开
#os.path.join() 连接目录和文件名
#os.path.exists() 判断路径是否存在
print(os.path.abspath("")) #获取绝对路径
print(os.path.getsize(r"C:\Users\wind.LAPTOP-8EA5MEIP\PycharmProjects\Python基础"))
#获取文件大小
os-知乎总结
5.sys
sys.path
path是一个目录列表,供Python从中查找模块。在Python启动时,sys.path根据内建规则和PYTHONPATH变量进行初始化。sys.path的第一个元素通常是个空字符串,表示当前目录。
>>> sys.path
['', 'C:\\Python36\\Lib\\idlelib', 'C:\\Python36\\python36.zip', 'C:\\Python36\\DLLs', 'C:\\Python36\\lib', 'C:\\Python36', 'C:\\Python36\\lib\\site-packages']
以下两行等价
sys.stdout.write('hello'+'\n')
print('hello')
sys讲解博客园
6.random
import random
print(random.random()) #生成[0.0,1.0)范围的随机浮点数
print(random.uniform(1,100)) #生成[1,100]之间的随机数
print(random.randrange(1,100,9)) #生成水机整数,步长可省
print(random.randint(1,10)) #生成[1,10]之间的随机整数
print(random.choice(['hello','world','python','java','c++','go','php']))
#从非空序列中随机选择一个值
lists = ["hello","world","python","java","C++","go","php"]
random.shuffle(lists)
print(lists) #将序列打乱重排
print(random.sample(range(1000000),k=6))
# sample(population, k) 返回从总体序列或集合中选择的唯一元素的
# k长度列表。 用于无重复的随机抽样
知乎总结random
随机产生四位验证码
#验证码: 大小写字母和数字的组合
def fun():
code=''
for i in range(4):
ran1=str(random.randint(0,9))
ran2=chr(random.randint(65,90))
ran3=chr(random.randint(97,122))
r=random.choice([ran1,ran2,ran3])
code+=r
return code
code=fun()
print(code)
7.re
Python 正则表达式使用–Re 模块详解
8.pickle
Python pickle模块:实现Python对象的持久化存储
import pickle
tup1=('I love Python',{1,2,3},None)
p1=pickle.dumps(tup1) #python对象转换为二进制对象
print(p1)
t2=pickle.loads(p1) #二进制对象转换为python对象
print(t2)
import pickle
tup1=('I love Python',{5,2,0},None)
with open("a.txt",'wb') as f:
pickle.dump(tup1,f) #用dump函数将python对象转换为二进制对象文件
with open("a.txt",'rb') as f:
t=pickle.load(f) #用load函数将二进制对象文件转换为Python对象
print(t)
9.Hashlib模块
加密算法:md5,sha1 sha256 不可逆
类似在登录某个软件的时候你设置的密码通过加密保存在数据库,因为是不可逆的,所以
当你登录的时候,再次将你的密码加密进行匹配数据库的密码
import hashlib
msg='luozhang!'
md5=hashlib.md5(msg.encode('utf-8'))
print(md5.hexdigest())
#解密
sha1=hashlib.sha1(msg.encode('utf-8'))
print(sha1.hexdigest())
list1=[]
password='123456'
sha256=hashlib.sha256(password.encode('utf-8'))
list1.append(sha256.hexdigest())
pwd=input('输入密码:')
sha256=hashlib.sha256(pwd.encode('utf-8'))
pwd=sha256.hexdigest()
for i in list1:
if pwd==i:
print("登录成功")
相关文章
- python标准库
- 库、包、模块的区别
- 官方os-多种操作系统接口
- 官方random-生成伪随机数