机器学习案例:运营商客户流失的数据分析 #数据去重#数据分组整合#缺失值处理#相关性分析#样本平衡#决策树、随机森林、逻辑回归
运营商客户流失分析 - 飞桨AI Studio
目录
1 数据预处理
1.1 数据集去重
1.2 数据集分组整合
1.3 缺失值处理
1.4 相关性分析
2 样本平衡
3 相关性分析
4 构建模型
4.1 随机森林
4.2 决策树
4.3 逻辑回归
5 模型评估
前提:随着业务快速发展、电信市场的竞争愈演愈烈。如何最大程度地挽留在网用户、吸取新客户,是电信企业最
关注的问题之一。 客户流失 会给企业带来一系列损失,故在发展用户每月增加的同时,如何挽留和争取更多
的用户,也是一项非常重要的工作。
能否利用大数据技术预判出哪些用户可能流失,从而为公司运营提供决策?
在数据分析之前,我们先理清数据到底有什么,每个数据代表什么含义,最后再确定怎么下手。

分析题干,我们能够看出这是一个二分类问题。
观察数据:
运营商用户的基础信息和使用行为信息,90W 条记录, 30W 用户 3 个月的数据, 35 个特征。
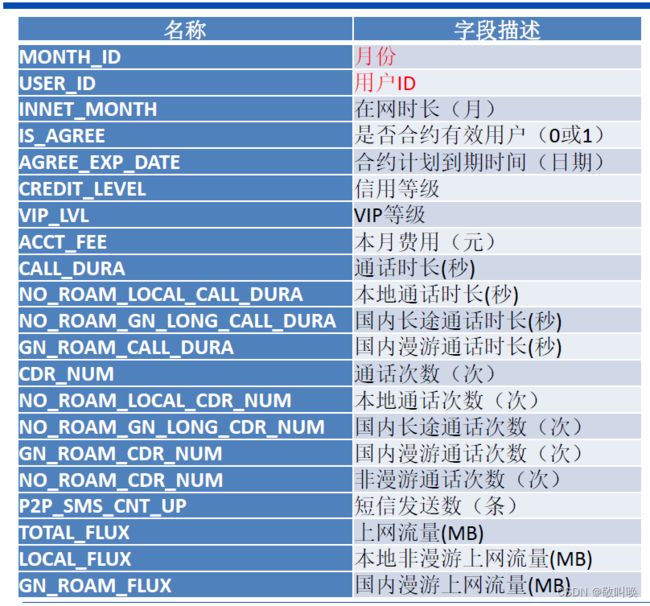
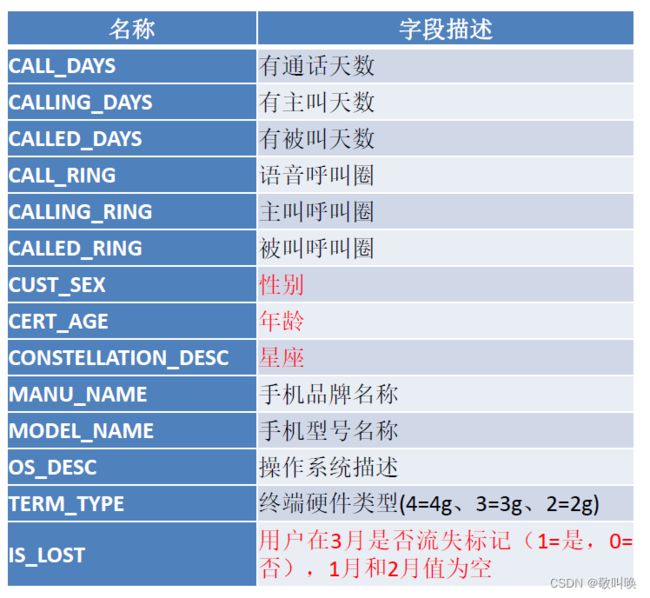
处理思路:
- 由于设备或人工操作失误等原因,数据可能存在重复、缺失和异常情况
- 从业务角度分析,可能存在某些属性和目标变量无关
- 数据时间跨度3 个月,某些属性与时间有关,某些无关,需分开处理
- 原始数据中,每个用户有三行数据 ,需转换成一个用户一行数据的形式。
确定了基本流程后,我们开始动手处理:
先导入数据并预览
import pandas as pd import numpy as np data = pd.read_csv("data/data175811/USER_INFO_M.csv", encoding='gbk') # print(data.head()) print("1 data nall status:", data.isnull().sum(), data.shape)
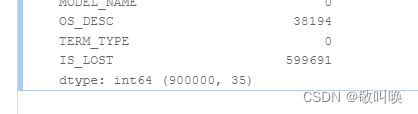
拿到了当前的90W条数据
1 数据预处理
1.1 数据集去重
数据去重
## 1 data duplicate
print("2 duplicating data:", data.duplicated().sum()) # 查看重复数据
data.drop_duplicates(inplace=True) # 数据去重
print("3 result", data.duplicated().sum()) 处理了96行重复数据 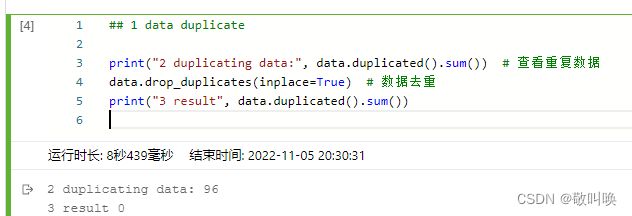
接下来删除无关属性
(这些数据明显不会对用户流失造成影响:
- (手机品牌、手机型号、手机系统、星座)
## 2 drop columns that doesn't matter;
data.drop(['MANU_NAME', 'MODEL_NAME', 'OS_DESC', 'CONSTELLATION_DESC'], axis=1, inplace=True)
print("4 result data columns:", data.columns)
cleardata = data;1.2 数据集分组整合
## 3 data combination(group by id)
data_group = cleardata.groupby('USER_ID') # 分组观察到数据是一个用户有3行数据,分别是在2016-6到 2016-8这三个月的数据。我们想办法将一个用户的数据合并在一行。
首先创建向量,包含关键column:用户id + 用户是否流失
# 3.1 create label with 'USER_ID' and 'IS_LOST'
label = data_group[['USER_ID', 'IS_LOST']].tail(1) # 取用户id、标记(每组的最后一个值)
label.set_index('USER_ID', inplace=True) # 将“USER_ID”设为索引
print(label)
label = data_group[['USER_ID', 'IS_LOST']].tail(1) # 取用户id、标记(每组的最后一个值)
label.set_index('USER_ID', inplace=True) # 将“USER_ID”设为索引
print(label)紧接着是其他的需要进行因素考虑的自变量
基本思想:三行合并为行时,离散数据可以采用取平均值、取中值、独热编码、特征构建等方式,连续值一般是取平均值或者其中一行的值替代,另外譬如用户id、手机型号、用户性别等这些短期内不会改变的量,任取一行作为当前列值即可
# 3.2 insert basic info into the label('CUST_SEX', 'CERT_AGE', 'TERM_TYPE')
data_1 = data_group[['CUST_SEX', 'CERT_AGE', 'TERM_TYPE']].first()
print("data 5.1\n",data_1)
# 3.3 insert info into the label('INNET_MONTH')
data_2 = data_group['INNET_MONTH'].last()
print("data 5.2\n",data_2)
# 3.4 insert info into the label('IS_AGREE') # agree or not
def cal_is_agree(x): # x 为每个用户的三个月值
# 如果三个月不全为1,用第三个月值减去前两个月均值;三个月的值都为1,取值为1.5。
# 所有取值情况为-1、-0.5、0、0.5、1、1.5
x = np.array(x)
if x.sum() == 3:
return 1.5
else:
return x[2] - x[:2].mean()
data_3 = pd.DataFrame(data_group['IS_AGREE'].agg(cal_is_agree))#agg是一个聚合函数,聚合函数操作始终是在轴(默认是列轴,也可设置行轴)上执行,
print("data 5.3\n",data_3)
# 3.5 insert info into the label('AGREE_EXP_DATE') agree date
date = data_group['AGREE_EXP_DATE'].last() # 取第3个月的"合约计划到期时长"
num_mon = (pd.to_datetime(date, format='%Y%m') - pd.to_datetime('2016-03')).dt.days/30 # 时长以“月”为单位
data_4 = pd.DataFrame(num_mon).fillna(-1) #用-1填充缺失值
print("data 5.4\n",data_4)
# 3.6 insert info into the label('CREDIT_LEVEL') level
data_5 = pd.DataFrame(data_group['CREDIT_LEVEL'].agg('mean')) # 信用等级
print("data 5.5\n",data_5)
# 3.7 VIP等级
data_6 = data_group['VIP_LVL'].last().fillna(0) # 取最后一个值
print("data 5.6\n",data_6)
# 3.8 本月费用(取三个月的平均值)特征构建
data_7 = pd.DataFrame(data_group['ACCT_FEE'].mean())
print("data 5.7\n",data_7)
# 3.9 平均每次通话时长
# 总通话
data_8_1 = pd.DataFrame(data_group['CALL_DURA'].sum()/data_group['CDR_NUM'].sum(),
columns=['Total_mean'])
# 本地通话
data_8_2 = pd.DataFrame(data_group['NO_ROAM_LOCAL_CALL_DURA'].sum()/data_group['NO_ROAM_LOCAL_CDR_NUM'].sum(),
columns=['Local_mean'])
# 国内长途通话
data_8_3 = pd.DataFrame(data_group['NO_ROAM_GN_LONG_CALL_DURA'].sum() / data_group['NO_ROAM_GN_LONG_CDR_NUM'].sum(),
columns=['GN_Long_mean'])
# 国内漫游通话
data_8_4 = pd.DataFrame(data_group['GN_ROAM_CALL_DURA'].sum() / data_group['GN_ROAM_CDR_NUM'].sum(),
columns=['GN_Roam_mean'])
# 数据拼接
data_8 = pd.concat([data_8_1, data_8_2, data_8_3, data_8_4], axis=1).fillna(0)
print("data 5.8\n",data_8.head())
# 3.10 其他变量
# 非漫游通话次数(次)、短信发送数(条)、上网流量(MB)、本地非漫游上网流量(MB)、国内漫游上网流量(MB)、
# 有通话天数、有主叫天数、有被叫天数 (主叫 + 被叫 ≠ 总通话)
# 语音呼叫圈、主叫呼叫圈、被叫呼叫圈
data_9 = data_group[['NO_ROAM_CDR_NUM', 'P2P_SMS_CNT_UP', 'TOTAL_FLUX', 'LOCAL_FLUX','GN_ROAM_FLUX',
'CALL_DAYS', 'CALLING_DAYS', 'CALLED_DAYS',
'CALL_RING','CALLING_RING', 'CALLED_RING']].agg('mean')
print("data 5.9\n",data_9)将数据零件准备好后,我们就可以拼接了。
# 对所有特征&标签按索引重新排序,以保证数据拼接时索引一致
label.sort_index(inplace=True)
data_1.sort_index(inplace=True)
data_2.sort_index(inplace=True)
data_3.sort_index(inplace=True)
data_4.sort_index(inplace=True)
data_5.sort_index(inplace=True)
data_6.sort_index(inplace=True)
data_7.sort_index(inplace=True)
data_8.sort_index(inplace=True)
data_9.sort_index(inplace=True)
# 拼接所有特征&标记
data_new = pd.concat([data_1, data_2, data_3, data_4,
data_5, data_6, data_7, data_8, data_9, label], axis=1)
# data_new = pd.concat([data_1, label], axis=1)
# print(data_new.shape)
data_new.head() 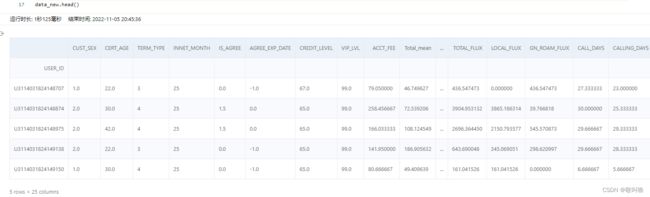
能观察到包含了我们需要的列,展示前5行数据()
1.3 缺失值处理
组装完成完整数据集后,就可以开始进行缺失值处理了。(如果过早进行缺失值处理,可能导致数据集严重丢失,降低训练量)
# 4 drop nall data
#缺失值处理
print("6 isnull \n",data_new.isnull().sum()) # 查看缺失值
data_new = data_new.fillna(method='ffill').fillna(method='bfill') # 近邻值填充(向下填充+向上填充)
data_new.to_csv('data/data175811/clear_data.csv', index=True, encoding='utf-8-sig')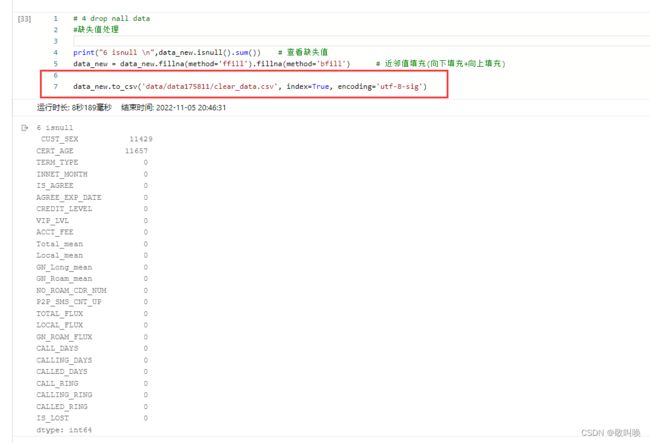
完成当期按步骤后,数据预处理就算完成了。需要保存到本地
1.4 相关性分析
data = pd.read_csv('data/data175811/clear_data.csv', index_col=0)
corr = data.corr() # 皮尔逊相关系数
print(corr)
# 以0.08作为筛选阈值
feature_index = corr['IS_LOST'].drop('IS_LOST').abs() > 0.08 # 取出与"标记"的相关系数
feature_name = feature_index.loc[feature_index].index # 选出的重要特征名
print(feature_name)
进过皮尔逊相关系数计算,能够看到数据集中的列,两两之间的线性相关系数。取出相关系数高的属性进行预测,可以提高训练质量,降低时间开销,提高精确度。

筛选出了一下高相关性属性:
'INNET_MONTH', 'CREDIT_LEVEL', 'NO_ROAM_CDR_NUM', 'CALL_DAYS', 'CALLING_DAYS', 'CALLED_DAYS', 'CALL_RING', 'CALLED_RING
2 样本平衡
输出样本集数据,明显的感觉到:
样本不平衡 负样本远远多余正样本
因此需要做个事情,样本平衡
# 提取特征与标记
X = data.loc[:, feature_name] # 样本自变量
y = data.loc[:, 'IS_LOST'] # 样本目标变量
# 样本不平衡 负样本远远多余正样本
print(y.value_counts())
index_positive = y.index[y == 1] # 正样本的索引
index_negative = np.random.choice(a=y.index[y == 0].tolist(), size=y.value_counts()[1]) # 负样本的索引,对负样本进行下采样操作
X_positive = X.loc[index_positive, :] # 正样本自变量
X_negative = X.loc[index_negative, :] # 负样本自变量
y_positive = y.loc[index_positive] # 正样本标签
y_negative = y.loc[index_negative] # 负样本标签
X = pd.concat([X_positive, X_negative], axis=0) # 处理后的正样本
y = pd.concat([y_positive, y_negative], axis=0) # 处理后的负样本
print(X.shape)
print(y.shape)平衡结果
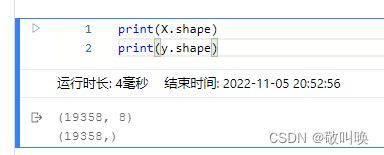
4 构建模型
需要用到的模型:
from sklearn.model_selection import train_test_split #数据集划分
from sklearn.ensemble import RandomForestClassifier # 随机森林
from sklearn.metrics import confusion_matrix, classification_report #报告
from sklearn.tree import DecisionTreeClassifier #决策树
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.metrics import accuracy_score #精确度构建模型前,进行必要的数据集划分:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y) # 分层分割4.1 随机森林
rfc = RandomForestClassifier() # 初始化随机森林模型
rfc.fit(X_train, y_train) # 模型训练
y_pre = rfc.predict(X_test) # 调用模型对测试样本进行预测
print(classification_report(y_test, y_pre)) # 打印分类报告(包含了各模型性能评价指标)
lr_acc = round(accuracy_score(y_pre,y_test)*100,2)
print(f"logistic accuracy is: {lr_acc}%")
# 宏平均,微平均
# rfc.score(X_test, y_test) # 模型在测试集商的精度
# confusion_matrix(y_test, y_pre) # 混淆矩阵4.2 决策树
# 创建决策树模型
dtc = DecisionTreeClassifier()
# 训练模型
dtc.fit(X_train,y_train)
# 预测训练集和测试集结果
dtc_pred = dtc.predict(X_test)
# 计算精确度
dtc_acc = round(accuracy_score(dtc_pred,y_test)*100,2)
print(f"decision tree accuracy is: {dtc_acc}%")4.3 逻辑回归
# 创建逻辑回归模型
lr = LogisticRegression()
# 训练模型
lr.fit(X_train,y_train)
# 预测训练集和测试集结果
lr_pred = lr.predict(X_test)
# 计算精确度
lr_acc = round(accuracy_score(lr_pred,y_test)*100,2)
print(f"logistic accuracy is: {lr_acc}%")
5 模型评估
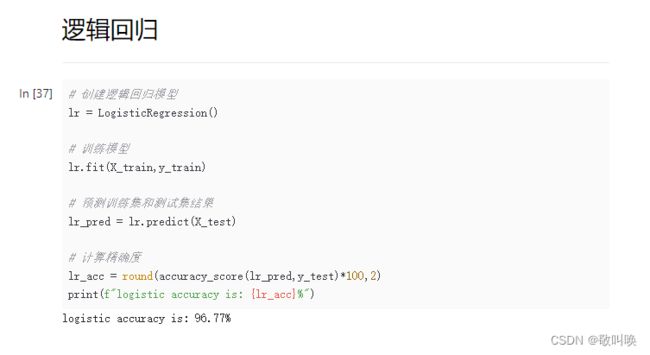
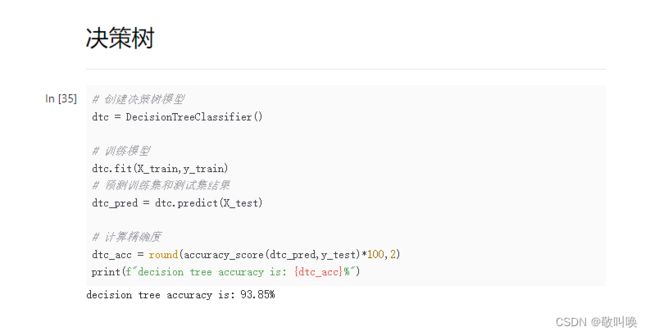
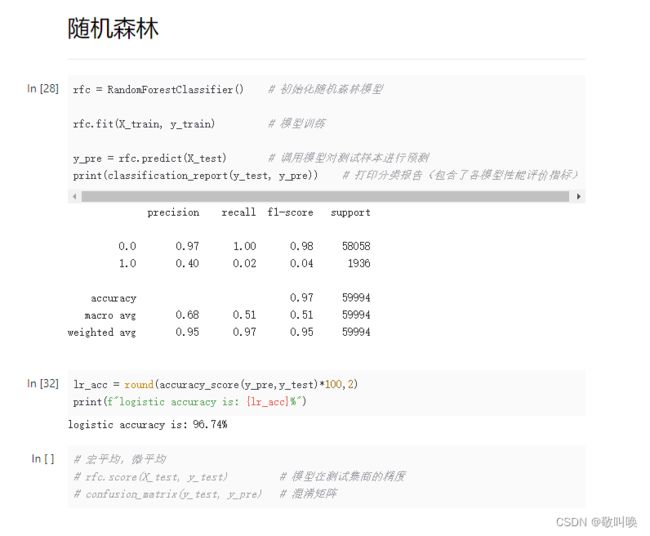
能看到准确率都是在95%左右,说明这个分析案例还是很成功的。