JPA是什么?JPA怎么应用?为什么要用JPA
1 什么是JPA
JPA是(Java Persistence API : java持久层API)
JPA 是一个基于O/R映射的标准规范(目前最新版本是JPA 2.1 )。所谓规范即只定义标准规则(如注解、接口),不提供实现,软件提供商可以按照标准规范来实现,而使用者只需按照规范中定义的方式来使用,而不用和软件提供商的实现打交道。
在过去,有很多针对Java的ORM框架,但是每一套框架都有自己的一套操作方法和规范,这就使得Java程序操作不同数据库时显得杂乱无章。于是乎,Sun公司推出了一套操作持久层(数据库)的规范(API)用于结束这种乱象,这套规范也就是JPA。
这里我们用的是hibernate (一种JPA规范实现的方式)
2 怎么使用JPA(采用客户(1)联系人(n)的一对多关系示例)
2.1 创建一个SpringBoot工程

2.2 导入maven依赖和yml文件配置
org.springframework.boot
spring-boot-starter-data-jpa
2.7.5
mysql
mysql-connector-java
8.0.31
org.projectlombok
lombok
1.18.24
yml文件配置(mysql接口需要根据自己设置修改)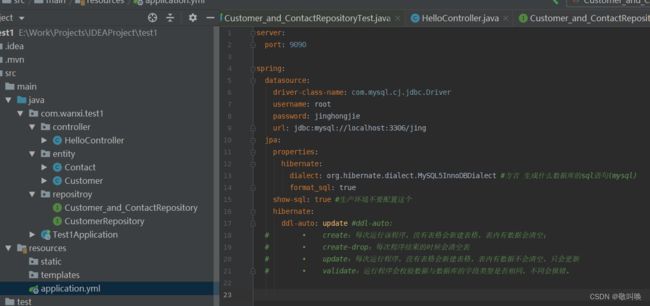
server:
port: 9090spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: jinghongjie
url: jdbc:mysql://localhost:3306/jing
jpa:
properties:
hibernate:
dialect: org.hibernate.dialect.MySQL5InnoDBDialect #方言 生成什么数据库的sql语句(mysql)
format_sql: true
show-sql: true #生产环境不要配置这个
hibernate:
ddl-auto: update #ddl-auto:
# • create:每次运行该程序,没有表格会新建表格,表内有数据会清空;
# • create-drop:每次程序结束的时候会清空表
# • update:每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新
# • validate:运行程序会校验数据与数据库的字段类型是否相同,不同会报错。
2.3 创建测试用例实体
这是'客户'类 Customer
package com.wanxi.test1.entity; import javax.persistence.*; import java.util.Set; //@Data //@ToString //这里不用data注解是因为@Data的hashcode方法会和 后面的 @Onetomany冲突 @Entity @Table(name = "customer") public class Customer { @Id @GeneratedValue(strategy = GenerationType.IDENTITY)//配置指定列(字段)的增量的方式 @Column(name = "id") private int id; @Column(name= "name") String name; @Column(name= "phone") String phone; // @OneToMany : 实现表的关联关系 // mappedBy: 说明 表关联关系中的 关联实体类 // fetch: fetch = FetchType.EAGER 由于这里的Customer包含成员变量ContactSet 默认是懒加载,在查询当前Custormer时 没有去数据库取值, // 需要设置为饿加载(一启动就加载,从数据库中获取) // cascade = {CascadeType.REMOVE} 级联删除,表示我删除customer对象时,对应的LinkManEntiy数据也全部要删除。 @OneToMany(mappedBy = "customer",fetch = FetchType.EAGER,cascade = {CascadeType.REMOVE}) SetcontactSet; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getPhone() { return phone; } public void setPhone(String phone) { this.phone = phone; } public Set getContactSet() { return contactSet; } public void setContactSet(Set contactSet) { this.contactSet = contactSet; } @Override public String toString() { return "Customer{" + "id=" + id + ", name='" + name + '\'' + ", phone='" + phone + '\'' + // 这一行删除了contactSet 对象集合的toStirng 为了避免对象的循环调用,最终导致栈溢出 '}'; } }
这是'联系人'类 Contact
package com.wanxi.test1.entity;
import lombok.Data;
import lombok.ToString;
import javax.persistence.*;
@Data
@ToString
@Entity
@Table(name = "contact") //Table注解:当前类名数据库中的表名对应
public class Contact {
@Id //指定主键
@GeneratedValue(strategy = GenerationType.IDENTITY) //配置指定列(字段)的增量的方式
@Column(name = "id") //字段名、列名
Integer id;
@Column(name = "name")
private String name;
@Column(name = "phone")
private String phone;
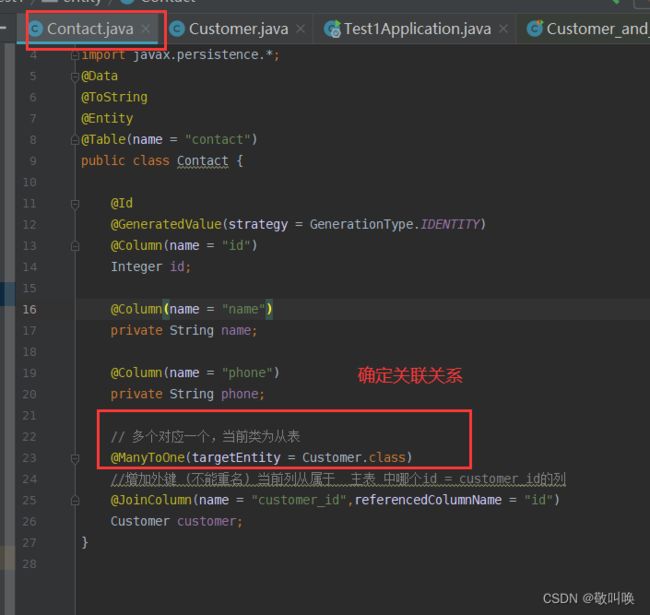
// 多对一,当前类的表 为'从表'
@ManyToOne(targetEntity = Customer.class)
//增加外键name='' (不能重名) 当前列从属于 主表 中哪个id = customer_id的列
@JoinColumn(name = "customer_id",referencedColumnName = "id")
Customer customer;
}
2.4 创建和实体类对应的JpaRepository接口(为了减少持久层代码)

package com.wanxi.test1.repositroy;
import com.wanxi.test1.entity.Customer;
import org.springframework.data.jpa.repository.JpaRepository;
public interface CustomerRepository extends JpaRepository {
}
package com.wanxi.test1.repositroy;
import com.wanxi.test1.entity.Contact;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.List;
public interface Customer_and_ContactRepository extends JpaRepository {
}
2.4 建立表关联关系
已经包含在了上面的实体类中

2.5 实现基本功能(CRUD)
创建测试类(两个Repositroy同样操作)

如图所示
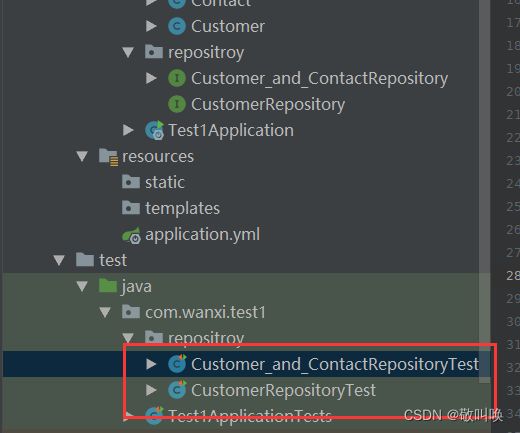
在这两个测试类中依次测试对应功能(具体代码和注释如下)
Customer_and_ContactRepositoryTest
package com.wanxi.test1.repositroy;
import com.wanxi.test1.entity.Contact;
import com.wanxi.test1.entity.Customer;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.*;
import org.springframework.data.jpa.domain.Specification;
import javax.persistence.criteria.CriteriaBuilder;
import javax.persistence.criteria.CriteriaQuery;
import javax.persistence.criteria.Predicate;
import javax.persistence.criteria.Root;
import java.util.List;
@SpringBootTest
class Customer_and_ContactRepositoryTest {
//注入Respository
@Autowired
CustomerRepository customerRepository;
@Autowired
Customer_and_ContactRepository customer_and_contactRepository;
//测试增加 客户
@Test
void add() {
Customer customer = new Customer();
customer.setName("jing");
System.out.println(customer);
customerRepository.save(customer);
System.out.println(customer);
/**输出结果
* Customer(id=0, name=jing, phone=null, contactSet=null)
* Hibernate:
* insert
* into
* customer
* (name, phone)
* values
* (?, ?)
* Customer(id=4, name=jing, phone=null, contactSet=null)
* */
}
//测试增加 联系人
// org.springframework.dao.InvalidDataAccessApiUsageException: org.hibernate.TransientPropertyValueException: object
// references an unsaved transient instance - save the transient instance before flushing
// 报错解释 解释这个异常:
// 持久化里对象的三大状态 临时态、持久化态、游离态,
// 当我们需要增加一个或几个从表对象当数据中之前,在当前代码中,他们都是内存中临时变量,属于临时态,只有存入到数据库中时,
// 才能转为持久化态(判断依据是 对象的数据和数据库中的数据保持一致) ,在存入的过程中,主表中的对象依旧是临时态,
// 所以出现了主从表对象状态不一致的情况,
// 报错解决方案:
// 因此需要将主表对象一样存入数据库。
// 或者从数据中拿到一个主表对象
@Test
void addCustomerAndContact() {
//初始化客户(有客户才有联系人)
Customer customer = new Customer();
customer.setName("zn1");
Contact contact1 = new Contact();
contact1.setName("jing");
contact1.setCustomer(customer);
Contact contact2 = new Contact();
contact2.setName("yang");
contact2.setCustomer(customer);
// 方式一:保存customer
customerRepository.save(customer);
// 方式二:从数据库取一个Customer对象,这个自己试
// 1. 保存地址
customer_and_contactRepository.save(contact1);
customer_and_contactRepository.save(contact2);
}
@Test
void delete() {
}
@Test
void alter() {
}
//分页采用pageRequest
@Test
void findAll() {
// 通过对c_id排序。这里传入的是地址表里的customer对象名,注意看of的参数是 properties.指的是对象Contact 的属性名customer,不是表的列名
PageRequest pageRequest = PageRequest.of(1, 3, Sort.Direction.DESC, "customer");
//加入分页规则 ,返回Page对象(报错collection was evicted ,因为映射的集合对象类型不适用(被驱逐取消使用),把Set换成List)
Page contactPage = customer_and_contactRepository.findAll(pageRequest);
//转型
List contactList = contactPage.toList();
Assertions.assertTrue(contactList.size() > 0);
}
@Test
void findById() {
Customer customer = customerRepository.findById(1).orElse(null);
System.out.println(customer);
System.out.println(customer.getContactSet());
//输出结果 报错:
// org.hibernate.LazyInitializationException: failed to lazily initialize a collection of role:
// com.wanxi.test1.entity.Customer.contactSet, could not initialize proxy - no Session
//断点 看sql语句,你发现并没有去查询地址表的数据,怎么回事?那我们怎么才能拿到客户地址呢?
//解决方案:customer中的注解@OneToMany加入,fetch = FetchType.EAGER参数
// 修改后结果: select
// customer0_.id as id1_1_0_,
// customer0_.name as name2_1_0_,
// customer0_.phone as phone3_1_0_,
// contactset1_.customer_id as customer4_0_1_,
// contactset1_.id as id1_0_1_,
// contactset1_.id as id1_0_2_,
// contactset1_.customer_id as customer4_0_2_,
// contactset1_.name as name2_0_2_,
// contactset1_.phone as phone3_0_2_
// 剖析根本原因:
// customer.getContactSet()会去查询contact表 这时查询customer的会话已经关闭了。所以就没有可用的session来查address。
// 他们是两个事务,按照这个思路,只需要把两个事务加上即可
//解决方案二:去掉刚才的FetchType
//加上注解 @Transactional在测试方法体上
}
//模糊查询方式一 亲测不可行(待修改)
@Test
void likeSearch1(){
List contactList = customer_and_contactRepository.findByNameLike("%y%");
System.out.println(contactList);
}
//实现 客户的 名字模糊查询
@Test
void likeSearch2(){
String likeString = "%z%";// 单一的条件
Specification specification = new Specification() {//匿名内部类
@Override
public Predicate toPredicate(Root root, CriteriaQuery query, CriteriaBuilder criteriaBuilder) {
Predicate like = criteriaBuilder.like(root.get("address").as(String.class),likeString);
return like;
}
};
//几个类的讲解
//Predicate :可以理解就是各种条件的结果对象
//Specification:一个接口,提供了not,where,and,or的静态实现,同时有一个toPredicate抽象方法。可以简单理解Specification构造的就是查询条件
//是Spring Data JPA提供的一个查询规范,要做复杂的查询,只需围绕这个规范来设置查询条件即可。
//按照官方说法:Specification in the sense of Domain Driven Design
//JpaSpecificationExecutor:Interface to allow execution of Specifications based on the JPA criteria API。就是提供了对Specifications 的支持
//https://www.cnblogs.com/zuiyue_jing/p/15149511.html
}
//实现多个like的Sql语句查询(类似于mybatis,)
@Test
void manyLikeSearch(){
}
} CustomerRepositoryTest
package com.wanxi.test1.repositroy;
import com.wanxi.test1.entity.Customer;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class CustomerRepositoryTest {
@Autowired
CustomerRepository customerRepository;
@Test
void add() {
Customer customer = new Customer();
//
customer.setName("zn");
System.out.println(customer);
//
customerRepository.save(customer);
System.out.println(customer);
}
}3 使用JpaRepository 接口的意义和优势
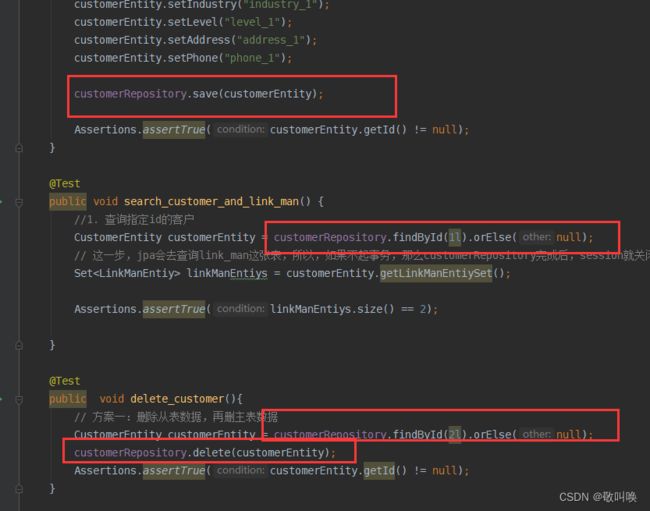
** 使用Spring Data Repository接口类的目标是:显著减少各种持久层的数据访问所 需的代码量。**
比如这里我们就不在需要去写sql代码,而是自动生成
我们能够看到,通过这些代理的接口,我们能够直接调用它自带的方法去执行一些简单的sql语句 ,实现增删改查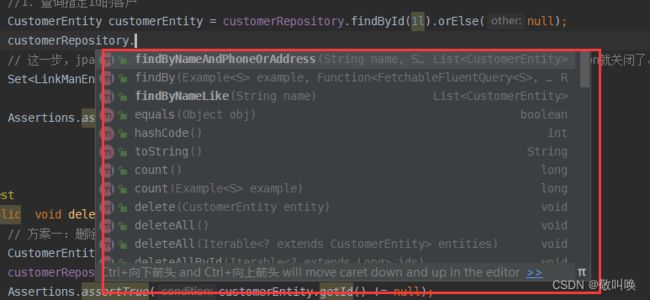
此外JPA还有以下特点
标准化
JPA 是 JCP 组织发布的 Java EE 标准之一,因此任何声称符合 JPA 标准的框架都遵循同 样的架构,提供相同的访问API,这保证了基于JPA开发的企业应用能够经过少量的修改就能够在 不同的 JPA 框架下运行。
容器级特性的支持
JPA 框架中支持大数据集、事务、并发等容器级事务,这使得 JPA 超越了简单持久化框架的 局限,在企业应用发挥更大的作用。
简单方便
JPA 的主要目标之一就是提供更加简单的编程模型:在 JPA 框架下创建实体和创建 Java 类一样简单,没有任何的约束和限制,只需要使用 javax.persistence.Entity 进行注释,JPA的 框架和接口也都非常简单,没有太多特别的规则和设计模式的要求,开发者可以很容易的掌握。 JPA 基于非侵入式原则设计,因此可以很容易的和其它框架或者容器集成
查询能力
JPA 的查询语言是面向对象而非面向数据库的,它以面向对象的自然语法构造查询语句,可以看成是 Hibernate HQL 的等价物。JPA 定义了独特的 JPQL(Java Persistence Query Language),JPQL 是 EJB QL 的一种扩展,它是针对实体的一种查询语言,操作对象是实体,而 不是关系数据库的表,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询
高级特性
JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系。这样的支持能够让开发者最大限度的使用面向对象的模型设计企业应用,而不需要自行处理这些特性。 Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套 JPA 应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率! Spring Data JPA 让我们解脱了 DAO 层的操作,基本上所有 CRUD 都可以依赖于它来实现,在实际的工作工程中,推荐使用 Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的 ORM 框架时提供了极大的方便,同时也使数据库层操作更加简单,方便。