pytorch 介绍
是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序。不仅能够 实现强大的GPU加速,同时还支持动态神经网络.
PyTorch提供了两个高级功能:
1.具有强大的GPU加速的张量计算(如Numpy)
2.包含自动求导系统的深度神经网络
与tensorflow,caffe区别
TensorFlow和Caffe都是命令式的编程语言,而且是静态的,首先必须构建一个神经网络,然后一次又一次使用相同的结构,如果想要改 变网络的结构,就必须从头开始。但是对于PyTorch,通过反向求导技术,可以零延迟地任意改变神经网络的行为,而且其实现速度快。
PyTorch的优点
- 支持GPU
- 灵活,支持动态神经网络
- 底层代码易于理解
- 命令式体验
- 自定义扩展
PyTorch缺点
- 目前PyTorch还不支持快速傅里 叶、沿维翻转张量和检查无穷与非数值张量;
- 针对移动端、嵌入式部署以及高性能服务器端的部署其性能表现有待提升;
- 其次因为这个框架较新,使得他的社区没有那么强大,在文档方面其C库大多数没有文档
安装
查看pytorch官网: https://pytorch.org/
查看版本:
import torch
print(torch.__version__) #注意是双下划线`
教程
参考官方文档:http://pytorch.panchuang.net/FifthSection/
关键模块
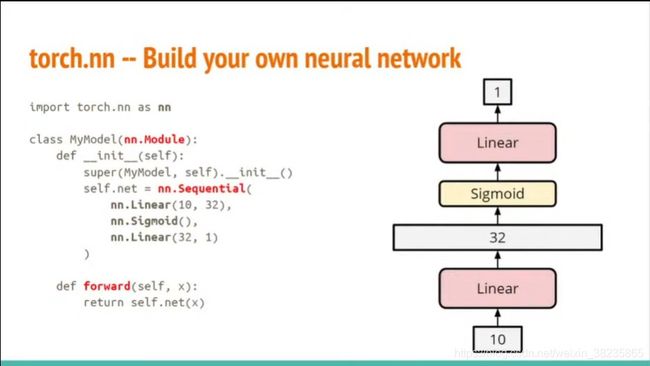
network

Dataloader
dataset 
linear_layer


计算梯度

save,load

train

valid

test

基础函数
torch.max()
x = torch.randn(4,5)
# 1. max of entire tensor (torch.max(input) → Tensor)
torch.max(x)
# 2. max along a dimension (torch.max(input, dim, keepdim=False, *, out=None) → (Tensor, LongTensor))
m, idx = torch.max(x,0)
常见错误
# 1. different device error
model = torch.nn.Linear(5,1).to("cuda:0")
x = torch.Tensor([1,2,3,4,5]).to("cpu")
y = model(x)
#Tensor for 'out' is on CPU, Tensor for argument #1 'self' is on CPU, but expected them to be on GPU (while checking arguments for addmm)
# 2. mismatched dimensions error
x = torch.randn(4,5)
y= torch.randn(5,4)
z = x + y
#The size of tensor a (5) must match the size of tensor b (4) at non-singleton dimension 1
# 3. cuda out of memory error
import torch
import torchvision.models as models
resnet18 = models.resnet18().to("cuda:0") # Neural Networks for Image Recognition
data = torch.randn(2048,3,244,244) # Create fake data (512 images)
out = resnet18(data.to("cuda:0")) # Use Data as Input and Feed to Model
print(out.shape)
#CUDA out of memory. Tried to allocate 7.27 GiB (GPU 0; 14.76 GiB total capacity; 8.74 GiB already allocated; 4.42 GiB free; 9.42 GiB reserved in total by PyTorch)
# 4. mismatched tensor type
import torch.nn as nn
L = nn.CrossEntropyLoss()
outs = torch.randn(5,5)
labels = torch.Tensor([1,2,3,4,0])
lossval = L(outs,labels) # Calculate CrossEntropyLoss between outs and labels
#expected scalar type Long but found Float
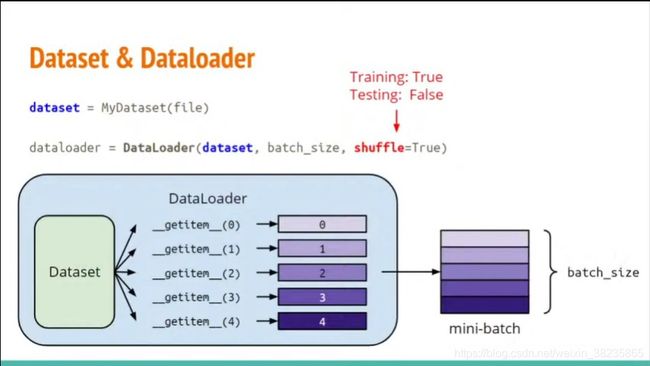
dataset and dataloader
dataset是以某种组织形式集合的数据。dataloader是可以迭代dataset的loader
在使用dataloader时,我们经常喜欢对数据进行乱序操作。这是torch.utils.data.DataLoader派上用场的地方。如果从torch.utils.data.DataLoader的角度来看每个数据都是索引(0,1,2 …),乱序可以通过打乱索引很简单做到
torch.utils.data.DataLoader需要两个信息来行使其职责。
首先,需要知道数据的长度。
其次,一旦torch.utils.data.DataLoader输出乱序结果的索引,则数据集需要返回相应的数据。
所以torch.utils.data.Dataset提供2个函数,__len__() 和 __getitem__()
import torch
import torch.utils.data
class ExampleDataset(torch.utils.data.Dataset):
def __init__(self):
self.data = "abcdefghijklmnopqrstuvwxyz"
def __getitem__(self,idx): # if the index is idx, what will be the data?
return self.data[idx]
def __len__(self): # What is the length of the dataset
return len(self.data)
dataset1 = ExampleDataset() # create the dataset
dataloader = torch.utils.data.DataLoader(dataset = dataset1,shuffle = True,batch_size = 1)
for datapoint in dataloader:
print(datapoint)
通过更改__len __()和__getitem __()中的代码,可以完成一种简单的数据增强技术。
import torch
from torch.utils.data import Dataset
class TIMITDataset(Dataset):
def __init__(self, X, y=None):
self.data = torch.from_numpy(X).float()
if y is not None:
y = y.astype(np.int)
self.label = torch.LongTensor(y)
else:
self.label = None
def __getitem__(self, idx):
if self.label is not None:
return self.data[idx], self.label[idx]
else:
return self.data[idx]
def __len__(self):
return len(self.data)