【贝叶斯分类2】朴素贝叶斯分类器
文章目录
- 1. 贝叶斯决策论回顾
-
- 1.1 分类原理
- 1.2 贝叶斯分类器
- 1.3 P(c|x)
- 1.4 计算公式
- 1.5 极大似然估计
- 2. 朴素贝叶斯分类器学习笔记
-
- 2.1 引言
- 2.2 知识卡片
- 2.3 朴素贝叶斯分类器
- 2.4 拉普拉斯平滑
- 3. 朴素贝叶斯分类器拓展
-
- 3.1 数据处理
- 3.2 收集其他资料
1. 贝叶斯决策论回顾
1.1 分类原理
分类原理。 Y = { c 1 , c 2 , . . . , c N } Y = \{c_1, c_2, ..., c_N\} Y={c1,c2,...,cN} 有N种标记, λ i j \lambda_{ij} λij 是将一个真实标记为 c j c_j cj 的样本误分类为 c i c_i ci 所产生的损失。 R ( c i ∣ x ) R(c_i|x) R(ci∣x) 是将样本 x x x 分类为 c i c_i ci 所产生的期望损失(又叫样本 x x x 的条件风险)。我们已知了错误的分类标记 c i c_i ci,我们的目的是求这个期望损失,并且要找最小。定义公式: R ( c i ∣ x ) = ∑ j = 1 N λ i j P ( c j ∣ x ) . R(c_i|x)=\sum_{j=1}^N\lambda_{ij}P(c_j|x). R(ci∣x)=∑j=1NλijP(cj∣x). 例如: λ i j \lambda_{ij} λij 分别为样本 { x 1 , x 2 , . . . , x j } \{x_1, x_2, ..., x_j\} {x1,x2,...,xj} 误分类为 c i c_i ci 所产生的损失。 P ( c j ∣ x ) P(c_j|x) P(cj∣x) 分别为样本 { x 1 , x 2 , . . . , x j } \{x_1, x_2, ..., x_j\} {x1,x2,...,xj} 事件发生对应的一个概率。
1.2 贝叶斯分类器
贝叶斯分类器。我们利用上面的原理,有N种标记就有N种类别就可以分N类, { c 1 , c 2 , . . . , c N } \{c_1, c_2,..., c_N\} {c1,c2,...,cN} 统称为 c c c 。“只要每个样本 x x x 的条件风险最小,只需在每个样本上选择那个能使条件风险 R ( c ∣ x ) R(c|x) R(c∣x) 最小的类别标记,这就是是贝叶斯判定准则”。贝叶斯最优分类器: h ∗ ( x ) = a r g m i n c ∈ Y R ( c ∣ x ) h^*(x)=arg\ min_{c\in Y}R(c|x) h∗(x)=arg minc∈YR(c∣x)。
1.3 P(c|x)
h ∗ ( x ) = a r g m a x c ∈ Y P ( c ∣ x ) h^*(x)=arg\ max_{c\in Y}P(c|x) h∗(x)=arg maxc∈YP(c∣x)。证明:误判损失 λ i j = { 0 , i = j 1 , 其 他 \lambda_{ij} = \left\{ \begin{array}{lr} 0 & ,i=j\\[6pt] 1 & ,其他 \end{array} \right. λij={01,i=j,其他, R ( c i ∣ x ) = ∑ j = 1 N λ i j P ( c j ∣ x ) R(c_i|x)=\sum_{j=1}^N\lambda_{ij}P(c_j|x) R(ci∣x)=∑j=1NλijP(cj∣x), R ( c i ∣ x ) = ∑ j = 1 N P ( c j ∣ x ) 且 i ≠ j R(c_i|x)=\sum_{j=1}^NP(c_j|x)且i\neq j R(ci∣x)=∑j=1NP(cj∣x)且i=j, ∑ j = 1 N P ( c j ∣ x ) = 1 \sum_{j=1}^NP(c_j|x)=1 ∑j=1NP(cj∣x)=1,… …,最后得 R ( c ∣ x ) = 1 − P ( c ∣ x ) R(c_|x)=1-P(c|x) R(c∣x)=1−P(c∣x)。
1.4 计算公式
计算公式。 P ( c ∣ x ) = P ( c ) P ( x ∣ c ) P ( x ) P(c|x)=\frac{P(c)P(x|c)}{P(x)} P(c∣x)=P(x)P(c)P(x∣c), P ( c ) P(c) P(c) 是类先验概率, P ( x ∣ c ) P(x|c) P(x∣c) 是样本 x x x 相对于类标记 c c c 的类条件概率(又称为:“似然”), P ( x ) P(x) P(x) 对所有类标记均相同。先验 P ( c ) P(c) P(c) 是样本空间中各类样本所占的比例。似然 P ( x ∣ c ) P(x|c) P(x∣c) 通过极大似然估计法计算。
1.5 极大似然估计
极大似然估计。我们要求解 P ( x ∣ c ) P(x|c) P(x∣c), D c D_c Dc 表示训练集D 中第c 类样本组成的集合,这些样本独立且同分布。有似然公式: P ( D c ∣ c ) = ∏ x ∈ D c P ( x ∣ c ) P(D_c|c)=\prod_{x\in D_c}P(x|c) P(Dc∣c)=∏x∈DcP(x∣c),连乘操作易造成下溢,一般取对数处理。 l o g P ( D c ∣ c ) logP(D_c|c) logP(Dc∣c)。要求解的是它的最大值。
2. 朴素贝叶斯分类器学习笔记
2.1 引言
h ∗ ( x ) = a r g m a x c ∈ Y P ( c ∣ x ) h^*(x)=arg\ max_{c\in Y}P(c|x) h∗(x)=arg maxc∈YP(c∣x), P ( c ∣ x ) = P ( c ) P ( x ∣ c ) P ( x ) P(c|x)=\frac{P(c)P(x|c)}{P(x)} P(c∣x)=P(x)P(c)P(x∣c),主要困难是求类条件概率 P ( x ∣ c ) P(x|c) P(x∣c),它是所有属性的联合概率(计算上将会遭遇组合爆炸问题;数据上将会遭遇缺失值)。朴素贝叶斯分类器:“对已知类别,假设所有属性相互独立。(属性条件独立性假设)”
2.2 知识卡片
1. 朴素贝叶斯分类器:Naive Bayes classifier
2. 又称:NB算法
2.3 朴素贝叶斯分类器
- 计算类条件概率 P ( x ∣ c ) P(x|c) P(x∣c)
d 为属性数目
x i x_i xi 为 x x x 在第 i i i 个属性上的取值
P ( x ∣ c ) = ∏ i = 1 d P ( x i ∣ c ) P(x|c)=\prod_{i=1}^dP(x_i|c) P(x∣c)=i=1∏dP(xi∣c)
- 朴素贝叶斯分类器的表达式
知识回顾里讲了,对所有类别来说,P(x)相同
h n b ( x ) = a r g m a x c ∈ Y P ( c ) ∏ i = 1 d P ( x i ∣ c ) h_{nb}(x)=arg\ max_{c\in Y}\ P(c)\prod_{i=1}^dP(x_i|c) hnb(x)=arg maxc∈Y P(c)i=1∏dP(xi∣c)
- 计算先验概率 P ( c ) P(c) P(c)
P ( c ) = ∣ D c ∣ ∣ D ∣ P(c)=\frac{|D_c|}{|D|} P(c)=∣D∣∣Dc∣
- 计算类条件概率 P ( x i ∣ c ) P(x_i|c) P(xi∣c)
(离散型)
P ( x i ∣ c ) = ∣ D c , x i ∣ ∣ D c ∣ P(x_i|c)=\frac{|D_{c, x_i}|}{|D_c|} P(xi∣c)=∣Dc∣∣Dc,xi∣
(连续性)
对 于 连 续 属 性 可 考 虑 概 率 密 度 函 数 \ \ \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ {}对于连续属性可考虑概率密度函数 对于连续属性可考虑概率密度函数
两 点 、 几 何 、 二 项 、 指 数 、 泊 松 、 正 态 分 布 等 \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ {}两点、几何、二项、指数、泊松、正态分布等 两点、几何、二项、指数、泊松、正态分布等
- 例子
【数据集D】
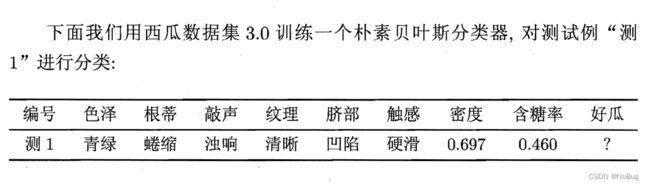
【先验概率 P ( c ) P(c) P(c)】
P ( 好 瓜 = 是 ) = 8 17 ≈ 0.471 P(好瓜=是)=\frac{8}{17}\approx0.471 P(好瓜=是)=178≈0.471
P ( 好 瓜 = 否 ) = 9 17 ≈ 0.529 P(好瓜=否)=\frac{9}{17}\approx0.529 P(好瓜=否)=179≈0.529
【类条件概率 P ( x i ∣ c ) P(x_i|c) P(xi∣c)】

【朴素贝叶斯分类器】

因为, 0.038 0.038 0.038 > 6.80 × 1 0 − 5 6.80\times10^{-5} 6.80×10−5
朴 素 贝 叶 斯 分 类 器 将 测 试 样 本 " 测 1 " 判 别 为 " 好 瓜 " 朴素贝叶斯分类器将测试样本"测 1" 判别为"好瓜" 朴素贝叶斯分类器将测试样本"测1"判别为"好瓜"
2.4 拉普拉斯平滑
-
问题引出
实际中肯定会遇到,比如:属性为“敲声=清脆”的有8个样本,但这8个样本的类别是“好瓜”的没有。所以有: P 清 脆 ∣ 是 = P ( 敲 声 = 清 脆 ∣ 好 瓜 = 是 ) = 0 8 = 0 P_{清脆|是}=P(敲声=清脆|好瓜=是)=\frac{0}{8}=0 P清脆∣是=P(敲声=清脆∣好瓜=是)=80=0,当作连乘处理时,无论该样本的其他属性是什么,哪怕在其他属性上明显像好瓜,分类的结果都将是“好瓜=否”,显然不太合理。 -
拉普拉斯平滑
分子加一,分母加K,K代表类别数目。 -
例子

3. 朴素贝叶斯分类器拓展
3.1 数据处理
在现实任务中朴素贝叶斯分类器有多种使用方式。
例如,若任务对预测速度要求较高,则对给定训练集,可将朴素贝叶斯分类器涉及的所有概率估值事先计算好存储起来,这样在进行预测时只需"查表"即可进行判别;
若任务数据更替频繁,则可采用“懒惰学习” (lazy learning) 方式,先不进行任何训练,待收到预测请求时再根据当前数据集进行概率估值;
若数据不断增加,则可在现有估值基础上,仅对新增样本的属性值所涉及的概率估值进行计数修正即可实现增量学习。
3.2 收集其他资料
【朴素贝叶斯分类器的核心】
h ∗ ( x ) = a r g m a x c ∈ Y P ( c ∣ x ) , P ( c ∣ x ) = P ( c ) P ( x ∣ c ) P ( x ) h^*(x)=arg\ max_{c\in Y}P(c|x),P(c|x)=\frac{P(c)P(x|c)}{P(x)} h∗(x)=arg maxc∈YP(c∣x),P(c∣x)=P(x)P(c)P(x∣c)
P ( 类 别 ∣ 特 征 ) = P ( 类 别 ) P ( 特 征 ∣ 类 别 ) P ( 特 征 ) P(类别|特征)=\frac{P(类别)P(特征|类别)}{P(特征)} P(类别∣特征)=P(特征)P(类别)P(特征∣类别)
【朴素贝叶斯分类器的优缺点】
- "优点:"
1. 算法逻辑简单,易于实现
2. 分类过程中时空开销小
- "缺点:"
1. 因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的。
2. 在属性个数比较多或者属性之间相关性较大时,分类效果不好。
- "解决:"
1. 对于nb算法的缺点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
【贝叶斯网络】
贝叶斯网络百科