YOLOv3: An Incremental Improvement 论文详细解读
目录
- 前言
- 1. 边界框预测
- 2. 多类别标注与分类
- 3. 多尺度目标检测
- 4. 网络架构
前言
对应YOLOv1论文解读:You Only Look Once: Unified, Real-Time Object Detection(Yolov1) 论文详细解读
YOLOv2论文解读:YOLO9000: Better, Faster, Stronger (Yolov2)论文详细解读
其他的论文可在该栏目搜索:论文解读栏目 (实时更新阅读)
1. 边界框预测
边界框的预测和Yolov2 思想一致,详细的内容可看Yolov2的知识点
- 预测边界框使用聚类作为Anchor Boxes
- 该网络为每个边界框预测4个坐标(tx、ty、tw、th)以及置信度
- 相对于全图左上角偏移了(cx, cy),宽度和高度为pw,ph,本身已经归一化为0到1之间
通过以上法则预测出真正预测框的中心坐标值
具体公式如下:

训练的过程中,使用均方误差来计算损失,通过∑(标签值 - 预测值)2 (逻辑回归问题进行训练),Yolov3使用sigmod进行输出
补充知识:
之所以使用回归逻辑而不用softmax进行训练的原因?
- 一般使用softmax进行训练,类别必须要相互独立互斥
- 使用逻辑回归,样本有重叠,预测每个类别的得分,设置阈值,大于该阈值,即为边界框的真实类别
- 此处的每个grid cell 都会输3个Anchor(Yolov2 是输出5个),总共输出9个Anchor(一共有3个尺度)
- 这9个Anchor 与 真实框最大的拟合,挑选最大的IOU值作为正样本
具体公式为:Pr(physical object) = Pr(Object)* IOU
在Yolov1 和 Yolov2的置信度是标签值, 为真实框的时候Pr(Object)= 1
在Yolov3中,IOU为最大的值,即Pr(physical object) = 1
那么在Yolov1 和 Yolov2 中 IOU作为置信度标签有什么不好?
- 预测框与真实框的IOU设置为0.7,本身重合度不高,得不到更好的反馈,而用Yolov3挑选最大的IOU值,当做正样本可以更好的学习
- COCO中的小目标,相对误差比较大
在Yolov3中 正样本标签为1,负样本标签为0
最终可视化图像如下:

挑选最大的阈值,其中某些值超出设定的IOU阈值 应如何操作?
答:筛选掉这些阈值,只要最大并且将其置为1,其他的样本即使超过设定阈值也变为负样本
类似Faster R-CNN,将那些阈值超过0.5的阈值都忽略掉(不用产生损失函数)
Yolov3是每一个真实框只负责一个预测框
- 如果为正样本,会对定位、置信度、分类产生值
- 如果IOU小于0.5(即使大于0.5,没被归为最大的IOU),都归为负样本,负样本只有置信度误差,不计算定位以及分类误差(这两个都为0)
正负样本会影响性能,正负样本很重要
2. 多类别标注与分类
类别预测:
- 使用多标签分类法来预测边界框中可能包含的类别,此处不适用softmax(80个类别里挑出一个确切的类别,此处不适用)
- 使用二元交叉熵损失来类别预测,每一个类别就是一个独立的概率(如果使用softmax预测,每个边界框只有一个类别,但事实并非如此)
补充相关知识点:
- 三分钟认知Softmax和Sigmoid的详细区别
- 二元交叉熵的基本概念
3. 多尺度目标检测
yolov3在3个不同尺度上预测边界框,受金字塔网络启发(FPN),将其多个层进行融合,由不同特征网络提取的特征分别加不同的卷积层,每一个尺度获得3维的卷积核(都有255个通道:编码边界框、物体性和类别预测。也就是: [3 ∗ (4 + 1 + 80)])
- 此处使用的是COCO数据集,每个尺度预测3个边界框
- 张量为
N × N × [3 ∗ (4 + 1 + 80)],该尺度下的N * N个格子,3个预测框,4代表xyhw,1代表置信度,80为类别预测。(此处的4并非是直接偏移的,而是通过sigmoid预测的x 、y坐标)
对比以往YOLO结构
| 结构 | 输入输出 | 张量大小 |
|---|---|---|
| Yolov1 | 448 *448 | 7 * 7 * (5 * 2个框 + 20个类别) (无Anchor) |
| Yolov2 | 446 * 446 | 13 * 13 * 5 * (5 + 20个类别) (每个格子有5个Anchor) |
| Yolov3 | 256 * 256 | (8 * 8 + 16 * 16 + 32 * 32 )* 3 下采用是 32、16、8倍 |
| Yolov3 | 416 * 416 | (13 * 8 + 26 * 26 + 52 * 52 )* 3 下采用是 32、16、8倍 |
通过多尺度目标检测改进了小物体的预测
使用 k-means 聚类来确定边界框,得到9个聚类和3个Anchor,每个尺度上分配了3个Anchor
- 小目标:52 * 52 ,分别为 (10×13),(16×30),(33×23)
- 中目标:26 * 26 ,分别为 (30×61),(62×45),(59×119)
- 大目标:13 * 13 ,分别为 (116 × 90),(156 × 198),(373 × 326).
4. 网络架构
目前新的网络主要基于 Yolov2 、 Darknet - 19 以及 ResNet。
对应ResNet的知识点可看:Deep Residual Learning for Image Recognition (ResNet)论文详细解读
新的网络架构 通过 3 * 3、1 * 1的卷积 以及shortcut短路连接,总共有53个卷积层(52卷积层 + 1个全连接层),所以称为Darknet - 53
详细的流程如下(输入256 * 256的尺寸):
- 输入256 * 256的尺寸,经过3 * 3 * 32进行卷积,输出256 * 256 * 32
- 经过3 * 3 * 64卷积核,步长为2的下采样,输出为128 * 128 * 64
- (1个残差模块)学习后,输出128 * 128 * 64,在经过3 * 3 * 128,步长为2的下采样,输出为64 * 64 * 128
- (2个残差模块)学习后,输出64 * 64 * 128,在经过3 * 3 * 256,步长为2的下采样,输出为32 * 32 * 256
- (8个残差模块)学习后,输出32 * 32 * 256,在经过3 * 3 * 512,步长为2的下采样,输出为16* 16 * 512
- (8个残差模块)学习后,输出16 * 16 * 512,在经过3 * 3 * 1024,步长为2的下采样,输出为8 * 8 * 1024
- (4个残差模块)学习后,输出8 * 8 * 1024
- 经过全局池化连接、全连接层、softmax输出
整体的网络架构为残差网络,每个残差中间加入下采样步长为2
输入256 * 256 的尺寸,通过3 * 3 的卷积核,以及步长为2的下采样,怎么输出128 * 128 的尺寸?
答案:通过卷积核的计算公式:【(输入尺寸大小 + 2P - 卷积核大小)/ 步长 】+ 1
套入公式,此处的P为左右补零,所以为1,。此处算出的结果为128.5,向下取整,最后为128
具体在代码模块中,深层网络结构 用到上采用以及拼接
具体的网络架构图来源:【论文解读】Yolo三部曲解读——Yolov3
另外的一张网络架构图来源:yolo系列之yolo v3【深度解析】

论文中的架构图如下:(来源:【精读AI论文】YOLO V3目标检测(附YOLOV3代码复现))
经过骨干网络Backbone 提取特征,由不同特征在Neck中进行汇总。输入416 * 416 * 3的尺度最终会输出 13 * 13 * 85 、26 * 26 * 85 以及 52 * 52 * 85,一共有3个Anchor,最后会输出255的通道
13 * 13 上采用 和 26 * 26 进行拼接,26 * 26 的上采用和56 *56 的继续拼接(融合深层次网络的语义信息 以及 浅层网络细粒度的像素结构信息)
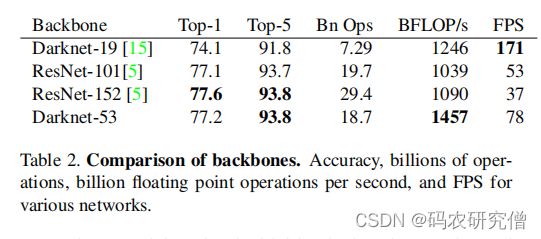
新网络比Darknet-19强大得多,但仍比ResNet-101或ResNet-152更有效。
下面是一些ImageNet的结果:
总体对小物体的预测比较精准
- 兼容不同尺度的输入
- Anchor通过聚类而不是人为指定
- 多尺度预测
- 损失函数惩罚项
- 网络架构通过Darknet - 53 以及 跨层连接和残差连接