【ctf】Crypto初步基础概要
在CTF界中,真正的Crypto高手只要一张纸一只笔以及Python环境就可以称霸全场了。(虽然是玩笑话但却是事实)
当然了,密码学是整个网络安全的基础,不管你是否参加ctf类的比赛,对于密码的常识也都需要掌握,希望接下来的内容对你有所收获,也希望可以进行学习和交流,另外欢迎各位师傅的指点,鄙人不才,还请各位师傅多包涵。
一个好的算法手或者数论基础极强的人经过编程培养定是优秀的Crypto选手,所以算法和数学能力尤为重要,同时Python编程功底也需要很强。当然了,现在越来越多的题目不仅仅是给你一个python文件pem文件等了,而是结合web渗透 亦或者misc流量分析等综合应用了。
通过目录很容易看出密码的主要分类,主要分为三大板块,分别是编码、古典密码、现代密码。而我这里将编码和古典密码的全部代码放在这里,就是为了更好地保存和分享,到时候遇到了直接运行代码了,后续也不再进行深入研究了,毕竟古典密码大多都是死的,没有太多的意义,但仍是要接触,这是密码的基本功,有人问我能不能直接进入现代密码学习,这当然也可以了,毕竟现在crypto题目大多也都是现代密码了,几乎不存在古典密码了。
而现代密码主要分为3类,分别是分组与序列密码(典型代表就是AES/DES) 公钥密码体系(典型重点就是RSA)哈希(典型就是md5,Sha256) 这些都非常值得研究的,也是我后面专题的必备内容,后面是继续加强现代密码的研究,特别是RSA专题。
本次使用环境的是Python 2.7,关于模块可以看import的内容。
CTF之Crypto学习
-
- 编码
-
- hex
- urlencode
- morsecode
- jsfuck
- *base家族
- 古典密码
-
- 移位密码
-
- *简单移位密码
- 云影密码
- *栅栏密码
- 替代密码
-
- *恺撒密码
- ROT13:
- 埃特巴什码:
- 培根密码:
- *仿射密码:
- 棋盘类密码:
- 维吉尼亚密码:
- 希尔密码:
- 现代密码
-
- 分组密码和序列密码:
-
- *DES/AES基本加解密:
- *分组密码CBC bit 翻转攻击
- 分组密码CBC选择密文攻击
- 分组密码CBC padding oracle攻击
- 公钥密码
-
- *RSA基础:
- 直接模数分解:
- 公约数模数分解:
- 小指数明文爆破
- 选择密文攻击
- 共模攻击
- 广播攻击
- 哈希
-
- 哈希碰撞:
- 哈希长度扩展攻击:
纯粹密码学题目被称为Crypto题目,有时候归为MISC。目前从赛事来看,密码学类型的题目开始趋向于PWN,Reverse类型的题目相结合。
需要较好的数学功底以及编程能力,同时具备跨领域能力,掌握Reverse PWN Web基本知识(结合较多,所以待我学习完Crypto后就直接进入Web学习模块了,如果还有实践将会看看PWN)
编码
编码是信息表达另一种表达方式,掌握各类编码转化技巧是密码学的基础。
hex
hex是最常用的编码方式之一,将信息转化为十六进制,使用python进行hex变换。将字符串转换为数字,可以通过int转化为十进制数。对于单字符来说也可以使用ord函数
s="flag"
print s.encode("hex")
t=s.encode("hex")
print int(t,16)
print ord("a") #只能对于字符来说
当解密运算结束以后,需要将数字转换为字符串:
num=584734024210391580014049650557280915516226103165
print hex(num)
print hex(num)[2:-1]
print hex(num)[2:-1].decode("hex")
使用十进制转换为十六进制字符串会自动补”0x",如果是long型,还会在后面自动补"L",所以将其去除就得到hex编码了,最后decode()。有两个问题,1.并不是所有数都会补L,2.decode必须保证hex字符串是偶数位否则在前面补0,下面是实现函数:
def num2str(num):
tmp=hex(num)[2:].replace("L","")
if len(tmp)%2==1:
return "0"+tmp.decode("hex")
else:
return tmp.decode("hex")
if __name__=="__main__":
print num2str(584734024210391580014049650557280915516226103165)
实际解题目过程中,可以通过PyCrypto库进行转换:
from Crypto.Util.number import long_to_bytes, bytes_to_long
flag="flag{123}"
print bytes_to_long(flag)
print long_to_bytes((bytes_to_long(flag)))
放个小插曲,我在pycharm安装pycrypto一直显示安装软件包失败,后来尝试安装pycryptodome才成功,我一直以为是pip的问题。
urlencode
编码用于浏览器和网站之间的数据交换,解决特殊字符的问题。这种编码只要再字符前置%即可。
例如如下:
flag{url_encode_1234_!@#$} flag%7Burl_encode_1234_%21@%23%24%7D
每遇到%的时候,连带%的三个字符对应着明文的一个字符,可以使用urllib两个函数进行urlencode:第一个quote函数对字符串进行url编码,可以使用unquote解码,urlencode能对字典模式的键值对进行url编码
import urllib
print urllib.quote("flag{url_encode_1234_!@#$}")
d={'name':'[email protected]','flag':'flag{url_encode_1234_!@#$}'}
print urllib.urlencode(d)
morsecode
摩斯电码是常见的编码方式,不存在密钥。
例如: …-./.-…/.-/–./–/—/.-./…/. (.短音 -长音 /分隔符)
通常morsecode和misc音频结合出题。(使用Cool edit)
摩斯在线解:上次做题特意使用了一下感觉没啥用,不如使用代码,下面附代码解析:
# 功能:摩斯密码加密&解密
# 介绍:
# 1. 输入时,每个密文需要以空格间隔开
# 2. 密文的字符需要变更为小数点和减号
# 3. 未在密码表的密文解密时会被替换成空格
# 4. 解密的结果进行了小写处理
encode_txt = "Py练习题/enco.txt" #加密表路径
decode_txt = "Py练习题/deco.txt" #解密表路径
def Exchange(target,char1,char2,char3):
'''交换字符串中的两种字符char1,char2'''
result = target.replace(char1,char3) #将char1替换成第三种字符
result = result.replace(char2,char1)
result = result.replace(char3, char2)
return result
# print(Exchange("..--- ...-- ...--",".","-","*")) #将.和-进行互换,*用来临时存储
def GetFile(path):
'''读取文件,返回字典对象'''
dic = dict()
txt = ""
with open(path, "r") as fp: # 文件读取
txt = fp.read()
lis_data = list(set(txt.split("\n"))) # 去重、分割
if "" in lis_data: #去空
lis_data.remove("")
for datas in lis_data:
key, data = datas.split(" ") # 分割
dic[key] = data
return dic
# print(GetFile(encode_txt))
# print(GetFile(decode_txt))
def MorseDecode(target):
'''摩斯密码解密'''
lis_target = list(target.split(" ")) #分割
dic = GetFile(decode_txt) #解密字典
result = "" #解密结果
for i in lis_target: #解密
if i in dic.keys(): #存在该密文时
result += dic[i]
else:
result += " "
return result
# print(MorseDecode(".---- ..---"))
def MorseEncode(target):
'''摩斯密码加密'''
dic = GetFile(encode_txt) #加密字典
result = "" #加密结果
for i in target: #遍历明文
if i in dic.keys(): #存在该明文时
result += " " + dic[i]
else:
result += " "
return result
# print(MorseEncode("233"))
if __name__ == '__main__': #主函数
while True:
print("==========================")
print(" 0. 退出 ")
print(" 1. 字符替换 ")
print(" 2. 摩斯加密 ")
print(" 3. 摩斯解密 ")
print("==========================")
flag = int(input("请选择:"))
if flag==1: #字符替换
target = input("字符串:")
ch = input("需要替换的字符:")
ch_replace = input("需要替换成什么:")
print("替换结果:",target.replace(ch,ch_replace))
elif flag==2: #摩斯加密
target = input("字符串:")
print("摩斯加密结果:",MorseEncode(target))
elif flag==3: #摩斯解密
target = input("字符串:")
print("摩斯解密结果1:",MorseDecode(target).lower())
print("摩斯解密结果2:",MorseDecode(Exchange(target,".","-","*")).lower())
else:
break
deco.txt:
.- a
-... b
-.-. c
-.. d
. e
..-. f
--. g
.... h
.. i
.--- j
-.- k
.-.. l
-- m
-. n
--- o
.--. p
--.- q
.-. r
... s
- t
..- u
...- v
.-- w
-..- x
-.-- y
--.. z
.- A
-... B
-.-. C
-.. D
. E
..-. F
--. G
.... H
.. I
.--- J
-.- K
.-.. L
-- M
-. N
--- O
.--. P
--.- Q
.-. R
... S
- T
..- U
...- V
.-- W
-..- X
-.-- Y
--.. Z
.---- 1
..--- 2
...-- 3
....- 4
..... 5
-.... 6
--... 7
---.. 8
----. 9
----- 0
enco.txt
a .-
b -...
c -.-.
d -..
e .
f ..-.
g --.
h ....
i ..
j .---
k -.-
l .-..
m --
n -.
o ---
p .--.
q --.-
r .-.
s ...
t -
u ..-
v ...-
w .--
x -..-
y -.--
z --..
A .-
B -...
C -.-.
D -..
E .
F ..-.
G --.
H ....
I ..
J .---
K -.-
L .-..
M --
N -.
O ---
P .--.
Q --.-
R .-.
S ...
T -
U ..-
V ...-
W .--
X -..-
Y -.--
Z --..
1 .----
2 ..---
3 ...--
4 ....-
5 .....
6 -....
7 --...
8 ---..
9 ----.
0 -----
jsfuck
jsfuck是有意思的编码方式,仅用6个字符可以书写js代码了。只需要: ()+[]!
*base家族
base64出镜率很高。

如果**最后是=那么就一定是base,**如果没有,看编码包含的字母 是否再对应的字符集上。
print "ZmxhZw==".decode("base64")
hex和base16只相差一个大小写。
在分析base64算法的时候,base64的算法是修改后的也就是私有base64.字符大小是1byte,也就是8bit,3byte也就有24bit。将24bit切成4份,每份6bit,转换数字后,在base64找到对应的字母即可,64bit正好代表64个字符,也就是说这种变换方式每3个字符变成了4个字符。

古典密码
古典密码作为最简单的密码加密类别,也是CTF常客了,对于数论要求不高很容易入门,是现代密码的基石。在形式上可以分为移位密码和替代密码。
移位密码
*简单移位密码
密码和编码最大的区别就是密码多了关键的信息:密钥K,一般用m表示明文,c代表密文。
例如:m=“flag{easy_easy_crypto}” k=“3124”
切分:flag {eas y_ea sy_c rypt o},按照3124的顺序进行密钥变化。

使用python进行加密算法:
def shift_encode(m,k):
c = ""
for i in range(0, len(m), len(k)):
m1 = [""]*len(k)
if i+len(k) > len(m):
temp = m[i:]
else:
temp = m[i:i+len(k)]
for j in range(len(temp)):
m1[int(k[j])-1] = temp[j]
c += "".join(m1)
return c
if __name__ == '__main__':
m = "flag{easy_easy_crypto}"
k = "3124"
print (shift_encode(m,k))
解密:
def shift_decode(c,k):
t = ""
for i in range(0,len(c),len(k)):
te=[""]*(len(k)+1)
if i + len(k) > len(c):
tem_m=c[i:]
use=[]
for j in range(len(tem_m)):
use.append(int(k[j])-1)
use.sort()
for j in range(len(tem_m)):
te[j]=tem_m[use.index(int(k[j])-1)]
t+="".join(te)
else:
tem_m=c[i:i+len(k)]
for j in range(len(tem_m)):
te[j]=tem_m[int(k[j])-1]
t+="".join(te)
return t
if __name__=="__main__":
c = "lafgea{s_eyay_scyprt}o" # flag{easy_easy_crypto} lafg 3124 s[i] = temp[int(k[i]] 3124 : 1234
# te[0]=tem_m[2] te[1]=tem_m[0] te[2]=tem_ms[1] te
# }o*****
#
k = "3124"
print shift_decode(c,k)
云影密码
云影密码仅包含01248数字,其中0用于分隔,其余数字用于做加和操作之后转换为明文。
python代码:
def yunying_decode(c):
t="abcdefghijklmnopqrstuvwxyz"
l=c.split("0")
r=""
for i in l:
tep=0
for j in i:
tep+=int(j)
r+=t[tep-1]
return r
if __name__ =="__main__":
print yunying_decode("8842101220480224404014224202480122")
*栅栏密码
加密:
def zhalan_encode(m,k):
chip = []
for i in range(0,len(m),k):
chip.append(m[i:i+k])
c = ""
for j in range(k):
for ch in chip:
if j < len(ch):
c += ch[j]
return c
print zhalan_encode("flag{zhalan_mima_hahaha}",4)
解密:
当然了,一般都是爆破,可以去网站进行相应的爆破
# 栅栏密码解密:
def zhalan_decode(c,k):
l=len(c)
m=[""]*l
pare=l/k
if l%k!=0 :
pare += 1
for i in range(0,len(c),pare):
if i+pare >= l:
temp=c[i:]
else:
temp=c[i:i+pare]
for j in range(len(temp)):
m[j*k+i/pare]=temp[j]
return "".join(m)
print zhalan_decode("f{lm_alzaihhahnmaaga_ah}",4)
替代密码
替代密码,首先建立一个替换表,加密事将需要加密的明文以此通过查表替换为相应的字符.分为单表替代密码和多表替代米密码.针替代密码最有效的攻击方式是词频分析.
*恺撒密码
单表替代密码,通过将字母一定的位数来实现加密和解密,移动的位数称为偏移量.
所以位数就是恺撒密码的密钥,只考虑可见字符,并且都为ascii码,所以128为模数.
加密:
def caser_encode(m,k):
c=""
for i in m:
c+= chr((ord(i)+k)%128)
return c
print caser_encode("flag{kaisamima}",3)
解密:
def caser_decode(c,k):
m=""
for i in c:
m+= chr((ord(i)-k)%128)
return m
print caser_decode("iodj~ndlvdplpd\x00",3)
针对单表替代密码攻击方法本来就是词频分析,但是密钥取值太小了,所以可以直接爆破.
例如: c=“39.4H/?BA2,0.2@.?J”
def caser_decode_boom(c):
for k in range(1,129):
m=""
for i in c:
m+=chr((ord(i)-k)%128)
if "flag" in m:
return m
print caser_decode_boom("39.4H/?BA2,0.2@.?J")
有一些凯撒密码是仅只转换英文字母的,所以可以使用下面的程序跑一下,特点是有{}符号了,这是我做题时候发现的:
def caser_decode_boom(c):
c=c.lower()
# print c
for k in range(0,27):
m=""
for i in c:
if ord(i) >= 97 and ord(i) <= 122:
m += chr((ord(i)-k)%128)
else:
m += i
# print m
if "flag" in m:
return m
print caser_decode_boom("synt{5pq1004q-86n5-46q8-o720-oro5on0417r1}")
如果不知道flag格式的话,可以打印出所有结果通过肉眼观察具有语言逻辑.标志:看到{}可以猜想此密码,拿到密码先和ascii码进行比较
凯撒爆破器 https://zh.planetcalc.com/1434/ 链接
ROT13:
在恺撒密码中,有一个特例,当k=13,只作用于大小写英文字母的时候称为ROT13,准确地来说它是一种编码,是ctf的常客.
通常会作用于md5, flag等字符串上,而我们都知道,md5字符只有ABCDEF,对应的ROT13为NOPQRS,flag对应的是SYNT
埃特巴什码:
替代表是通过对称获得的.将字母表的位置完全镜面对称获得字母的替代表:
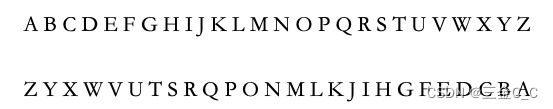
上述密码都是单表替代密码的特例,因为单表替代,所以没有替代表的时候爆破的难度会较高.
一般来说会给出有语言意义的密文使用词频分析来进行攻击
培根密码:
培根密码一般使用两种不同的字体表示密文,关键是字体,使用AB代表两种字体,5个一组表示密文

*仿射密码:
替代表的生成方式依据:c=(am+b )mod n. m为明文对应的数字,n为字符量,c为密文,a和b为密钥
密钥:k = (m, n)
C = Ek(m) = (k1*m + k2) mod n ;
M = Dk(c) = k3(c-k2) mod n (其中(k3×k1) mod 26 = 1);
模逆:
3*7 = 21; 21 % 20 = 1 ; 所以3,7 互为 20 的 模逆.
9*3 = 27; 27 % 26 = 1 ; 所以9,3 互为 26 的 模逆.
def affine_encode(m,a,b,origin="abcdefghijklmnopqrstuvwxyz"):
r=""
n=len(origin)
for i in m:
if i in origin:
r += origin[(a*origin.index(i)+b)%n]
else:
r += i
return r
print affine_encode("affinecipher",5,8)
在拥有密钥的情况下,解密只需要求出a关于n的逆元即可,即m=modinv(a)*(c-b)mod n
import primefac
def affine_decode(c,a,b,origin="abcdefghijklmnopqrstuvwxyz"):
r = ""
n = len(origin)
mov=primefac.modinv(a,n)%n
for i in c:
if i in origin:
r += origin[(mov*(origin.index(i)-b)%n)%n]
else :
r += i
return r
print affine_decode("ihhwvcswfrcp",5,8)
因为明密文空间一样,n很容易得知,那么在没有密钥的情况下一般有以下思路:1.爆破,在密钥空间小的时候可以这样做;2.也可以使用词频统计进行攻击 3.已知明文攻击,如果知道了任意两个字符的明密文对,可以推出密钥ab:
c1=(am1+b) mod n
c2=(am2+b) mod n
a=(c1-c2) * modiv (m1-m2) % n
import primefac
def affine_mc_guess(m1,c1,m2,c2,origin="abcdefghijklmnopqrstuvwxyz"):
d1 = origin.index(m1)
d2 = origin.index(c1)
d3 = origin.index(m2)
d4 = origin.index(c2)
n = len(origin)
dx=primefac.modinv(d1-d3,n)%n
a=dx*(d2-d4) % n
b=d2 - a*d1
return (a,b)
print affine_mc_guess("a","i","f","h")
棋盘类密码:
棋盘类密码我看的是一头雾水,建议不要花时间在上面了。
playfair polybius Nihilist属于棋盘类密码,密钥为5*5的棋盘.棋盘生成规则:顺序随意 不出现重复字母 i和j可视为同一个字,也有将q去除的保证总数为25个. 生成棋盘的方式如下:
def map_encode(m,use_q=True,use_low=True):
m = m.upper()
k=""
origin="ABCDEFGHIJKLMNOPQRSTUVWXYZ"
# 首先对m进行append 再补全
for i in m:
if i not in k:
k += i
for i in origin:
if i not in k:
k += i
if use_q==True:
k=k[0:k.index("J")]+k[k.index("J")+1:]
else:
k=k[0:k.index("Q")]+k[k.index("Q")+1:]
if use_low==False:
k=k.lower()
assert len(k)==25
re=[]
for i in range(5):
re.append(k[i*5:i*5+5])
return re
print map_encode("helloworld")
playfair 根据明文的位置寻找新的字母,首先将明文字母两两一组进行划分,并按照如下进行加密:
1.若两个字母不同行不同列,则需要在矩阵中找出另外两个字母(第一个字母对应行优先)
2.若两个字母同行,则取这两个字母右方的字母(若字母在最右方则取最最左方的字母)
3.若两个字母同列,则取这两个字母下方的字母(若字母在最小方则取最上方的字母)
针对两个字符的变换方式如下:
def player_fair(tmp,map):
for i in range(5):
for j in range(5):
if tmp[i][j]==tmp[0]:
ai=i
aj=j
if tmp[i][j]==tmp[1]:
bi=i
bj=j
if ai==bi:
axi=ai
bxi=bi
axj=(aj+1)%5
bxj=(bj+1)%5
elif aj==bj:
axj=aj
bxj=bj
axi=(ai+1)%5
bxi=(bi+1)%5
else:
axi=ai
axj=aj
bxi=bi
bxj=bj
return map[axi][axj]+map[bxi][bxj]
Polybius密码相对简单一点,只是用棋盘的坐标作为密文,可能 不一定是数字,坐标可以用字母表示.
加密:
def polybius_encode(m,k="",name="ADFGX",cheese_map=[]):
m=m.upper()
assert k!="" or cheese_map !=[]
if cheese_map==[]:
map=map_encode(k)
else:
map=cheese_map
r=[]
for x in m:
for i in range(5):
for j in range(5):
if map[i][j]==x:
r.append(name[i]+name[j])
return r
print polybius_encode("helloworld",k="abcd")
维吉尼亚密码:
标准的多表替代密码.密钥不再是固定的,而是随着位置发生改变.破解必须依赖爆破+词频统计的方法来进行
希尔密码:
运用基本矩阵论原理的替换密码,将每个字母当作二十六进制数字:A=0 B=1,依次类推,将一串字母当作n维向量,与n*
n的矩阵相乘,再将结果Mod 26
现代密码
分组密码和序列密码:
分组密码是将明文消息编码后的bit序列,按照固定长度分组.序列密码是利用一个初始密钥生成一个密钥流然后对明文进行加密.
*DES/AES基本加解密:
DES属于迭代型密码,分组长度为64bit 密钥长度为64bit 圈数为16 圈密钥长度为48bit
AES属于迭代型分组密码,分组长度128bit ,密钥长度为128 圈数为10
有两种加解密模式:一种是ECB模式 一种是CBC模式.
对AES进行介绍,使用PyCrypto进行加解密:
from Crypto.Cipher import AES
m="flag{aes_666666}"
key="1234567890abcdef"
iv="fedcba0987654321"
ciper=AES.new(key,AES.MODE_CBC,iv)
c=ciper.encrypt(m)
print c.encode("hex")
ciper=AES.new(key,AES.MODE_CBC,iv)
m=ciper.decrypt(c)
print m
因为密文包含不可见字符所以在输出时候使用了Hex编码
*分组密码CBC bit 翻转攻击
ECB:基础的加密模式 密文被分割成分组长度相等的块,然后逐个加密并逐个输出组成密文
CBC:循环模式 前一个分组的密文与当前分组的明文进行异或操作后再加密.
在CBC模式下,明文分组并与前一组密文进行异或操作的模式造就 了CBC模式的bit翻转攻击。
在CBC模式的密文中,在不知道密钥的情况下,如果我们有一组明 密文,就可以通过修改密文,来使密文解密出来的特定位置的字符变 成我们想要的字符了。
以明文“hahahahahahahaha=1;admin=0;uid=1“为例:
16字节为一组,实际上被分成了2组.对第一组进行加密,并与初始向量Iv进行异或操作,再对第二组进行加密,并与第一组密文进行异或操作.
将admin=0改成admin=1,已知明文和密文相同,写一个攻击函数:
from Crypto.Cipher import AES
# pos tar是两个长度相同的list pos代表想要改变的字符在明文中的位置从0开始 tar想要改变的字符
def cbc_bit_attack_mul(c,m,position,target):
l=len(position)
r=c
for i in range(l):
change=position[i]-16
tmp=chr(ord(m[position[i]])^ord(target[i])^ord(c[change]))
r=r[0:change]+tmp+r[change+1:]
return r
m="hahahahahahahaha=1;admin=0;uid=1"
key="1234567890abcdef"
iv="fedcba0987654321"
ciper=AES.new(key,AES.MODE_CBC,iv)
c=ciper.encrypt(m)
print c.encode("hex")
c_new=cbc_bit_attack_mul(c,m,[16+10-1],['1'])
ciper=AES.new(key,AES.MODE_CBC,iv)
m=ciper.decrypt(c_new)
print m
分组密码CBC选择密文攻击
通过CBC选择密文攻击,可以很快恢复AES的向量iv.CBC模式下,明文每次加密前都会与IV异或,每组·iv都会更新上一组密文

def cbc_chosen_ciper_recover_iv(cc,mm):
assert cc[0:16]==cc[16:32]
def _xorstr(a,b):
s=""
for i in range(16):
s+=chr(ord(a[i])^ord(b[i]))
return s
p0=mm[0:16]
p1=mm[16:32]
return _xorstr(_xorstr(p0,p1),cc[0:16])
print cbc_chosen_ciper_recover_iv("1"*32,"3eXZvNanqYff/kGAyqkX J4Wi1eaC78ffnZAU0JX/Q2Q=".decode("base64"))
分组密码CBC padding oracle攻击
我这个很迷,后期再补上吧
满足如下条件: 1.加密时采用PKCS5的填充 2.攻击者可以和服务器交互,可以获取密文.利用服务器通过对padding检查时的不同回显进行的,这是一种侧信道攻击.利用服务器对padding的检查,可以从末位开始爆破明文.
Feistel结构分析:
如果右边的加密是线性的,那么可以实现已知明文攻击.
攻击伪随机数发生器
设计思想:将种子密钥通过密钥流生成器产生的伪随机序列与明文简单结合成密文.
公钥密码
*RSA基础:
关于RSA基础我将单独做一期,并分析相应的题目,这是非常重要的算法。
这里就不给出相应的算法基础了,直接放比较常见的攻击方法了。
关于RSA算法可以看我这篇博客,里面从数论入手再讲到RSA。点击此处
不直接给出数字,可以使用openssl的命令来读取pem文件中的信息:
查看公钥文件的命令
openssl rsa -pubin -in pubkey.pem -text -modulus
解密结果如下:
rsautl -decrypt -inkey private.oem -in flag.enc -out flag
直接模数分解:
大数分解问题: 推出神器yafu ,开源模数分解神器: https://sourceforge.net/projects/yafu/
pycrypto提供了用于生成大素数,素性检测等的函数,代码如下:
from Crypto.Util.number import long_to_bytes,bytes_to_long,getPrime,isPrime
p=getPrime(128) # 生成的大素数的bit位
q=getPrime(128)
n=p*q
print p
print q
print n
命令行打开yahu使用factor(n)来分解n
费马分解和Pollard_rho分解:

公约数模数分解:
如果不小心在两次通信中生存的大素数有一个是相同的,那么攻击者可以对两次通信的n进行公约数的计算进而分解n.
这种攻击适用于多组加密过程,并且e为65537,同时n都很大.
通过最大公约数计算得到n1 和 n2 都有一个共同的素因子p,那么接下来的工作就简单了.通过n1 n2去除素因子p,可以成功分解n1和n2.
def modinv(a,n):
return primefac.modinv(a,n)%n
p1=primefac.gcd(n1,n2)
p2=p1
q1=n1/p1
q2=n2/p2
e1=e2=65537
d1=modinv(e1,(p1-1)*(q1-1))
d2=modinv(e2,(p2-1)*(q2-1)
m1=pow(c1,d1,n1)
m2=pow(c2,d2,n2)
其它模数分解方式
借助网站http://factordb.com/index.php
nnp值为(p+2)*(q+2)
小指数明文爆破
如果使用的e太小了,比如e=3,m也很小,而n很大,会出现pow(m,e) 可以对任意密文解密,但不能对C解密,可以使用选择密文攻击,首先求出C在N上的逆元C-1,求C-1的明文M’,M’即为明文的逆元,再次求逆即可. 在两次通信中使用了相同的n,而alice是对相同的m加密,在这种情况下可以不计算d而算出m 假设加密的信息都是相同的 hash,散列,杂凑函数.把任意长度的输入通过哈希算法变换成固定长度的输出,该输出值就是哈希值. 转换就是压缩映射,即哈希值的空间远小于输入的空间.常见的MD5 sha1 sha256 哈希函数H满足如下性质: H能够应用到任何大小的数据块; H能够生成大小固定的输出;对于任意给定的x, H(X)计算很简单,但从H(x)逆推是不可能的. 举例:环境题,连过去之后首先是一个Proof Of Work,内容由4个可打印字符组成,要求其hash值(注意hash方法会变化)的前20个字符为特定内容。 通过程序爆破即可: 或者使用如下代码: 在碰撞完的两个不同内容的串后面加入相同的字符后,两者的哈 希还是相同的,这也是一个常见考点。 计算hash的方式secret+message为明文的情况下,可以进行哈希长度扩展攻击,使攻击者在不知道secret情况下修改message并得到另外一个hash值 哈希扩展攻击的神器:hashpump进行计算,安装hashpump 这部分实在有难度,单纯靠这个讲不完,后续将放专题! 以上就是目前关于的Crypto的内容了,想必看到了这里你对密码学也有了认识,那么可以继续关注后面将附有专题现代密码分析。选择密文攻击
如果存在交互可以对任意密文进行解密,并获取1Bit的话,可以实现RSA parity oracle攻击.共模攻击
前提是: 两组及以上 而且两次的m和n是相同的,那么cat可以通过计算算出m广播攻击

相关消息攻击
使用同一公钥对两个具有某种线性关系的消息M1和M2进行加密,并将加密后的消息发送给对方,可以获得对应的消息M1,M2.假设模数为N,两者线性关系为M1=aM2+b,当e为3时,可以得到:

DSA:
还会考察椭圆曲线 离散对数等问题哈希
哈希碰撞:
python中一般使用hashlib函数,如果将hash变成字符串的话需要配合hexdigest使用
推荐md5解密: cmd5.comimport hashlib
print hashlib.sha256("hello").hexdigest()
print hashlib.md5("hello").hexdigest()
print hashlib.sha1("hello").hexdigest()
salt="123456"
hashlib.sha256(salt+x).hexdigest()[0:6]=="123456"
import string
import hashlib
salt="fIEkfuYc1Sh367vR"
for a in string.printable:
for b in string.printable:
for c in string.printable:
for d in string.printable:
if hashlib.sha256(salt+a+b+c+d).hexdigest() == "a4c1d700b944e3a066d0d7ac843077a6aacee694a2dd54bbb294fe9aae08b26e":
print salt+a+b+c+d
import hashlib
import random
s1 = "fIEkfuYc1Sh367vR"
res = "a4c1d700b944e3a066d0d7ac843077a6aacee694a2dd54bbb294fe9aae08b26e"
dir = ["a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z",
"A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","U","V","W","X","Y","Z",
"0","1","2","3","4","5","6","7","8","9"]
def cat():
for a in dir:
for b in dir:
for c in dir:
for d in dir:
xxxx = a+b+c+d
out = hashlib.sha256((xxxx+s1).encode('utf-8')).hexdigest()
if out == res:
print xxxx
return 0
cat()
print hex(random.getrandbits(128))
# Vojl
# 0x31929230e5152963fb20a6d49ba39562L
哈希长度扩展攻击:
sudo apt-get install git
git clone https://github.com/bwall/HashPump.git
apt-get install g++ libssl-dev
cd HashPump
make
sudo make install