Retrieval-Augmented Generative Question Answering for Event Argument Extraction论元解读
Retrieval-Augmented Generative Question Answering for Event Argument Extraction

code:xinyadu/RGQA (github.com)
paper:https://arxiv.org/pdf/2211.07067.pdf
期刊/会议:EMNLP 2022
摘要
长期以来,事件论元抽取一直被研究为基于抽取的方法的序列预测问题,孤立地处理每个论元。尽管最近的工作提出了基于生成的方法来捕获交叉论元依赖性,但它们需要生成和后处理复杂的目标序列(模板)。受这些观察和最近预训练的语言模型从演示中学习的能力的激励。我们提出了一种用于事件论元抽取的检索增强生成QA模型(R-GQA)。它检索最相似的QA对,并将其作为当前示例上下文的提示,然后将论元解码为答案。我们的方法在各种设置(即完全监督、领域转移和少样本学习)中大大优于现有方法。最后,我们提出了一种基于聚类的采样策略(JointEnc),并对不同策略如何影响少样本学习性能进行了深入分析。
1、简介
许多文档报告了与现实世界中常见情况相对应的事件序列。不同角色的论元提供了对事件的精细理解(例如个人、组织、位置),也影响了事件类型的确定。与检测事件的触发词(通常是动词)相比,提取论元涉及识别句子中不同角色的提及跨度(由多个单词组成)。我们在图1中列出了一个示例,给定上下文和事件类型(提及),应提取三个角色(即PERSON、POSITION、AGENT)的所有论元。
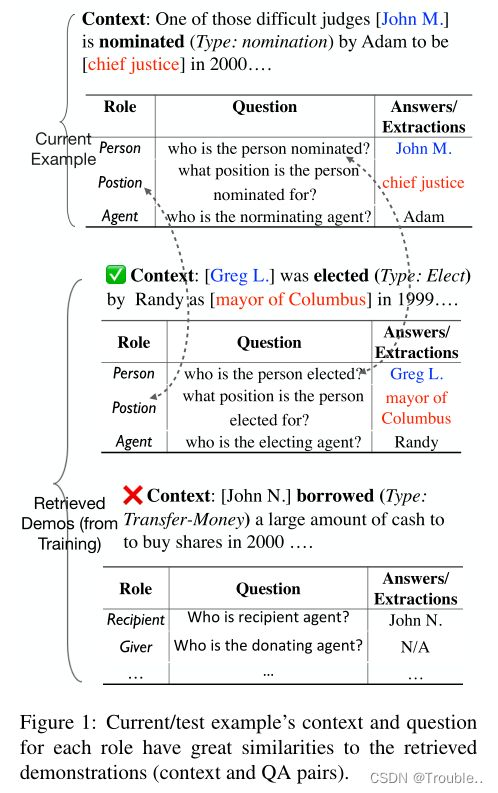
为了克服提取模型的错误传播并有效捕获跨角色依赖,提出了基于端到端模板生成的信息提取方法。然而,它们(1)受到密集输出模板格式(较少的训练实例)的影响,并且不能利用受限模板充分利用角色之间的语义关系;(2) 无法在类似的输入输出对上释放大型预训练模型的优秀类比能力,以产生抽取结果。
根据我们在真实环境中的观察,示例通常与其他示例有很大的相似性(在语法和语义方面)(图1)。在这个图中,我们有一个提名事件的当前输入上下文“……困难的法官John M.被提名……”。当在大型商店(例如训练集)中搜索示例以进行演示(输入输出对)时,将显示两个最相似的示例的输入输出对。检索到的两个示例的上下文与当前示例的上下文具有很大的语义相似性。第一个检索到的示例的问题(针对每个角色)也与输入示例匹配。第二个例子的问题没有。因此,帮助模型确定从演示中学习“多少”也很重要。
受先前方法的弱点和我们的观察结果的启发,我们引入了一种用于事件论元抽取的可检索增强生成问题回答模型(R-GQA)。首先,我们将事件抽取公式化为生成性问答任务,使模型能够同时利用问答(利用标签语义)和文本生成,并且不需要阈值调整。我们在两种设置(1)完全监督设置和(2)域转移设置上进行了实验。从经验上讲,我们的方法大大优于以前的方法(提取QA和基于模板生成的方法)(贡献1)。
为了使我们基于大型预训练模型的生成模型能够从类似的表述中明确学习(“原因”)作为提示,我们在模型中添加了一个检索组件。它使用相似性/类比评分来决定在多大程度上依赖检索到的演示。它在两种设置中都显著优于生成QA模型(我们提出的没有检索组件的基线)(贡献2)。此外,我们还研究了各种模型在少样本抽取设置中的性能。据我们所知,当训练/评估的示例被随机抽样时,在性能方面存在很大的差异,导致不同的方法不可比较。因此(1)我们研究了在不同采样策略(例如,随机、基于聚类)的少样本事件抽取设置中模型的行为,以及模型性能和分布距离(真实数据和采样数据之间)如何对应;(2) 我们设计了一种基于聚类的采样策略(JointEnc),它通过利用上下文和触发词嵌入来选择最具代表性(未标记)的示例。它比随机抽样和一轮主动学习要好。我们对采样方法的讨论有助于提高基准模型的少样本设置性能(贡献3)。
2、问题描述和定义
事件本体、模板和问题:我们专注于从一系列单词中提取事件论元。事件由(1)触发词和事件的类型( E E E)组成;(2) 事件类型 E E E的相应论元 { a r g 1 E , a r g 2 E , . . . } \{ arg_1^E,arg_2^E,...\} {arg1E,arg2E,...}。事件类型和论元角色都在本体中预定义。除了事件类型和论元角色之外,本体还为论元角色提供定义和模板。例如,当 E = M o v e m e n t − T r a n s p o r t a t i o n − E v a c u a t i o n E=Movement-Transportation-Evacuation E=Movement−Transportation−Evacuation时,提供论元角色的模板,
[ a r g 1 ] [arg_1] [arg1] transported [ a r g 2 ] [arg_2] [arg2] in [ a r g 3 ] [arg_3] [arg3] from [ a r g 4 ] [arg_4] [arg4] place to [ a r g 5 ] [arg_5] [arg5] place.
基于本体中的论元角色和模板的定义,我们可以基于Du和Cardie中提出的机制为每个论元角色生成常规的问题。例如,在本例中, a r g 1 ( T r a n s p o r t e r ) arg_1 (Transporter) arg1(Transporter):“who is responsible for transport”, a r g 2 ( P a s s e n g e r ) arg_2 (Passenger) arg2(Passenger):“who is being transported”, a r g 3 ( V e h i c l e ) arg_3 (Vehicle) arg3(Vehicle):“what is the vechile used”, a r g 4 ( O r i g i n ) arg_4 (Origin) arg4(Origin):“where the transporting originated”, a r g 5 ( D e s t i n a t i o n ) arg_5 (Destination) arg5(Destination):”where the transporting is directed“。
演示样本(Demonstrations Store):Brown等人提出使用上下文内演示(输入输出对)作为提示来测试大型预训练语言模型的零样本性能。对于我们的检索增强方法,我们表示要从 S T ST ST中选择的一组Demonstrations Store/提示。在这项工作中,我们使用训练集启动 S T ST ST。
数据和采样策略:在完全监督的环境中,我们使用整个训练集(1)来训练模型;(2) 作为Demonstrations Store。
在少样本设置中,出于减少标注成本的需要,我们假设只有固定的预算用于注释 K K K个示例的训练论元,并将标注子集称为 S f e w S_{few} Sfew。然后,我们使用 S f e w S_{few} Sfew作为训练集和Demonstrations Store
3、方法
我们首先描述了检索增强生成问答模型(图2),包括(1)生成模型以及如何构建Demonstrations(提示)以及最终输入和目标序列;(2) 训练、解码、后处理细节;以及它们与基于模板生成的模型的区别。然后,我们介绍了基于聚类的采样策略,以使少样本设置的训练示例多样化。
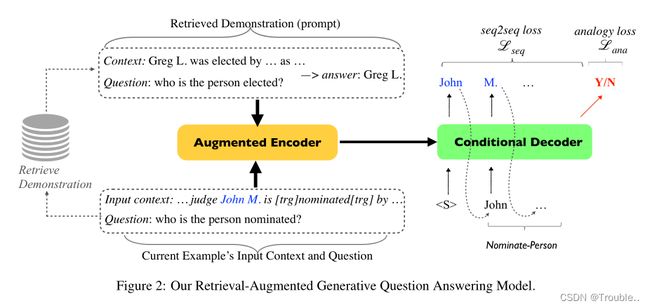
3.1 检索增强生成问答
BART是基于Vaswani等人的大型预训练编码器-解码器 transformer 架构。其预训练目标是重建原始输入序列(去噪自动编码器)。此前的工作报告称,这一目标有助于解决抽取问题。因此,我们使用预训练的BART作为基础模型。如图2所示。对于每个论元角色,R-GQA模型的输入 x x x都取决于(1)当前示例的上下文;(2)角色的问题 (3) Demonstrations Store S T ST ST。我们将在下面解释详细信息。正确序列 y y y基于当前训练实例的正确的论元跨度。其目的是找到 y ^ \hat y y^,
y ^ = a r g m a x y p ( y ∣ x ) \hat y=\mathop {argmax} \limits_{y} \ p(y|x) y^=yargmax p(y∣x)
其中 p ( y ∣ x ) p(y|x) p(y∣x)是给定输入 x x x的预测论元序列 y y y 的条件对数似然。
为了构建 x , y x,y x,y,除了BART词汇表中标记的特殊标记——包含分割token([sep]),序列的开始/结束 token( < s > , < / s > ,\ <s>, </s> )。我们新添加三个token:[demo]、[tgr]、[sep_arg]。更详细地讲:[demo]表示输入序列的哪个部分是陈述/提示,[trg]标志输入上下文事件触发词,[sep_arg]用于分隔正确的token论元。
给出一个案例(包含文本内容和触发词),对于事件类型 E E E的每一个论元角色,输入格式如下所示,我们实例化所有的组件以获得最终的输入序列:
x = < s > [ d e m o ] x=\ [demo] x=<s> [demo] Demonstration [ d e m o ] [demo] [demo] Question [ s e p ] [sep] [sep] Input Context < / s > </s>
"Question"来自于各个本体(第二节)的问题集合;“Input Context”我们使用标记 [ t r g ] [trg] [trg]当前的示例的触发词强调。对于图2的示例,输入的上下文将变成“… John M is [trg] nominated [trg] by …”。
至于“Demonstration”,我们首先从demonstration store ( S T = { d 1 , d 2 , . . . } ) (ST=\{ d_1,d_2,...\}) (ST={d1,d2,...})中选择 d r d_r dr,它和当前问题和输入上下文最相似,他是一个 ( < Q u e s t i o n , C o n t e x t > , A r g u m e n t s ) (
Demonstration d r d_r dr= Q r Q_r Qr [sep] C r C_r Cr [sep] The answer is: A r A_r Ar.
我们使用S-BERT来计算当前实例和 S T ST ST中所有 demonstration 之间的相似性分数。S-BERT是BERT模型的修改,该模型使用语义和三元组网络结构来获得单词序列的语义意义嵌入。
为了构建目标(序列),我们首先确定要从 demonstration 中学习多少——如果相似度得分高于阈值(由 dev set 确定),并且demonstration 和当前实例都有非空答案,那么我们将 1(Y)分配给 y a n a l o g y y_{analogy} yanalogy,否则为 0(N)。然后我们用[sep_arg]连接角色的所有论元跨度,以构造 y s e q 2 s e q y_{seq2seq} yseq2seq,
y s e q 2 s e q = < s > A r g u m e n t 1 [ s e p a r g ] A r g u m e n t 2 [ s e p a r g ] . . . < / > y_{seq2seq} =\ Argument_1 \ [sep_arg] \ Argument_2 \ [sep_arg] \ ... yseq2seq=<s> Argument1 [separg] Argument2 [separg] ...</>
最终的 y y y应该包含 y s e q 2 s e q , y a n a l o g y y_{seq2seq},y_{analogy} yseq2seq,yanalogy。
3.2 训练和推理
训练:在准备好 S = { ( x ( i ) , y ( i ) ) } i = 1 ∣ S ∣ S=\{ (x^{(i)},y^{(i)}) \}_{i=1}^{|S|} S={(x(i),y(i))}i=1∣S∣。损失函数将被定义如下:
L = L s e q 2 s e q + L a n a a l o g y L s e q 2 s e q = − ∑ i = 1 ∣ S ∣ l o g p ( y s e q 2 s e q ( i ) ∣ x ( i ) ; θ ) = − ∑ i = 1 ∣ S ∣ ∑ j = 1 ∣ y s e q 2 s e q ∣ ( i ) l o g p ( y j ( i ) ∣ x ( i ) ; y < j ( i ) ; θ ) L=L_{seq2seq}+L_{anaalogy} \\ L_{seq2seq}=-\sum_{i=1}^{|S|} log p(y_{seq2seq}^{(i)}|x^{(i)};\theta) \\ =-\sum_{i=1}^{|S|} \sum_{j=1}^{|y_{seq2seq|}^{(i)}} log p(y_{j}^{(i)}|x^{(i)};y_{
L s e q 2 s e q L_{seq2seq} Lseq2seq是解码器的输出和目标序列 y s e q 2 s e q y_{seq2seq} yseq2seq之间的交叉熵损失。 L a n a l o g y L_{analogy} Lanalogy是用最终解码器token的最终隐藏状态计算的二分类交叉熵损失。
推理和后处理:在测试时,我们进行贪心策略解码以获得目标序列,然后使用[seq_arg]进行分割。由于还需要获取输入上下文中论元的偏移量,因此我们会自动将候选论元的跨度与输入上下文匹配。然后,如果没有匹配的跨度,我们丢弃候选论元;如果有多个匹配,我们选择最接近触发词的一个。例如,如果输入上下文是“One of those diffcult judges [John M.] is nominated (Type: nomination) by Adam to be chief justice in 2000… [John M.] started office on … ”,并且PERSON这个角色有两种候选论元(括号内),那么我们使用第一位候选论元的补偿。与我们的方法不同,基于模板的生成方法生成的序列类似于第2节中的序列——导致模型(1)没有充分利用事件类型之间角色的语义关系;(2) 需要更复杂的后处理,包括从生成的模板获取论元的附加步骤。
3.3 少样本设置和采样策略

在少样本设置中,我们假设我们有预算为有限数量的示例论元(所有示例的5%-20%)获取标注以用于训练。我们将少数训练示例集表示为 S f e w S_{few} Sfew。我们研究了(1)不同的采样策略如何影响 S f e w S_{few} Sfew的分布和模型的性能;(2) 如何选择最好的一组示例(零轮或一轮),并对其进行标注以进行训练,从而在测试时获得更好的性能。
我们提出一个采样方法叫做JointEnc。它使用k-means算法聚类输入上下文和触发词的嵌入。与一轮主动学习设置相比,这更容易实现,因为我们的方法不需要迭代训练/测试来选择未标记的示例。算法1中详细说明了我们如何获得 S f e w S_{few} Sfew。具体来说,我们首先为每个未标记的示例获得上下文和触发文本的嵌入(第3-6行)。然后我们对嵌入进行基于k_means的聚类(第7行)。最后,我们计算了所有集群中示例的比例;并将每个簇的相应数量的示例添加到 S f e w S_{few} Sfew(第8-12行)。
4、实验和分析
我们在两个数据集上进行了实验,并在三种设置中将我们的模型与基线进行了比较:(1)全监督设置;(2)领域迁移设置;(3)少样本训练设置。
4.1 数据统计和评估
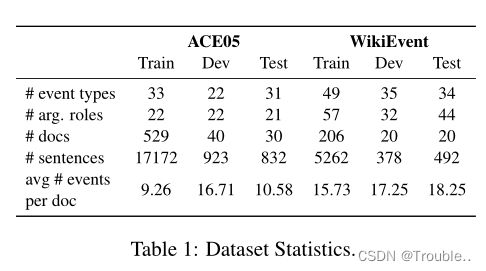
使用Precision§、Recall®、F-measure(F1) score评估指标。
4.2 Baseline
EEQA、GenIE、Generative QA。
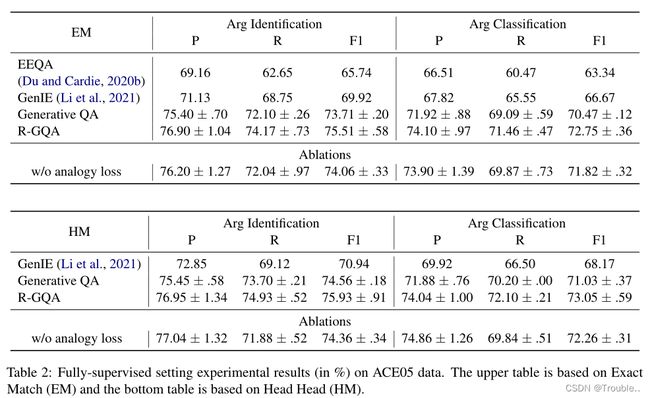
4.3 全监督设置结果
4.4 R-GQA如何在领域迁移设置中执行
为了模拟真实世界的设置,我们检查了模型对测试新本体集(事件类型和论元类型)的可移植性。更具体地说,我们在ACE05(有33种事件类型)上进行训练,并在WikiEvent数据集(有50种事件)上进行测试。
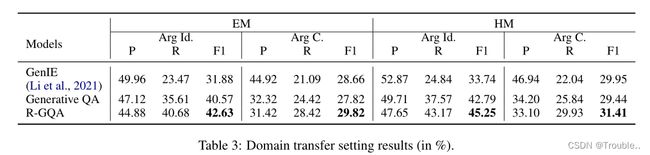
在表3中,我们展示了领域迁移的结果。对于这种新设置,与完全监督的设置相比,最佳方法在WikiEvent上的性能降低了约20%(F1)。主要原因是:(1)与ACE05相比,WikiEvent数据集更为困难——各模型的性能下降约5-10%F1;(2) WikiEvent的测试集包含许多不同于ACE05现有事件/论元类型的事件/论元。因此,我们发现明显事件类型的数据子集的性能大幅下降。我们在附录B中列出了这些类型。当比较基于QA的生成模型和GenIE时,我们观察到(1)基于QA的模型的召回率显著较高(>10%)——导致了大参数识别性能的提高;而我们的模型没有在precision上大优势。但总体性能(F1)始终更高;(2) 我们的R-GQA模型的检索组件有助于模型生成更多论元,并改进R和F1。
4.5 R-GQA在少样本设置中的表现如何以及采样策略的影响

我们展示了不同采样方法(包括一轮主动学习设置)的结果,以找出事件论元抽取任务标注(具有固定预算)的更重要因素。也就是说,我们使用以下策略从“未标记”的示例中进行采样:随机选择(几乎)匹配测试集中事件类型分布的示例;AL是一种基于一轮主动学习的方法——基本上,一个模型是在100个带有标注的示例上训练的,并选择最具挑战性(模型最不确定)的未标记示例。我们的JointEnc策略首先对未标记的示例进行聚类(基于输入上下文和触发词文本),并从每个集群中选择与每个集群的大小成比例的#个示例;上下文也进行类似于JointEnc的基于聚类的采样但是仅根据上下文嵌入每个示例。
对于采样量增加的少样本设置,我们计算了从每个策略采样的样本分布与真实数据分布(由带标签的训练数据表示)之间的 Hellinger 距离(Beran,1977)。距离如图3所示。我们观察到(1)采样样本分布与真实数据分布之间的距离随着采样大小的增加而减小;(2) 基于JointEnc的采样数据通常最接近不同采样大小的真实数据分布。相应地,图4报告了在每个策略的样本上训练的R-GQA的性能。根据我们JointEnc的示例训练的模型优于其他策略,展示了JointEnc方法的有效性。
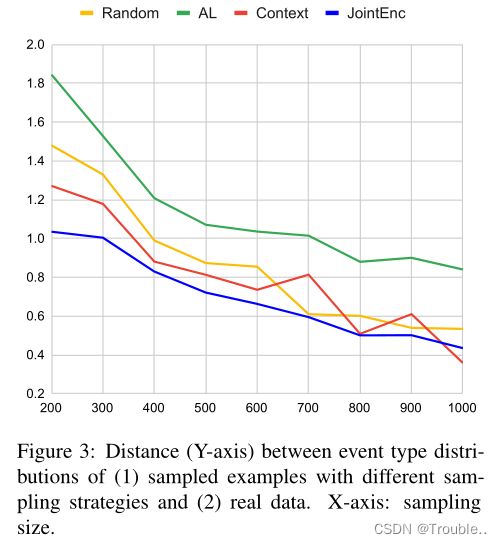
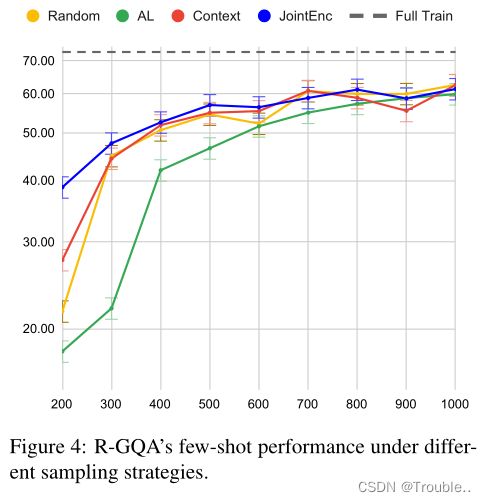
此外,我们发现分布距离与少样本实验结果之间存在相关性——距离越小,在采样集上训练的模型性能越好。当样本量较小(训练数据的5%-10%)时,这种现象尤为明显。我们还在附录(第D节)中提供了每种事件类型的分析。
5、相关工作
事件抽取、抽取和生成方法 传统上,研究人员一直在研究事件/信息抽取的抽取方法。具体而言,一个工作分支使用基于B-I-O序列标记的方法,使用CRF或结构化SVM模型,最近使用神经网络。提取方法的另一个分支包括使用跨度枚举,以及使用问题回答来鼓励论元角色之间的转换。
最近,提出了基于生成的方法。其中,TANL提出将基于翻译的方法用于结构化预测。更具体地说,它通过在输入句子中的实体提及周围插入文本token和标签来构造解码目标。更好地捕获跨实体依赖关系。Huang等人提出了基于模板生成的方法。他们用论元填充模板中的角色槽(例如第2节),以构建正确序列。与TANL和基于模板生成的方法相比,我们的R-GQA被设计为具有更简单生成目标的基于QA的生成模型。此外,它还使用训练集中最类似的 demonstration 作为提示来增强当前示例的上下文。它同时兼顾了两个方面(即问题回答和生成模型)。
检索增强文本生成和上下文学习 最近的研究表明,检索增强在许多生成性NLP任务中的有效性,如知识密集型问题解答和对话响应生成。它们主要检索附加知识或相关信息,但不检索 demonstration(输入输出对)。另一个密切相关的工作分支是上下文学习,这是一种无需调整的方法,通过提供演示(输入输出对)作为生成“答案”的提示来适应新任务。GPT-3建议使用随机示例作为演示。Liu等人提出检索语义上与当前示例相似的演示作为提示,从而改进了该策略。他们展示了PLM从类似例子中学习的能力。
与上述工作不同,我们的工作从检索增强文本生成和上下文学习中获得了见解。它(1)从训练集检索最相似的 demonstration (QA对)并将其用作提示;(2) 使用梯度下降来优化模型。此外,它侧重于特定的论元抽取问题——我们的模型不仅通过 demonstration 来增强输入上下文,而且还决定从中学习多少(通过模拟损失训练)。
6、总结
在这项工作中,我们介绍了一种用于事件论元抽取的检索增强生成问题回答框架(RGQA)。我们的模型为每个角色生成论元(答案),条件是当前输入上下文和类比 demonstration 提示(基于它们的语义相似性)。经验上,我们表明,R-GQA在完全监督、跨领域和少样本学习环境中以较大的准确率优于当前基准。我们进行了彻底的分析,并对不同的采样策略如何在少样本学习环境中影响模型的性能进行了基准测试。我们发现,对于事件论元抽取,多样化的示例使采样分布更接近真实分布,并有助于模型更好的性能。
限制
这个工作包含几项限制:
- 首先,由于我们使用的预训练模型(BART Large)具有许多参数,一个模型的训练将几乎占用一个NVIDIA Tesla V100 16GB GPU;至于推断,大约需要1GB的空间。
- 尽管基于BART的模型(GenIE和R-GQA)是端到端的,并且有很大的性能提升,但与基于手动特征的方法相比,推断时间(约2个示例/秒)略长。
- 在真实的领域迁移设置中,模型的总体性能仍然低于40%(F1),使得系统在真实环境中没有竞争力。在未来,如何通过更一般的本体来应对这一挑战是值得研究的。