机器学习实战(4):决策树&集成学习&随机森林
4.1 训练和可视化决策树
可以将决策树理解成一个判断二叉树
我们继续用花的数据集,训练一个决策树。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris["data"][:, 2:]
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)
将决策树可视化,要使用export_graphviz()方法输出一个图形定义文件(.dot)
#决策树的可视化
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file="iris_tree.dot",
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
接下来书上写得这步可算是折磨了我好久,首先是“!”可以使编译器运行cmd命令,然后文件要写全部的具体路径,由于是cmd命令,不像之前的数据集可以直接识别编译器默认文件夹里的文件。在这里我就不写具体路径了:
! dot -Tpng iris_tree.dot -o iris_tree.png
可以在在文件夹中发现一个新的png文件,打开可以看到如下:
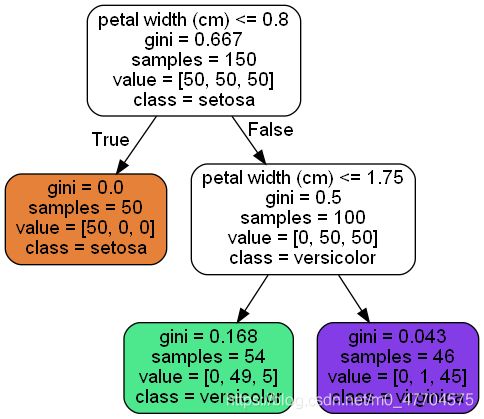
4.2 做出预测&估计类概率
我们已经可以直观的看到二叉树的分类标准,所以这时用任何的数据都可以找到对应的一片叶子节点,它不会提出任何问题
用我们在上一章提到的分界线画法,其分类标准如下:

predict_proba() 返回此数据每种花的概率
tree_clf.predict_proba([[5, 1.5]])
结果:
array([[0. , 0.90740741, 0.09259259]])
我们可以看到第二种最高,而predict也证实这个结果
tree_clf.predict([[5, 1.5]])
输出:
array([1])
4.3 回归决策树
回归决策树和之前的分类树很类似,只不过每个叶节点不是预测一个类别而是预测一个值。
#回归决策树
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
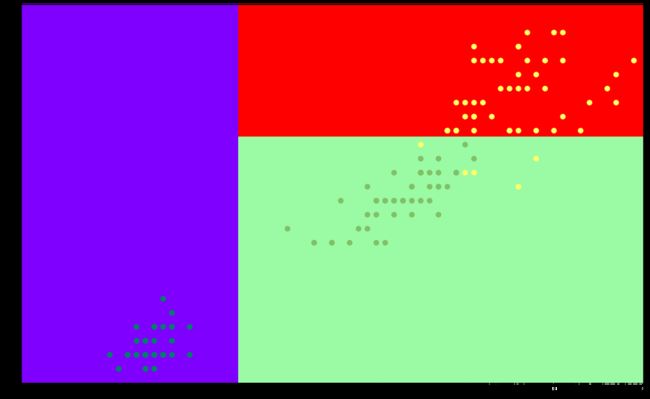
我们可以发现在这组数据集上回归决策树的效果要更好一些。
4.4 投票分类器
集成学习可以将很多弱分类器(仅比随机猜测好一点)组成一个强分类器。
我们用卫星数据集训练一个三合一投票分类器
数据生成(0.15噪音):
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
X, y = make_moons(n_samples=1000, noise=0.15)
print(X.shape)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, marker='o', cmap='summer')

X_train, X_test, y_train, y_test = X[:800], X[800:], y[:800], y[800:]
#一个投票分类器
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression()
rnd_clf = RandomForestClassifier()
svm_clf = SVC()
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)], voting='hard')
voting_clf.fit(X_train, y_train)

看一下测试集上每个分类器的精度
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
结果:
LogisticRegression 0.855
RandomForestClassifier 0.89
SVC 0.885
VotingClassifier 0.89
可见投票分类器略胜于单个分类器
4.5 bagging & pasting
每个分类器的算法相同,但是在不同的训练集随即子集上进行训练。
bagging和pasting都允许训练实例在多个预测器中被多次采样,而只有bagging允许训练实例被同一个样本采样。
bagging训练
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs=-1)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)
输出:
0.895
包外评估:bagging采样时,有大约37%样本根本不会被采样,这些样本集合成为“包外(oob)”。注意:对每个预测器来说,这是不一样的37%。我们要平均每个预测器的oob评估来评估整体。
创建BaggingClassifier时,oob_score=True就可以在训练结束后进行包外评估
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
bootstrap=True, n_jobs=-1, oob_score=True)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_
输出:
0.88
我们验证一下这个评估的准确率:
#oob评估出外包的准确率,用验证集验证一下:
from sklearn.metrics import accuracy_score
y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)
输出:
0.885
比较一致。
4.6 随机森林
随机森林和决策树最大的区别是:每个节点不再是搜索最好的特征进行分类,而是在一个随机的特征子集里搜索最好的特征,这导致决策树有更大的多样性。
#随机森林:民主投票决策树
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
accuracy_score(y_test, y_pred_rf)
输出:
0.885
4.6.1 极端决策树
如前所述,随机森林里单科树生长过程中,每个节点分裂时仅考虑了一个随机子集所包含的特征,如果我们对每个随即特征都使用随机阈值,则可能决策树的生长更加随机。
sklearn的ExtraTreesClassifier类可以创建一个极端随即树分类器
4.6.2 特征重要性
sklearn会为训练后的每个特征自动计算分数并缩放使其相加为1
from sklearn.datasets import load_iris
iris = load_iris()
rnd_clf = RandomForestClassifier(n_estimators=500, n_jobs=-1)
rnd_clf.fit(iris["data"], iris["target"])
for name, score in zip(iris["feature_names"], rnd_clf.feature_importances_):
print(name, score)
结果:
sepal length (cm) 0.09441936832373884
sepal width (cm) 0.023529506406908964
petal length (cm) 0.40715140082445306
petal width (cm) 0.47489972444489914
我们从而可以看到每个特征训练后的重要性占比
4.7 提升法
4.7.1 Adaboost
Adaboost是一个解决欠拟合问题的一个集合分类器。该算法会在训练一个基础分类器之后增加错误的训练实例的相对权重。
再详细的理论内容就要查知乎和csdn上其他人的解释了,我看了也并没有完全读懂。
#Adaboost
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5)
ada_clf.fit(X_train, y_train)
y_pred_ada = ada_clf.predict(X_test)
accuracy_score(y_test, y_pred_ada)
输出:
0.875
4.7.2 梯度提升
和Adaboost的目的一样,但是梯度提升是让新的预测器对前一个预测器的残差进行拟合。
#原理:
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth=2)
tree_reg1.fit(X, y)
y2= y - tree_reg1.predict(X)#用残差作为数据进行进一步训练
tree_reg2 = DecisionTreeRegressor(max_depth=2)
tree_reg2.fit(X, y2)
#实现:
from sklearn.ensemble import GradientBoostingRegressor
#n_estimators为树的数量
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0)
gbrt.fit(X, y)
但是我们最后发现,在进行一定的训练之后,随着树的增加,训练效果并不是越来越好,可能甚至变差。所以我们要进行提前停止法。
我们可以画出随着树的增加训练效果的函数图像得到最佳树的数量
#用stage_predict():在训练的每个阶段都对预测返回一个迭代器,找到树的最优数量
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X_train, X_val, y_train, y_val = train_test_split(X, y)
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120)
gbrt.fit(X_train, y_train)
errors = [mean_squared_error(y_val, y_pred)
for y_pred in gbrt.staged_predict(X_val)]
bst_n_estimators = np.argmin(errors) + 1
gbrt_best = GradientBoostingRegressor(max_depth=2,n_estimators=bst_n_estimators)
gbrt_best.fit(X_train, y_train)
import matplotlib.pyplot as plt
plt.plot(range(0,120),errors)
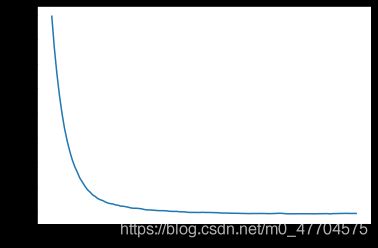
或者我们可以直接利用代码控制训练停止。
#warm_start=True,当fit调用时,sklearn会保留现有的树增强训练
#下面代码在连续5次迭代未改善时就会停止训练
gbrt = GradientBoostingRegressor(max_depth=2, warm_start=True)
min_val_error = float("inf")
error_going_up = 0
for n_estimators in range(1, 120):
gbrt.n_estimators = n_estimators
gbrt.fit(X_train, y_train)
y_pred = gbrt.predict(X_val)
val_error = mean_squared_error(y_val, y_pred)
if val_error < min_val_error:
min_val_error = val_error
error_going_up = 0
else:
error_going_up +=1
if error_going_up ==5:
break
y_pred_gbrt = gbrt.predict(X_test)
mean_squared_error(y_test, y_pred_gbrt)
补充:XGBoost
现在流行的XGBoost库中提供了梯度提升的优化体现
%pip install xgboost
import xgboost
xgb_reg = xgboost.XGBRegressor()
xgb_reg.fit(X_train, y_train)
y_pred = xgb_reg.predict(X_val)
XGBOost中的自动处理提前停止
xgb_reg.fit(X_train, y_train,
eval_set=[(X_val, y_val)],early_stopping_rounds=2)
y_pred = xgb_reg.predict(X_val)