C++线代运算库Armadillo安装与使用
最近看fastlab的eago_planner_swarm发现代码中有使用Armadillo进行优化求解
艘了下使用方法
下面引自:C++线代运算库Armadillo安装与使用
Tags: C/C++
- 1.简介
- 2.安装
- (1)依赖库安装
- (2)源码下载
- (3)源码编译
- 3.使用
在前几天进行SVD代码相关改写的时候发现,Eigen对于大矩阵SVD分解的效率比较低。因此在网上找了一些相关的库来进行大矩阵SVD分解。比如Truncated SVD等,这其中,无意之间发现的另一个库引起了我的注意:Armadillo。经过测试,它在易用性和效率上都比之前找到的要好。因此本篇博客就对Armadillo进行一个简单的介绍。
1.简介
Armadillo英文单词是犰狳(拼音qiu yu,都是第二声)的意思,这是一种美洲动物,体表覆盖甲冑状原骨质板,以昆虫为食,遭攻击时缩成一团,如下图所示。有点类似于大号的“西瓜虫”。顺带吐槽一下,似乎代码中的很多库和工具都是以动物的名字来命名的,比如Python是大蟒蛇的意思、ROS的版本代号、Ubuntu的版本代号等等。一句话来概括这个库就是,它是一个专门针对C++的、用于高精度线代运算的库,官网是这里。它的一些比较吸引人的特点如下:
- 总体平衡了API的易用性与代码运行的高效性
- 整个库的API风格类似于Matlab,方便快速将Matlab等科研代码转换成C++代码
- 默认自动使用OpenMP等并行加速手段进行加速
可以看到,对于开发者而言,尤其是想要将Matlab代码转成C++代码的人来说,还是非常友好的。同时又默认支持加速技术,在运行效率上也会有一定的保障。
2.安装
(1)依赖库安装
对于Armadillo而言,需要提前安装好的依赖库主要有两个OpenBLAS和LAPACK。我们可以直接打开终端,输入以下命令进行安装。
apt-get install libopenblas-dev liblapack-dev libarpack2-dev libsuperlu-dev
没有报错的话就说明这些依赖库就安装成功了。
(2)源码下载
我们要官网的下载页面下载源码,地址是这里。
下载完成后会得到一个压缩包,解压即可,等待备用。
(3)源码编译
Armadillo本身就是一个标准的CMake项目,所以直接CMake标准流程即可。在解压后的文件夹中打开终端,输入如下内容配置CMake。
mkdir build
cd build
cmake ..
正常情况下出现如下图所示的结果,就说明配置好了。
然后直接make即可。最后make install进行安装即可完成。
3.使用
关于Armadillo的使用可以参考官网的文档,写得还是比较清晰的。在之前的这篇博客中也介绍过不同库的SVD分解。由于我是因为SVD采用Armadillo,因此这里还是以SVD分解为例说明如何使用。本部分所有的代码放到了Github上,点击查看。首先是CMakeLists.txt的写法。
cmake_minimum_required(VERSION 3.15)
project(armadillo_demo)
set(CMAKE_CXX_STANDARD 11)
find_package(Armadillo)
include_directories(${ARMADILLO_INCLUDE_DIRS})
add_executable(svd_demo main.cpp)
target_link_libraries(svd_demo ${ARMADILLO_LIB_DIRS} armadillo)
还是比较常规的找包,然后include和target link。然后在代码文件中,需要包含头文件#include ,示例如下。
#include
#include
using namespace std;
using namespace arma;
int main() {
mat X(4, 5, fill::randu);
mat U;
vec s;
mat V;
svd_econ(U, s, V, X);
cout << U << endl;
cout << s << endl;
cout << V << endl;
return 0;
}
这里的svd_econ()可以理解为普通SVD的加速版,尤其适合大矩阵。在我们的场景中,矩阵差不多都是十几万行乘以几十列,所以非常适合。上面代码的输出结果如下。可以看到,程序在输出的时候还非常贴心地把矩阵隔开了。这在Eigen中是没有的。这个设计值得点赞。
另外,Armadillo当然也是支持它的数据类型和Eigen、OpenCV之间的互相转换的。下面的代码演示了这种转换。
// Armadillo相关引用
#include
// Eigen相关引用
#include
#include
// OpenCV相关引用
#include
#include
using namespace std;
int main() {
Eigen::MatrixXd mat_eigen = Eigen::MatrixXd::Random(4, 3);
cout << "Original mat(Eigen):\n" << mat_eigen << endl;
// Eigen转Armadillo
arma::mat mat_arma = arma::mat(mat_eigen.data(), mat_eigen.rows(), mat_eigen.cols(),
false, false);
cout << "Converted mat(Eigen > Armadillo):\n" << mat_arma << endl;
// Armadillo转Eigen
Eigen::MatrixXd mat_restore_eigen = Eigen::Map(mat_arma.memptr(),
mat_arma.n_rows,
mat_arma.n_cols);
cout << "Restoreed mat(Armadillo > Eigen):\n" << mat_restore_eigen << endl;
// OpenCV转Armadillo
cv::Mat mat_opencv = cv::Mat::eye(4, 4, CV_64F);
Eigen::MatrixXd mat_eigen2;
cv2eigen(mat_opencv, mat_eigen2);
arma::mat mat_arma2 = arma::mat(mat_eigen2.data(), mat_eigen2.rows(), mat_eigen2.cols(),
false, false);
cout << "Converted mat(OpenCV > Armadillo):\n" << mat_arma2 << endl;
// Armadillo转OpenCV
Eigen::MatrixXd mat_restore_eigen2 = Eigen::Map(mat_arma2.memptr(),
mat_arma2.n_rows,
mat_arma2.n_cols);
cv::Mat mat_opencv2 = cv::Mat::eye(4, 4, CV_64F);
cv::eigen2cv(mat_restore_eigen2, mat_opencv2);
cout << "Converted mat(Armadillo > OpenCV):\n" << mat_restore_eigen2 << endl;
return 0;
}
需要注意的是,在测试中发现如果将各个转换封装成函数,矩阵传入传出可能会有问题。所以在实际使用时不建议写成函数,直接调用就好,也没有非常复杂。
最后,如同一开始说的,是因为想要更快的SVD才找到了这个库,所以也和Eigen、Truncated SVD进行了对比,对比结果如下图所示。代码见Github仓库的compare_performance.cpp文件。
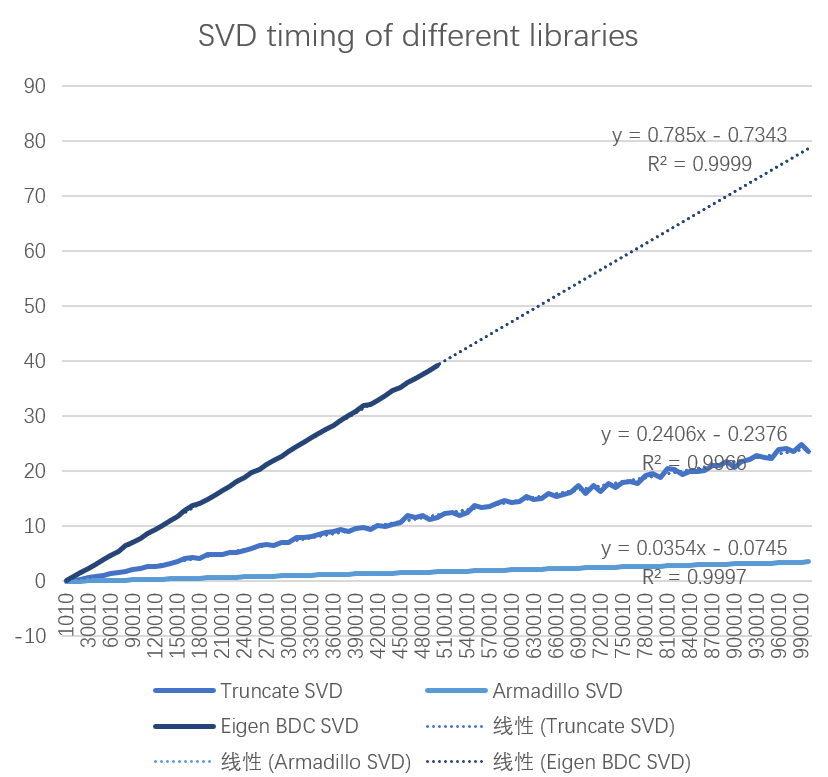
SVD分解的矩阵行数从1010到1000010,列数为50。可以看到Armadillo在运行耗时上是最短的,对于50张512×512的影像,基本可以在1秒完成SVD分解。
至此,本篇博客的内容就结束了,主要介绍了Armadillo的简单使用。之后有更多需求可以参考官方文档。