openCV(二)图像相关操作
文章目录
- 图像的基础操作
-
- 图像的读取、显示与保存
- 访问像素值并修改
- 访问图像属性
- 设置感兴趣区域(ROI)
- 分割和合并图像通道
- 为图像设置边框(填充)
- 图像的算术运算
-
- 图像加法
- 图像融合
- 按位运算
图像的基础操作
图像的读取、显示与保存
| 函数 | 说明 |
|---|---|
| cv.imread(path,flags) | 读取图像,返回一个图像对象。 path为图像的路径,flags为图像读取方式:1-彩色图像,无alpha通道;0-灰度图像;-1-包含alpha通道的彩色图像 |
| cv.imshow(name,img) | 在窗口中显示图像,name为窗口名称,img为要显示的图像对象 |
| cv.imwrite(filename,img) | 在当前目录中保存图像,filename为要保存的文件名,img为要保存的图像对象 |
一个栗子
从当前目录,以灰度模式读取一个图像,显示在窗口中,按S键另存在当前目录并退出
#导入opencv-python模块
import cv2 as cv
#读取图像
img = cv.imread('color.webp', 0)
#显示图像
cv.imshow('image', img)
#等待键盘输入
k = cv.waitKey(0)
#按S键的操作,ord将按键转换为ASCII码
if k == ord('s'):
#保存图像
cv.imwrite('_gray.png', img)
#关闭所有窗口
cv.destroyAllWindows()
#按Esc键关闭所有窗口
if k == 27:
cv.destroyAllWindows()
访问像素值并修改
| 操作 | 说明 |
|---|---|
| img[x,y,channel] | 通过行和列坐标来访问像素值或重新赋值,若给出channel则访问或修改对应通道值 openCV中彩色通道依次为BGR |
| img.item(x,y,channel) | 通过行和列坐标来访问指定channel的值,不可缺省 |
| img.itemset((x,y,channel),val) | 修改指定行和列坐标和channel的像素值为val,不可缺省 |
import cv2 as cv
img = cv.imread('color.webp')
# 读取像素值
print(img[10, 10]) #[ 98 163 189]
print(img[10, 10, 2]) #189
print(img.item(10, 10, 2)) #189
# 修改像素值
img[10, 10] = [0, 0, 0]
print(img[10, 10]) #[0 0 0]
img.itemset((10, 10, 2),255)
print(img.item(10,10,2)) #255
访问图像属性
| 属性 | 说明 |
|---|---|
| img.shape | 彩色图像返回行、列和通道数的元组,灰度图形返回元组不包括通道数 |
| img.size | 返回图像的像素总数 |
| img.dtype | 返回图像数据类型 |
import numpy as np
import cv2 as cv
img = cv.imread('color.webp')
img2 = cv.imread('color.webp', 0)
print(img.shape) #(500, 800, 3)
print(img2.shape) #(500, 800)
print(img.size) #1200000
print(img.dtype) #uint8
设置感兴趣区域(ROI)
选择感兴趣区域并将其复制到图像中的另一个区域
| 操作 | 说明 |
|---|---|
| roi=img[start_r1:end_r1,start_c1:end_c1] | 获取感兴趣区域roi start_r1为兴趣区域起始行 end_r1为兴趣区域结束行 start_r1为兴趣区域起始列 end_r1为兴趣区域结束列 |
| img[start_r2:end_r2:step_r,start_c2:end_c2:step_c]=roi | 将roi复制到图像的另一大小相同的区域 |
例如,将兔子眼睛复制到图像开始区域
import numpy as np
import cv2 as cv
img = cv.imread('color.webp')
roi=img[260:314,350:420]
img[0:54,0:70]=roi
img=cv.imshow('image',img)
cv.waitKey(0)
cv.destroyAllWindows()

分割和合并图像通道
当需要分别处理图像的B,G,R通道时,需将图像拆分为单个通道
处理完以后,可能需要将这些单独的通道合并加入图像中
| 操作 | 说明 |
|---|---|
| b,g,r = cv.split(img) | 拆分彩色图像通道,分别得到蓝色、绿色、红色通道数组 |
| img = cv.merge((b,g,r)) | 将蓝色、绿色、红色通道数组合并到图像 |
注:使用 NumPy 切片得到分离通道更为简便,而且运行速度比 cv2.split 更快;cv2.merge操作复杂耗时,推荐使用 NumPy 数组合并函数 np.stack() 生成合成图像
import numpy as np
import cv2 as cv
img = cv.imread('color.webp')
# 获取图像前2*2像素区域
roi = img[:2, :2]
print(roi)
#[[[103 167 193]
# [103 167 193]]
# [[103 167 193]
# [103 167 193]]]
# 拆分图像通道
b, g, r = cv.split(roi)
print(r)
#[[193 193]
# [193 193]]
# 合并图像通道
roi = cv.merge((b, g, r))
print(roi)
#[[[103 167 193]
# [103 167 193]]
# [[103 167 193]
# [103 167 193]]]
注:使用 NumPy 的操作更为简便,而且运行速度比 更快
import numpy as np
import cv2 as cv
img = cv.imread('color.webp')
# 获取图像前2*2像素区域
roi = img[:2, :2]
print(roi)
#[[[103 167 193]
# [103 167 193]]
# [[103 167 193]
# [103 167 193]]]
# 拆分图像通道
b = roi[:, :, 0]
g = roi[:, :, 1]
r = roi[:, :, 2]
print(r)
#[[193 193]
# [193 193]]
# 合并图像通道
roi = np.stack((b, g, r), axis=2)
print(roi)
#[[[103 167 193]
# [103 167 193]]
# [[103 167 193]
# [103 167 193]]]
为图像设置边框(填充)
cv.copyMakeBorder(img,top,bottom,left,right,borderType,color)
| 参数 | 说明 |
|---|---|
| img | 要操作的图像 |
| top,bottom,left,right | 边框宽度,单位为像素数 |
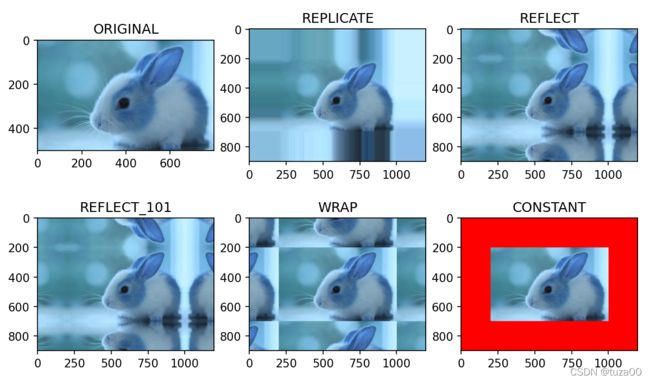
| borderType | 边框类型,可选值如下: 镜像边框:cv.BORDER_REPLICATE-aaaaaa | abcdefgh | hhhhhhh cv.BORDER_REFLECT- fedcba | abcdefgh | hgfedcb cv.BORDER_REFLECT_101-gfedcb | abcdefgh | gfedcba cv.BORDER_WRAP-cdefgh | abcdefgh | abcdefg 恒定彩色边框:cv.BORDER_CONSTANT,需给定color值 |
| color | 如果边框类型为cv.BORDER_CONSTANT,需指定边框颜色 |
import cv2 as cv
from matplotlib import pyplot as plt
# 设置边框颜色,matplotlib中颜色通道为rgb,因此这里设置的蓝色实际会显示为红色
BLUE = [255, 0, 0]
img1 = cv.imread('color.webp')
# 镜像边框
replicate = cv.copyMakeBorder(img1, 200, 200, 200, 200, cv.BORDER_REPLICATE)
reflect = cv.copyMakeBorder(img1, 200, 200, 200, 200, cv.BORDER_REFLECT)
reflect101 = cv.copyMakeBorder(img1, 200, 200, 200, 200, cv.BORDER_REFLECT_101)
wrap = cv.copyMakeBorder(img1, 200, 200, 200, 200, cv.BORDER_WRAP)
# 恒定颜色边框
constant = cv.copyMakeBorder(
img1, 200, 200, 200, 200, cv.BORDER_CONSTANT, value=BLUE)
# 显示
plt.subplot(231), plt.imshow(img1, 'gray'), plt.title('ORIGINAL')
plt.subplot(232), plt.imshow(replicate, 'gray'), plt.title('REPLICATE')
plt.subplot(233), plt.imshow(reflect, 'gray'), plt.title('REFLECT')
plt.subplot(234), plt.imshow(reflect101, 'gray'), plt.title('REFLECT_101')
plt.subplot(235), plt.imshow(wrap, 'gray'), plt.title('WRAP')
plt.subplot(236), plt.imshow(constant, 'gray'), plt.title('CONSTANT')
plt.show()
图像的算术运算
图像加法
可以通过cv.add(img1,img2)或numpy操作img1 + img2,其中img1和img2应具有相同的深度和类型
注:OpenCV加法是饱和运算,而Numpy加法是模运算
import cv2 as cv
img = cv.imread('color.webp')
img = img[100:500, 100:500]
bg = cv.imread('bg.webp')
bg = bg[100:500, 100:500]
cv.imshow('img', img)
cv.imshow('bg', bg)
cv.imshow('add', cv.add(img, bg))
cv.imshow('+', img+bg)
cv.waitKey(0)


图像融合
这也是图像加法,但是对图像赋予不同的权重,以使其具有融合或透明的感觉
| 函数 | 说明 |
|---|---|
| cv.addWeighted(img1,weight1,img2,weight2,gamma) | img1为图像1,weight1为其权重 img2为图像2,weight2为其权重 gamma为图像像素值归一,取值0-255 |
import cv2 as cv
img = cv.imread('color.webp')
img = img[100:500, 100:500]
bg = cv.imread('bg.webp')
bg = bg[100:500, 100:500]
cv.imshow('addweighted', cv.addWeighted(img, 0.7, bg, 0.3, 0))
cv.waitKey(0)

按位运算
包括按位 AND、 OR、NOT 和 XOR 操作
import cv2 as cv
# 主图
img1 = cv.imread('color.webp')
# logo图
img2 = cv.imread('logo.webp')
# 主图左上角设置为与logo图大小相同的感兴趣区域
rows, cols, channels = img2.shape
roi = img1[0:rows, 0:cols]
# 设置mask及其反码
# 将logo图转化为灰度图
img2gray = cv.cvtColor(img2, cv.COLOR_BGR2GRAY)
# logo图二值化,将logo图片中的灰度值大于200的像素值设置为白色,背景设置为黑色
ret, mask = cv.threshold(img2gray, 200, 255, cv.THRESH_BINARY_INV)
# 将mask按位取反,即前景为黑色,背景为白色
mask_inv = cv.bitwise_not(mask)
# 主图中剔除logo前景将要占用的位置的像素 logo图剔除背景位置像素
# 利用mask_inv进行按位与操作,即mask_inv白色区域是对主图像素的保留,黑色区域是主图像素的剔除
img1_bg = cv.bitwise_and(roi, roi, mask=mask_inv)
# 利用mask进行按位与操作,即mask白色区域是对logo图像素的保留,黑色区域是logo图像素的剔除
img2_fg = cv.bitwise_and(img2, img2, mask=mask)
# 将logo放入ROI并修改主图像
dst = cv.add(img1_bg, img2_fg)
img1[0:rows, 0:cols] = dst
cv.imshow('res', img2_fg)
cv.waitKey(0)
cv.destroyAllWindows()




参考:https://www.woshicver.com/