实战Java高并发程序设计(一)————————走进并行世界
走入并行世界
- 何去何从的并行计算
-
- 忘掉那该死的并行
- 可怕的现实:摩尔定律的失效
- 柳暗花明:不断地前进
- 光明或是黑暗
- 你必须知道的几个概念
-
- 同步(Synchronous)和异步(Asynchronous)
- 并发(Concurrency)和并行(Paralleism)
- 临界区
- 阻塞(Blocking)和非阻塞(Non-Blocking)
- 死锁(Deadlock)、饥饿(Starvation)和活锁(Livelock)
- 并发级别
-
- 阻塞(Blocking)
- 无饥饿(Starvation-Free)
- 无障碍(Obstruction-Free)
- 无锁(Lock-Free)
- 无等待(Wait-Free)
- 有关并行的两个重要定律
-
- Amdahl定律
- Gustafson定律
- Amdahl定律和Gustafson定律是否相互矛盾
- 回到Java:JVM
-
- 原子性(Atomicity)
- 可见性(Visiblity)
- 有序性(ordering)
- 哪些指令不能重排:Happen-Before规则
何去何从的并行计算
忘掉那该死的并行
Linus Torvalds 曾在发言中说到:
需要有多么奇葩的想象力才能想象出并行计算的用武之地?
并行计算只有在图像处理和服务端编程2个领域可以使用,并且它在这2个领域确实有着大量广泛的使用。但是在其他 任何地方,并行计算毫无建树!
可怕的现实:摩尔定律的失效
摩尔定律是由英特尔创始人之一戈登 • 摩尔提出的,基于人为观测数据后,对未来的预测。其内容为: 集成电路上可容纳的电晶体(晶体管)数目,约每隔24个月便会增加一倍;经常被引用的“18个月”,是英特尔首席执行官大卫 • 豪斯所说:预计18个月会将芯片的性能提升一倍(即更多的晶体管使其更快)。
摩尔定律的有效性已经超过半个世纪了,然而,在2004年秋季,Inter宣布彻底取消4GHz计划。显然,摩尔定律在CPU的计算性能上可能已经失效了,在近10年的发展中,CPU主频的提升已经明显遇到了一些暂时不可逾越的瓶颈。
柳暗花明:不断地前进
CPU的性能已经几近止步,但是依然没有阻挡科学家和工程师们带领我i们不断前进的脚步。
从2005年开始,多核CPU从此诞生,摩尔定律在另外一个侧面又生效了,根据这个定律,我们可以预测,每过18到24个月,CPU和核心数就会翻一番。
顶级计算机科学家唐纳德 • 尔文 • 克努斯,如此评价这种情况:在我看来,这种现象(并发)或多或少是由于硬件设计者已经无计可施了导致的,他们将摩尔定律失效的责任推脱给软件开发者。
光明或是黑暗
摩尔定律本该由硬件开发人员维持,但硬件工程师似乎已经无计可施了,为了维持性能的高速发展,想出了将多个CPU内核塞进一个CPU里的奇妙想法。至此,并行计算自热的推广开,随之而来的问题也层出不穷,程序员的黑暗时期也随之到来。
因此,如何让多个CPU有效且正确地工作也就成为了一门技术,甚至是很大的学问。比如:多线程间如何保证线程安全,如何正确理解线程间的无序性、可见性,如何尽可能提高并行程序的设计,又如何将串行程序改造为并行程序。而对并行计算的研究,也就是希望在这片黑暗中带来光明。
你必须知道的几个概念
同步(Synchronous)和异步(Asynchronous)
- 同步:同步方法调用一旦开始,调用者必须等到方法调用返回后,才能继续后续的行为。
- 异步:异步方法调用更像一个消息传递,一旦开始,方法调用就会立刻返回,调用者就可以继续后续的操作。

并发(Concurrency)和并行(Paralleism)
- 并发:并发偏重于多个任务交替执行,而多个任务之间有可能还是串行的。
- 并行:并行是真正意义上的“同时执行”。

临界区
临界区用来表示一种公共资源或者说是共享数据,可以被多个线程使用。但是每一次,只能有一个线程使用它,一旦临界区资源被占用,其他线程要想使用这个资源,就必须等待。
阻塞(Blocking)和非阻塞(Non-Blocking)
- 阻塞:当一个线程占用了临界区资源,那么其他所有需要这个资源的线程就必须在这个临界区中进行等待。等到会导致线程挂起,这种情况就是阻塞。
- 非阻塞:非阻塞的意思与之相反,它强调没有一个线程可以妨碍其他线程执行。所有的线程都会尝试不断前向执行。
死锁(Deadlock)、饥饿(Starvation)和活锁(Livelock)
-
死锁:多个线程相互抢占对方的临界资源

-
饥饿:饥饿是指某一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行。
-
活锁:线程如果都秉承着“谦让”的原则,主动将资源释放给他人使用,那么就会出现资源不断的在两个线程中跳动,而没有一个线程可以同时拿到所有资源而正常执行。这种情况就是活锁。
并发级别
由于临界区的存在,多线程之间的并发必须受到控制。更加控制并发的策略,我们可以把并发放的级别进行分类,大致可以分为阻塞、无饥饿、无障碍、无锁、无等待几种。
阻塞(Blocking)
一个线程是阻塞的,那么其他线程释放资源之前,当前线程无法继续执行。当我们使用synchroinzed关键字,或者重入锁时,我们得到的就是阻塞的线程。
无饥饿(Starvation-Free)
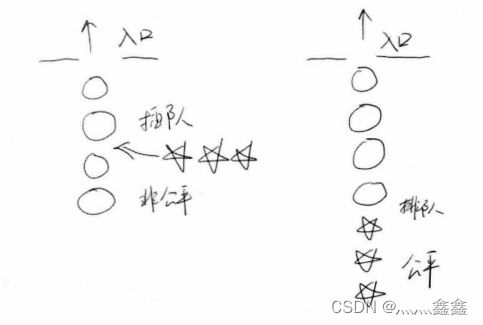
如果线程之间是有优先级的,那么线程调度的时候总是会倾向于满足高优先级的线程。对于非公平的锁来说,饥饿是存在于当系统允许高优先级的线程插队,这样可能会导致低优先级线程产生饥饿。如果锁是公平的,不管线程优先级多高,想要获取资源就得排队,这样所有线程都有机会执行。如图显示了非公平与公平两种情况(五角星表示高优先级线程)。
无障碍(Obstruction-Free)
无障碍是一种最弱的非阻塞调度。两个线程如果是无障碍的执行,那么他们不会因为临界区的问题导致一方被挂起。对于无障碍的线程来说,一旦检测到这种情况,它就会立即对自己所做的修改进行回滚,确保数据安全。但如果没有数据竞争发生,那么线程就可以顺利完成自己的工作,走出临界区。
无锁(Lock-Free)
无锁的并行都是无障碍的。在无锁的情况下,所有的线程都能尝试对临界区进行访问,但不同的是,无锁的并发保证必然有一个线程能够在有限步完成操作离开临界区。
无等待(Wait-Free)
无锁只要求有一个线程可以在有限步内完成操作,而无等待则在无锁的基础上更进一步进行扩展。它要求所有的线程都必须在有限步内完成,这样就不会引起饥饿问题。如果限制这个步骤上限,还可以进一步分解为有界无等待和线程数无关的无等待几种,它们之间的区别只是对循环次数的限制不同。
一种典型的无等待结构就是RCU(Read-Copy-Update)。它的思想是,对数据的都可以不加控制。因此,所有的读线程都是无等待的,它们既不会被锁定等待也不会引起任何冲突。但在写数据的时候,先取得原始数据的副本,接着只修改副本数据(这就是为什么读可以不加控制),修改完成后,在合适的时机写回数据。
有关并行的两个重要定律
Amdahl定律
它定义了串行系统并行化后的加速比的计算公式和理论上限。
加速比定义:加速比 = 优化前系统耗时 / 优化后系统耗时
下图为公司的推导过程:n:表示处理器个数,T:表示时间,T1:表示优化前耗时(也就是只有1个处理器时的耗时),Tn:表示使用n个处理器优化后的耗时,F:指程序中只能串行执行的比例。

注意:根据Amdal定律,使用多核CPU对系统进行优化,优化的效果取决于CPU的数量以及系统中的串行化程序的比重。CPU数量越多,串行化比重越低,则优化效果越好。仅提高数量而不降低程序的串行化比重,也无法提高系统性能。
Gustafson定律
Gustafson定律也试图说明处理器个数、串行比例和加速比之间的关系。如图为Gustafson定律的推导

可以看到,Gustafson定律的切入角度不同,从Gustafson定律中,我们可以更容易地发现,如果串行化比例很小,并行化比例很大,那么加速比就是处理器的个数。只要你不断地累加处理器,就能获得更快的速度。
Amdahl定律和Gustafson定律是否相互矛盾
两者的差异其实是因为这两个定律对同一个客观事实从不同角度去审视后的结果,它们的偏重点有所不同,并不矛盾。
回到Java:JVM
Java的内存模型(JMM)的关键点都是围绕着多线程的原子性、可见性和有序性来建立的。因此,我们首先必须了解这些概念。
原子性(Atomicity)
原子性是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
可见性(Visiblity)
可见性是指当一个线程修改了某一个共享变量的值,其他线程是否能够立即知道这个修改。

有序性(ordering)
对于一个线程的执行代码而言,我们总是习惯地认为代码的执行是从先往后,依次执行的。但是在并发时,程序的执行可能就会出现乱序。给人直观的感觉就是:写在前面的代码,会在后面执行。有序性问题的原因时因为程序在执行时,可能会进行指令重排,重排后的指令与原指令的顺序未必一致。

注意:指令重排可以保证串行语义一致,但是没有义务保证多线程间的语义也一致。
一条指令的执行步骤:
- 取指IF
- 译码和取寄存器操作数ID
- 执行或者有效地址计算EX
- 存储器访问MEM
- 写回WB
汇编指令不是一步就可以执行完毕的,在CPU中实际工作时,它还是需要分为多个步骤依次执行的。每个步骤所涉及的硬件也可能不同。比如,取指时会用到PC寄存器和存储器,译码会用到指令寄存器组,执行时会使用ALU,写回时需要寄存器组。
注意:ALU指算术逻辑单元,它是CPU的执行单元,时CPU的核心组成部分,主要功能是进行二进制算术运算。
由于每一步都可能使用不同的硬件完成,因此,聪明的工程师们就发明了流水线技术来执行指令。如图为流水线的工作原理:

流水线总是害怕被中断的。流水线满载时,性能确实相当不错,但是一旦中断,所有的硬件设备都会进入一个停顿期,再次满载又需要几个周期,因此,性能损失会比较大。所以,我们必须要想办法尽量不让流水线中断。这时,就需要指令重排了,指令重排就是为了尽量少的中断流水线。
例1:A=B+C

例2:
a=b+c
d=e-f



由此可见,指令重排对于提高CPU处理性能是十分必要的。虽然确实带来了乱序的问题,但是这点牺牲是完全值得的。
哪些指令不能重排:Happen-Before规则
指令重排是有原则的,并不是所有的指令都可以随便改变执行位置,以下罗列了一些基本原则:
- 程序顺序原则:一个线程内保证语义的串行性
- volatile规则:volatile变量的写,先发生于读,这保证了volatile变量的可见性
- 锁规则:解锁(unlock)必然发生在随后的加锁(lock)前
- 传递性:A先于B,B先于C,那么A必然先于C
- 线程的start()方法先于它的每一个动作
- 线程的所有操作先于线程的总结(Thread.join())
- 线程的中断(interrupt)先于被中断线程的代码
- 对象的构造函数执行、结束先于finalize()方法