为可迁移对抗性攻击训练元代理模型
关注公众号,发现CV技术之美
本篇分享论文『Training Meta-Surrogate Model for Transferable Adversarial Attack』,为可迁移对抗性攻击训练元代理模型。
详细信息如下:

论文链接:https://arxiv.org/abs/2109.01983
01
引言
该论文是关于黑盒攻击可迁移性的文章。在当前大量的研究中,许多方法直接攻击代理模型并获得的可迁移性的对抗样本来欺骗目标模型,但由于代理模型和目标模型之间的不匹配,使得它们的攻击效果受到局限。
在该论文中,作者从一个新颖的角度解决了这个问题,通过训练一个元代理模型(MSM),以便对这个模型的攻击可以更容易地迁移到到其它模型中去。该方法的目标函数在数学上被表述为一个双层优化问题,为了能够让训练过程梯度有效,作者提出了新的梯度更新过程,并在理论上给出了证明。实验结果表明,通过攻击元代理模型,可以获得更强的可迁移性的对抗样本来欺骗包括对抗训练的黑盒模型,攻击成功率远高于现有方法。
根据论文提出的算法框架,我用pytorch进行了简易的代码实现,感兴趣的人可以更改代码中的数据集部分尝试跑一下。

02
预备知识
FGSM攻击是基于梯度的单步攻击方式,通过利用的梯度上升法使得分类损失函数增大,从而降低目标分类器的分类置信度。具体公式如下所示:
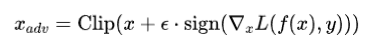
其中是干净样本,为对抗样本,是对应的分类标签,是攻击步长,且有 。是被攻击的目标分类器,为截断函数,为交叉熵损失函数。
PGD攻击是一种扩展FGSM攻击的多步攻击方式,其具体公式如下所示:
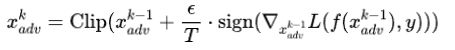
为第步生成的对抗样本,并且表示是初始的干净样本,攻击的迭代的次数为。
03
论文方法
对于黑盒攻击,目标模型的内部参数信息对攻击者是隐藏的并且不允许进行查询访问。攻击者只可以访问目标模型使用的数据集,以及与目标模型共享数据集的单个或一组源模型。
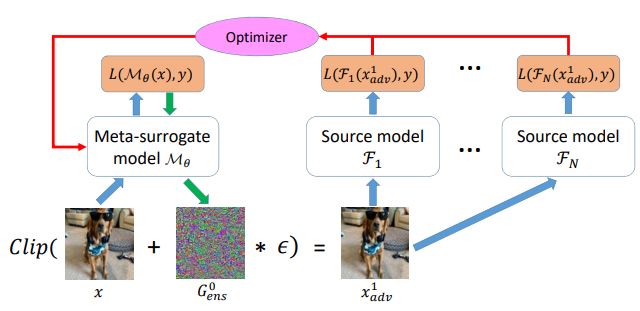
现有的可迁移对抗攻击方法对这些源模型进行各种攻击,并希望获得可以欺骗未知目标模型的具有可迁移性的对抗样本。在该论文中作者提出了一种新的元学习迁移攻击框架来训练元代理模型,其目标是攻击元代理模型可以产生比直接攻击原始模型更强大的可迁移对抗样本。
令为对抗攻击算法,为具有参数为的元代理模型,给一个样本,攻击的对抗样本可以表示为
![]()
因为在攻击时,只能获取到一组源模型的,所以需要在源模型中评估对抗样本的可迁移性,并通过最大化这个源模型的参数来优化元代理模型,具体的形式如下所示
其中为训练数据的分布。该目标的结构和训练过程如图下图所示,可以将其视为元学习或双层优化方法。在内层优化中,对抗样本是由元代理模型上的白盒攻击通常是梯度上升的方法生成的,而在外层优化中,作者将对抗样本送到源模型中以计算鲁棒损失。
在内层优化生成对抗样本的过程中,作者设计个一个自制的PGD攻击方法,原始的PGD攻击因为有函数,会使当更新网络参数进行反向传播的时候梯度会消失。则第步生成的梯度的计算公式如下所示:
令,和确保目标函数关于元代理模型的参数可微分求导,是符号函数的一种近似,防止陷入到线性区域中。为的每个像素提供了一个下界。生成对抗样本的公式如下所示:
迭代步之后得到最后的对抗样本。
将生成的对抗样本输入到个元模型中计算对应的对抗损失,个源模型的对抗损失越大说明生成的由代理模型生成的对抗样本也有更高的可能性去欺骗源模型。
通过最大化元代理模型的目标函数来优化该网络的权重参数,具体的参数优化公式如下所示
402 Payment Required
通过这个训练过程,元代理模型被训练来学习一个特定的权重,以此生成的对抗样本会有更高的可迁移性。
以计算 为例,由链式法则可知,与是相互独立的,进而则有
402 Payment Required
将以上公式可以进一步扩展为
402 Payment Required
又因为 等于 ,符号函数引入了离散的操作,则的梯度为。所以可以进一步得到
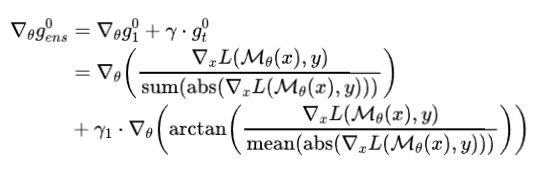
在这个公式中,是依赖于参数,优化元代理模型的优化器为SGD优化器。元对抗攻击算法的训练过程如下所示:

04
实验结果
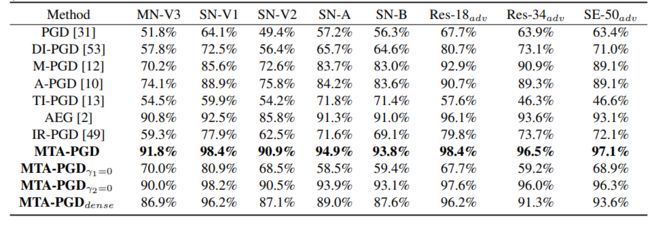
下表为在Cifar-10数据集上8个目标网络的迁移攻击成功率,其中元代理模型是使用这8个源模型进行训练得到的。如下表的定量结果可知,论文中提出的方法MTA-PGD的性能比之前所有的方法都要好得多,对抗攻击的迁移成功率显著提高。
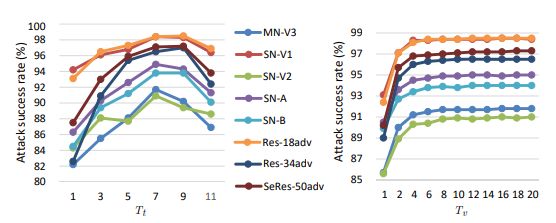
下图为探究在Cifar-10数据集上,对抗攻击算法中不同的迭代次数对于迁移攻击成功率的关系。从左半图可知,整体来看最佳的迭代攻击次数为;从右半图可知,随着迭代次数的增加,迁移攻击成功率也显著增加。
如下图所示,为不同的攻击方法生成的定性的可视化结果图。可以直观地发现,论文中提出的方法生成的对抗扰动更具有针对性,并且在视觉上生成的对抗样本与原干净样本更加相似。

05
代码实现
论文中具体的pytorch的简易代码实现如下所示,主要对论文算法流程图中关键涉及的步骤都进行了实现,数据集和模型的部分可以自行进行替换。
iport torch
import torch.nn as nn
import torch.utils.data as Data
import numpy as np
import os
import torch.nn.functional as F
from copy import deepcopy
def generate_dataset(sample_num, class_num, X_shape):
Label_list = []
Sample_list = []
for i in range(sample_num):
y = np.random.randint(0, class_num)
Label_list.append(y)
Sample_list.append(np.random.normal(y, 0.2, X_shape))
return torch.tensor(Sample_list).to(torch.float32), torch.tensor(Label_list).to(torch.int64)
class Normal_Dataset(Data.Dataset):
def __init__(self, Numpy_Dataset):
super(Normal_Dataset, self).__init__()
self.data_tensor = Numpy_Dataset[0]
self.target_tensor = Numpy_Dataset[1]
def __getitem__(self, index):
return self.data_tensor[index], self.target_tensor[index]
def __len__(self):
return self.data_tensor.size(0)
class Classifer(nn.Module):
def __init__(self):
super(Classifer, self).__init__()
self.conv1 = nn.Conv2d(in_channels = 3, out_channels = 10, kernel_size = 9) # 10, 36x36
self.conv2 = nn.Conv2d(in_channels = 10, out_channels = 20, kernel_size = 17 ) # 20, 20x20
self.fc1 = nn.Linear(20*20*20, 512)
self.fc2 = nn.Linear(512, 7)
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x)
out = F.relu(self.conv2(out))
out = out.view(in_size, -1)
out = F.relu(self.fc1(out))
out = self.fc2(out)
out = F.softmax(out, dim=1)
return out
class MTA_training(object):
def __init__(self, sml, dataloader, bs, msm, epsilon, iteration, gamma_1, gamma_2):
self.source_model_list = source_model_list
self.dataloader = dataloader
self.batch_size = batch_size
self.meta_surrogate_model = meta_surrogate_model
self.epsilon = epsilon
self.iteration = iteration
self.dataloader = dataloader
self.gamma1 = gamma1
self.gamma2 = gamma2
def single_attack(self, x, y, meta_surrogate_model):
delta = torch.zeros_like(x)
delta.requires_grad = True
outputs = meta_surrogate_model(x + delta)
loss = nn.CrossEntropyLoss()(outputs, y)
loss.backward()
grad = delta.grad.detach()
## The equation (4) of the paper
g_1 = grad/torch.sum(torch.abs(grad))
g_t = 2/np.pi * torch.atan(grad/torch.mean(torch.abs(grad)))
g_s = torch.sign(grad)
g_ens = g_1 + self.gamma1 * g_t + self.gamma2 * g_s
## The equation (5) of the paper
x_adv = torch.clamp(x + self.epsilon/ self.iteration * g_ens, 0 ,1)
return x_adv
def training(self, epoch):
loss_fn = nn.CrossEntropyLoss()
optim = torch.optim.SGD(meta_surrogate_model.parameters(), lr=0.001)
for X, Y in self.dataloader:
theta_old_list = []
for parameter in meta_surrogate_model.parameters():
theta_old_list.append(deepcopy(parameter.data))
X_adv = X
for k in range(self.iteration):
X_adv = self.single_attack(X_adv, Y, self.meta_surrogate_model)
loss = 0
for source_model in self.source_model_list:
outputs = source_model(X_adv)
loss += loss_fn(outputs , Y)
optim.zero_grad()
loss.backward()
optim.step()
for parameter_old, parameter in zip(theta_old_list, meta_surrogate_model.parameters()):
parameter.data = 2 * parameter.data - parameter_old.data
if __name__ == '__main__':
batch_size = 2
epsilon = 0.03
iteration = 10
epoch = 1
gamma1 = 0.01
gamma2 = 0.01
numpy_dataset = generate_dataset(10, 7, (3, 44, 44))
dataset = Normal_Dataset(numpy_dataset)
dataloader = Data.DataLoader(
dataset = dataset,
batch_size = batch_size,
num_workers = 0,)
source_model_list = []
source_model1 = Classifer()
source_model2 = Classifer()
source_model_list.append(source_model1)
source_model_list.append(source_model2)
meta_surrogate_model = Classifer()
meta_training = MTA_training(source_model_list, dataloader, batch_size, meta_surrogate_model, epsilon, iteration, gamma1, gamma2)
meta_training.training(10)
END
欢迎加入「对抗攻击」交流群备注:Ad
