为什么重写equals方法时必须重写hashcode方法
文章目录
- 1. == 与 equals的区别
- 2. 重写equals()
- 3. 为什么重写equals方法时必须重写hashcode方法?
-
- 3.1 Hash算法
- 3.2 HashCode()
相关文章:
为什么重写equals方法时必须重写hashcode方法
Java字符串不相同但HashCode相同的例子(算法)
深入分析Java中打印对象内存地址 System.identityHashCode()方法
1. == 与 equals的区别
-
如果两个引用类型变量使用
==运算符,那么比较的是地址,它们分别指向的是否是同一地址的对象,结果一定是false,因为两个对象地址必然不同。 -
==不能实现比较对象的值是否相同。 -
所有对象都有equals方法,默认是Object类的equals,其结果与
==一样。 -
如果希望比较对象的值相同,必须重写equals方法。
Object 类源码:
public class Object {
public native int hashCode();
public boolean equals(Object obj) {
return (this == obj);
}
从源码上可以看到,hashCode()和equals()都和地址相关,因此 new 出来的2个实例,a.equals(b)一定返回false。
2. 重写equals()
重写equals()的作用是什么?
如果希望比较对象的值相同,必须重写equals方法。这样可以在equals内自定义比较条件:
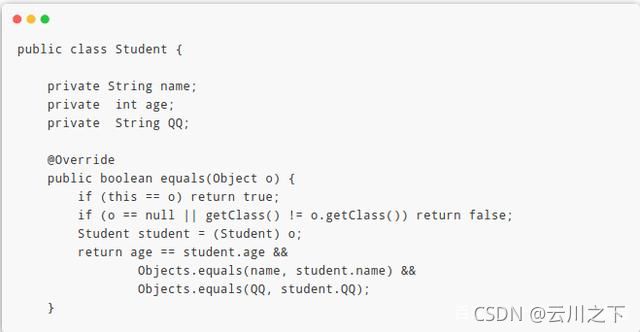
如上图所示,自定义的equals()比较条件是Student类的属性,只要姓名、年龄、QQ号都相同,则认为是同一个人。
这样是有很大作用的,例如一个Set 可以避免把同一个人加入2次。
但是这样是存在问题,涉及到hashCode
3. 为什么重写equals方法时必须重写hashcode方法?
本来equals方法和hashcode()是不相关的,但是由于我们会在集合中放入我们创建的对象,这样由于存储结构的问题,导致在查找时二者产生了关联。
我们举个例子:
class MyObject {
private String name;
public MyObject(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) { //重写了equals方法
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyObject myObject = (MyObject) o;
return Objects.equals(name, myObject.name);
}
// @Override
// public int hashCode() {
// return Objects.hash(name);
// }
public static void main(String[] args) {
Map<MyObject, Integer> map = new HashMap<MyObject, Integer>();
MyObject m1 = new MyObject("a"); //new MyObject("a");创建一个实例
map.put(m1, 1); //以该实例为key,存入一个值,1
MyObject m2 = new MyObject("a"); //new MyObject("a");创建一个实例
Integer value = map.get(m2);
if (value != null) {
System.out.println(value);
} else {
System.out.println("value is null"); //进入该分支,打印
}
}
}
程序运行结果: value is null
我们往一个HashMap中,放入一个自定义对象 MyObject(“a”)的实例,假设我们重写了equals,然后通过get()方法获取,为何结果为空?
hashmap是一个键值映射的集合类,存储结构为Key+Value,优点是方便快速查找,通过key可以快速找到Value,在存入一个Key+Valuehash元素时,需要先计算Key对应的hash值(计算过程称之为hash算法),hash值决定了最终存放的位置,我们称这个位置为HeadNode,并且如果产生hash碰撞,一般会采用链式结构扩展这个HeadNode,这个链也常称作桶,允许包含一组值。当key是一个对象类型时,,例如MyObject,我们需要重写equals()方法,此时2个对象的值相等等价于这2个对象是同一个对象,存在MyObject的2个实例对象,m1和m2,我们认定这俩对象”相等“,先利用m1作为key,存入hashmap,值为v1,此时,我们期望通过m2也能从hashmap中得到v1,在不重写hashcode的情况下,get(m2)会返回null ,为什么?
原因是hash值的计算借助hashcode方法,该方法的默认算法实现和对象的地址有关,而m1和m2被创建后,内存地址肯定不同,因此,在没有重写hashcode()方法时,所有的对象存入hashmap后,m1的hashcode是h1,m2的hashcode是h2, h1!=h2 ,那么get(m2) 就无法找到h1位置,也就无法返回v1
重写hashcode()方法目的是确保h1=h2,那么就get(m2) 就能找到h1位置,也就可以返回v1
HashMap的get()方法源码
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
//入口
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
//间接调用 getNode
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { //计算hash,如果不重写,那么hash的值就和内存地址相关
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
3.1 Hash算法
先用一张图看下什么是Hash

Hash是散列的意思,就是把任意长度的输入,通过散列算法变换成固定长度的输出,该输出就是散列值。关于散列值,有以下几个关键结论:
- 如果散列表中存在和散列原始输入K相等的记录,那么K必定在f(K)的存储位置上 ,即多次计算hash值一定相同
- 不同关键字经过散列算法变换后可能得到同一个散列地址,这种现象称为
碰撞 - 如果两个Hash值不同(前提是同一Hash算法),那么这两个Hash值对应的原始输入必定不同
3.2 HashCode()
然后讲下什么是HashCode,总结几个关键点:
1、HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的
2、如果两个对象equals相等,那么这两个对象的HashCode一定也相同
3、如果对象的equals方法被重写,那么对象的HashCode方法也一定重写
4、如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
即hashmap的底层实现,为了实现方便的查找,采用数组+链表,数组是hash的结果,链表是碰撞的解决方案。
这样,当在hashmap里面查找某个对象时,先通过hash快速找到对应的链表,然后在链表上逐个进行equals()比较,否则,需要在所有的元素上逐一进行比较,时间复杂度比较差。
先找链,再在链上进行值的比较
因此,如果改写了equals(),而不改写hashcode的话,Object内默认hashcode()方法必定不同的(new 出对象的地址一定不同),这样hashmap存储的2个对象,都在不同的链上,这样无法进行equals()比较。