Pandas(二)—— 索引、分组
Python模块 —— Pandas
- Pandas(二)—— 索引、分组
-
- 三、索引
-
- 3.1 索引器
-
- 3.1.1 列索引、行索引
- 3.1.2 loc索引器、iloc索引器
- 3.1.3 query方法
- 3.1.4 随机抽样
- 3.2 多重索引
-
- 3.2.1 普通列设为索引
- 3.2.2 多重索引的loc索引器
- 3.2.3 其他
- 3.2.4 索引的常用方法
- 3.3 练习
-
- 3.3.1 公司员工数据集
- 3.3.2 巧克力数据集
- 四、分组
-
- 4.1 分组函数
- 4.2 聚合函数
-
- 4.2.1 内置聚合函数
- 4.2.2 agg/transform/apply方法
- 4.3 变换和过滤
- 4.4 练习
-
- 4.4.1 汽车数据集
Pandas(二)—— 索引、分组
大家可以关注知乎或微信公众号的share16,我们也会同步更新此文章。
三、索引
3.1 索引器
3.1.1 列索引、行索引
列索引是最常见的索引形式,一般通过[ ]来实现。
- 取某一列:通过
[列名] 或 .列名,可以从DataFrame中取出相应的某一列,返回值为Series; - 取某几列:通过
[列名组成的列表],可以从DataFrame中取出相应的某几列,其返回值为一个DataFrame;
行索引亦是最常见的索引形式,也能通过[ ]来实现。
- 以整数为索引的Series:取某一行(
s[i])或某几行(s[[i,j]] 或 s[i:j](左闭右开)),用法与列表/字符串等索引用法一致; - 以字符串为索引的Series:取某一行(
s[i])或某几行(s[[i,j]] 或 s[i:j]),用法与列表/字符串等索引用法存在差异;若i/j是字符串,遵循左闭右闭;若i/j是整数,遵循左闭右开; - DataFrame的行索引,执行
s[i]和s[[i,j]]会返回Error,执行s[i:j]会返回结果;若i/j是字符串,遵循左闭右闭;若i/j是整数,遵循左闭右开;
import pandas as pd
df = pd.read_excel('/xxx/公司员工.xlsx', parse_dates=['birthdate_key'])
# 列索引:DataFrame
print(df['city_name'], df.city_name, df[['city_name', 'department']], sep='\n\n')
# 行索引:以整数为索引的Series
s = df['job_title'].head()
print('取某一行 s[i] :', s[1], type(s[1]))
print('\n')
print('取某几行 s[[i,j]] 或 s[i:j]:', s[[1,3]], type(s[[1,3]]), s[1:3], type(s[1:3]), sep='\n\n')
# 行索引:以字符串为索引的Series
s = pd.Series(range(5,10), index=['a','b','c','d','e'])
print('取某一行 s[i] :', s['a'], type(s['a']))
print('\n')
print('取某几行 s[[i,j]] 或 s[i:j] :', s[['a','c']], type(s[['a','c']]), s['a':'c'], type(s['a':'c']), sep='\n\n')
# 备注:s['a':'c'] 可以改成s[0:2],但其结果不一致
# 行索引:DataFrame
import numpy as np
import pandas as pd
a = pd.DataFrame(np.arange(10).reshape(5,2), index=list('abcde'),columns=['M','N'])
lst = ["a['a']", "a[['a','b']]", "a['a':'c']", "a[0:2]"]
for i in lst:
try:
print(eval(i), end='\n\n')
except:
print('执行错误\n')
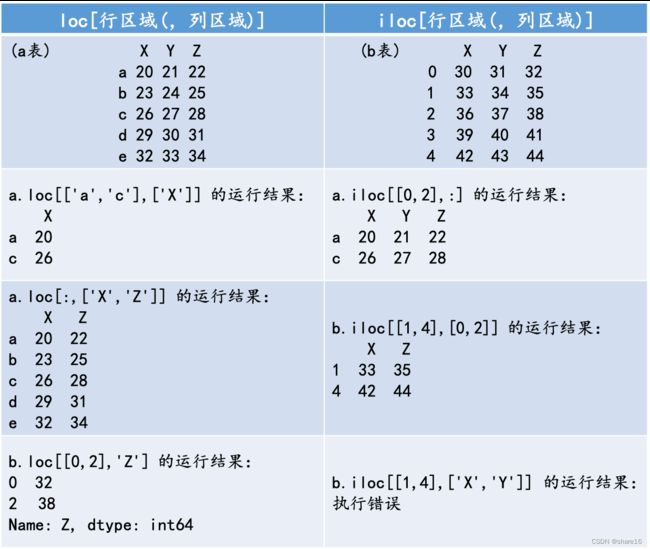
3.1.2 loc索引器、iloc索引器
对于Series/DataFrame而言,有两种索引器,一种是基于‘index和columns的值(索引值可以是str或int)’的loc索引器,另一种是基于‘位置(取值只能是0,1,2,···,与索引值无关)’的iloc索引器。
- loc索引器的一般形式是
loc[行区域,列区域],行区域不能省略,列区域是可以省略的。其行/列区域有五类合法对象,分别是:单个元素、元素列表、元素切片、布尔列表以及函数; - iloc索引器的一般形式是
iloc[行区域,列区域],用法与loc类似,只不过是针对位置进行筛选。
import numpy as np
import pandas as pd
a = pd.DataFrame(np.arange(20,35).reshape(5,3), index=list('abcde'), columns=['X','Y','Z'])
b = pd.DataFrame(np.arange(30,45).reshape(5,3), columns=['X','Y','Z'])
print(a, b, sep='\n\n')
# 行/列区域:是单个元素
lst = ["a.loc['a']", "a.loc['X']", "a.loc[0]", "a.loc['a','X']", "b.loc[1,'Z']", "b.loc[0]","b.iloc[1,2]", "b.iloc[0,'X']"]
for i in lst:
try:
print('{} 的运行结果:\n{}\n'.format(i, eval(i)))
except:
print('{} 的运行结果:\n{}\n'.format(i, '执行错误'))
# 运行结果见下图

# 行/列区域:是元素列表
lst = ["a.loc[['a','c'],['X']]", "a.loc[:,['X','Z']]", "b.loc[[0,2],'Z']", "a.iloc[[0,2],:]","b.iloc[[1,4],[0,2]]", "b.iloc[[1,4],['X','Y']]"]
for i in lst:
try:
print('{} 的运行结果:\n{}\n'.format(i, eval(i)))
except:
print('{} 的运行结果:\n{}\n'.format(i, '执行错误'))
# 运行结果见下图
# 行/列区域:是元素切片
lst = ["a.loc['a':'c' , 'X':'Y']", "b.loc[0:2 , 'X':'Y']", "b.loc[0:2 , 0:]", "a.iloc[0:2 , 0:]","b.iloc[0:2 , 1:3]", "b.iloc[0:2 , 'X':'Z']"]
for i in lst:
try:
print('{} 的运行结果:\n{}\n'.format(i, eval(i)))
except:
print('{} 的运行结果:\n{}\n'.format(i, '执行错误'))
# 运行结果见下图

# 行/列区域:是布尔列表
lst = ["a.loc[a.X > 30]", "b.loc[b.X.isin([42]),['X','Y']]", "a.iloc[a.X > 30]","a.iloc[(a.X > 30).values]"]
for i in lst:
try:
print('{} 的运行结果:\n{}\n'.format(i, eval(i)))
except:
print('{} 的运行结果:\n{}\n'.format(i, '执行错误'))
# 运行结果见下图

# 行/列区域:是函数
lst = ["a.loc[lambda x:'a',lambda x:'X']", "b.loc[lambda x:slice(0,2),lambda x:slice('X','Z')]", "b.iloc[lambda x: slice(1,4)]","b.iloc[lambda x: slice(1,4),1]"]
for i in lst:
try:
print('{} 的运行结果:\n{}\n'.format(i, eval(i)))
except:
print('{} 的运行结果:\n{}\n'.format(i, '执行错误'))
# 运行结果见下图

3.1.3 query方法
筛选查询数据:df.query(condition, inplace, **kwargs)
- condition:默认str类型, 里面可以使用( ==、!=、|、&、~、or、and、or、in、not in等)运算符;若要引用外部变量,只需在变量名前加@符号;
- inplace:默认False;若为True,返回结果会修改原数据;
low,high = 28,36
lst = ["X>X.mean()", "'X>X.mean()'", "'Y in [24,30,36]'","'Z.between(low,high)'", "'Z.between(@low,@high)'"]
for i in lst:
try:
print('a.query({}) 的运行结果:\n{}\n'.format(i, a.query(eval(i))))
except:
print('a.query({}) 的运行结果:\n{}\n'.format(i, '执行错误'))
# 运行结果见下图

3.1.4 随机抽样
若把 DataFrame 的每一行看作一个样本,或把每一列看作一个特征,再把整个 DataFrame 看作总体,想要对样本或特征进行随机抽样就可以用 sample函数,即
Series/df.sample(n,frac,replace,weights,random_state,axis,ignore_index)。
- n:抽样数量;不能与frac一起使用,若frac=None,n则默认为1;
- frac:抽样比例,默认为None,不能与n一起使用;如0.3表示从总体中抽出30%的样本;
- replace:是否有放回抽样;默认False,即不放回抽样;若为True,则是有放回抽样;
- weights:每个样本的抽样相对概率,默认为None;
3.2 多重索引
适用于所有 Series/DataFrame :
- 查看所有 行索引名 和 行索引值 :df.index.names、df.index.values、df.index
- 查看所有 列索引名 和 列索引值 :df.columns.names、df.columns.values、df.columns
- 查看所有 某一层索引 :如df.index.get_level_values(0)
3.2.1 普通列设为索引
df.set_index(keys,drop,append,inplace,verify_integrity)
- keys:某一列或某几列,用列表形式表示;
- drop:默认为True,删除要用作新索引的列;
- append:默认为 False,表示是否保留原来的索引,直接把新设定的索引添加到原索引的内层;
- inplace:默认为 False,若为True,则修改原数据;
- verify_integrity:默认为 False,检查新索引是否有重复项;
3.2.2 多重索引的loc索引器
df.loc[(level_0_list, level_1_list), cols]
df.swaplevel():转换内外层索引
Python输出带颜色字体,如红色字体
import pandas as pd
df = pd.read_excel('/xxx/公司员工.xlsx', parse_dates=['birthdate_key'])
df = df.set_index(['city_name', 'department'])
df.set_index(['department', 'city_name'])
# 上面两个set_index语句的结果不一致
# 多重索引
print("\033[0;30;43m以 df.set_index(['city_name', 'department']) 的结果为例:\n\033[0m")
cols = ['EmployeeID', 'job_title']
lst1 = ['只索引city_name的某几个值:', '只索引department的某几个值:', '索引city_name和department的某一个值:', '索引city_name和department的某几个值:']
lst2 = [r"df.loc[['Terrace', 'Nanaimo'] , cols]", r"df.swaplevel().loc[['Store Management', 'Meats'], cols].swaplevel()", r"df.loc[('Terrace', 'Meats'), cols]", r"df.loc[(['Terrace','Vancouver'], ['Meats','Training']), cols]"]
for i,j in zip(lst1,lst2):
try:
print('\033[0;31;40m')
print(i+j, '\n运行结果:')
print('\033[0m')
print(eval(j))
except:
print('\033[0;31;40m')
print(i+j, '\n运行结果:')
print('\033[0m')
print('执行错误')

3.2.3 其他
Slice对象一共有两种形式,第一种为loc[idx[行区域,列区域]]型,第二种为loc[idx[行区域],idx[列区域]]型。(前提是:索引不重复的;使用 silce 对象,要先进行定义,即:idx = pd.IndexSlice。)
多级索引的构造:除了使用set_index之外,常用的有from_tuples、from_arrays、from_product三种方法,它们都是pd.MultiIndex对象下的函数。
- from_tuples:根据传入由元组组成的列表进行构造;
- from_arrays:根据传入列表中,对应层的列表进行构造;
- from_product:根据给定多个列表的笛卡尔积进行构造;
3.2.4 索引的常用方法
如:swaplevel、reorder_levels、droplevel、rename_axis、rename、set_index、reset_index、reindex等。

3.3 练习
3.3.1 公司员工数据集
现有一份公司员工数据集点此下载
import pandas as pd
df = pd.read_csv('/xxx/02 公司员工.csv', parse_dates=['birth'])
#1. 分别只使用query和loc选出年龄不超过四十岁且工作部门为Dairy或Bakery的男性。
df.query(" (age <= 40) and (department in ['Dairy','Bakery']) and (gender == 'M') ")
df.loc[(df.age <= 40) & (df.department.isin(['Dairy','Bakery'])) & (df.gender == 'M')]
#2. 选出员工ID号为奇数所在行的第1、第3和倒数第2列
df.query('id%2==1').iloc[:, [0,2,-2]]
df.iloc[(df.id%2==1).values, [0,2,-2]]
# 3. 按照以下步骤进行索引操作:
# 把后三列设为索引后交换内外两层,df.columns.tolist()把结果转换成列表
df1 = df.set_index(df.columns[-3:].tolist()).swaplevel(0,2)
# 恢复中间层索引
df1 = df1.reset_index(1)
# 修改外层索引名为Gender
df1 = df1.rename_axis(index={'gender':'Gender'})
# 用下划线合并两层行索引
df1.index = df1.index.map(lambda x : '_'.join(x))
# 把行索引拆分为原状态,若把tuple换成list,返回结果有问题
df1.index = df1.index.map(lambda x : tuple(x.split('_')))
# 修改索引名为原表名称
df1 = df1.rename_axis(index=['gender','department'])
# 恢复默认索引并将列保持为原表的相对位置
df1 = df1.reset_index().reindex(df.columns, axis=1)
df1.equals(df)
3.3.2 巧克力数据集
现有一份关于巧克力评价的数据集点此下载
import pandas as pd
df = pd.read_csv('/xxx/03 巧克力.csv', encoding='ISO-8859-1')
# 思路:查看cocoapercent数字类型,若是str,将其转换成float(df.cocoapercent.unique()有小数,所以是float)
df['cocoapercent'] = df.cocoapercent.map(lambda x : float(x[:-1])/100 )
# 选出2.75分及以下且可可含量 cocoapercent 高于中位数的样本
df.query(" (rating <= 2.75) and (cocoapercent > cocoapercent.median()) ")
# 将reviewdate和location设为索引,选出reviewdate在2012年之后且location不属于 France, Canada, Amsterdam, Belgium 的样本
df.set_index(['reviewdate','location']).query(" (reviewdate < 2012) and (location not in ['France', 'Canada', 'Amsterdam', 'Belgium']) ")
四、分组
4.1 分组函数
df.groupby(by,axis,level,as_index,sort,group_keys,squeeze,observed,dropna)
- by:列名或列名列表; level:默认None,级别名称;
- as_index:默认True,返回以组标签为索引的对象;
- sort:默认True,对组键进行排序;
- group_keys:默认True,调用 apply 时,将组键添加到索引以识别片段;
- squeeze:默认False,若可能,减少返回类型的维数,否则返回一致的类型;
- observed:默认False,这仅适用于任何 groupers 是分类的;若为True,仅显示分类分组的观察值;若为 False,显示分类分组的所有值;
- dropna:默认True,且组键包含 NA 值,则 NA 值连同行/列将被删除;若为 False,NA 值也将被视为组中的键;
- 通过
ngroups属性,可以返回分组个数; - 通过
groups属性,可以返回从组名映射到组索引列表的字典; - 通过
size属性,可以返回groupby对象上每个组的元素个数; - 通过
get_group属性,可以返回所在组对应的行(必须知道组的名字); - 通过
list(df.groupby(···))属性,可以将DataFrameGroupBy类型转换成列表;
4.2 聚合函数
4.2.1 内置聚合函数
df.groupby(by=xxx)[列名组合].使用操作
使用操作/内置聚合函数:max/min/sum/count/std/median/mean/all/any/idxmax/idxmin/mad/unique/nunique/skew/quantile/sem/size/prod等;
4.2.2 agg/transform/apply方法
Series/df.agg(func,···):在指定轴上使用一项或多项操作进行聚合;
Series/df.transform(func,···):调用func生成转换后的值,且具有与Series/df相同的轴长的数据;
Series/df.apply(func,···):调用func生成转换后的值;
import pandas as pd
df = pd.read_csv('/xxx/04 汽车.csv')
a = df.groupby('Country')
lst1 = ['使用一个函数:', '使用多个函数:', '对特定的列使用特定的聚合函数:', '对特定的列使用特定的聚合函数:', '使用自定义函数:', '聚合结果重命名(用元组表示,即(名字,函数)):']
lst2 = [r"a['Disp','HP'].agg('mean')", r"a['Disp','HP'].agg(['mean','std'])", r"a['Disp','HP'].agg({'Disp':'mean', 'HP':['mean','std']})", r"a['Disp','HP'].agg({'Disp':'mean', 'HP':'mean', 'HP':'std' })", r"a['Disp','HP'].agg(lambda x : x.max()-x.min())", r"a['Disp','HP'].agg([('my_max','max'), ('my_min','min')])"]
for i, j in zip(lst1,lst2):
print('\033[0;30;43m')
print(i+j, '\n')
print('\033[0m')
print(eval(j))
''' agg/transform/apply的区别: '''
a['Price'].agg('mean') #返回各城市的平均价格;若使用多个函数,以列表形式表示;
a['Price'].transform('mean') #返回各城市的平均价格;不能使用多个函数;
a['Price'].apply('mean') #返回各城市的平均价格,其与df有相同的长度;不能使用多个函数;



备注:
对特定列使用特定函数时,需要使用{'列名' : [('重命名',func1), func2]}等,详见本文4.4.1版块的问题1。
4.3 变换和过滤
变换函数的返回值为同长度的序列,最常用的内置变换函数是累计函数: cumcount/cumsum/cumprod/cummax/cummin ,它们的使用方式和聚合函数类似,只不过完成的是组内累计操作。
组过滤(df.filter(func))作为行过滤的推广,指的是如果对一个组的全体所在行进行统计的结果,返回True则会被保留,False则该组会被过滤,最后把所有未被过滤的组其对应的所在行拼接起来作为DataFrame返回。
4.4 练习
4.4.1 汽车数据集
现有一份汽车数据集点此下载,其中Brand、Disp、HP,分别代表:汽车品牌、发动机蓄量、发动机输出;
问题:
1. 先剔除所属 Country 数不超过2的汽车,再按 Country 分组计算价格均值、价格变异系数、该 Country 的汽车数量,其中变异系数的计算方法是标准差除以均值,并在结果中把变异系数重命名为 Cov;
import pandas as pd
df = pd.read_csv('/xxx/04 汽车.csv')
# 剔除所属 Country 数不超过2的汽车
a = df.groupby('Country').filter(lambda x : x.shape[0] > 2)
a.groupby('Country').agg({'Price' : ['mean', ('Cov',lambda x : x.std()/x.mean()), 'count']})
# 2. 按照表中位置的前三分之一、中间三分之一和后三分之一分组,统计 Price 的均值;
n = int(df.shape[0]/3)
condition = ['Head']*n+['Mid']*n+['Tail']*n
df.groupby(condition)['Price'].mean()
# 3. 对类型 Type 分组,对 Price 和 HP 分别计算最大值和最小值,结果会产生多重索引,请用下划线把多重列索引合并为单层索引;
b = df.groupby('Type')['Price','HP'].agg({'Price':['max'], 'HP':['min']})
b.columns = b.columns.map(lambda x : '_'.join(x))
b
# 4. 对类型 Type 分组,对 HP 进行组内的 min-max 归一化;
df.groupby('Type').HP.transform(lambda x : ((x - x.min())/(x.max() - x.min())))
# 5. 对类型 Type 分组,计算 Disp 与 HP 的相关系数;
df.groupby('Type')['Disp','HP'].corr().swaplevel().loc['Disp','HP']
# 等价于
df.groupby('Type')[['HP', 'Disp']].apply(lambda x:np.corrcoef(x['HP'].values, x['Disp'].values)[0,1])
谢谢大家