nlp--task:NLG
注:基本来源于CS224n-2019的第15课件,在6月下旬学到了第14课并完成了assignment1-4,后面因为一些原因断断续续的看的并不仔细,恰好7月初暑假开始找了一些开源项目学习学习(中文-NER,情感分析)。练完之后觉得是时候再去好好看看课程了,第15个课件是博士生Abigail see在nlg方面上研究现状的概述以及个人经验分享--------------------------------2019-07-17
cs224n官网链接
NLG(natural language generation)
• Machine Translation
• (Abstractive) Summarization
• Dialogue (chit-chat and task-based)
• Creative writing: storytelling, poetry-generation
• Freeform Question Answering (i.e. answer is generated, not extracted from text or knowledge base)
• Image captioning 【 ( : 】
• …
Section-1,LMs and decoding algorithms
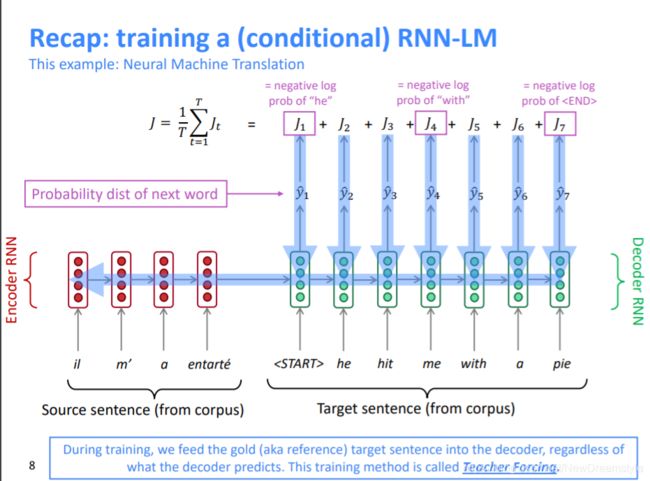
1-1,Language Modeling-【LM】语言模型:
给定前 t 个 单词/语句预测第t+1个单词/语句的任务
p ( y t + 1 ∣ y 1 , . . . y t ) p(y_{t+1}|y_1,...y_t) p(yt+1∣y1,...yt)
1-2,Conditional Language Modeling 条件语言模型:
同上,但有另外的输入x
p ( y t + 1 ∣ y 1 , . . . y t , x ) p(y_{t+1}|y_1,...y_t,x) p(yt+1∣y1,...yt,x)
下面是CLM的几个例子:
• Machine Translation—机器翻译 (x=源语言, y=目标语言)【可以去了解一下HMM,CRF】
• Summarization----------文章总结 (x=原文章, y=原文章总结)
• Dialogue------------------ 对话任务 (x=对话历史, y=下一句话)
【*注:分清train 和 test!】

1-3,Decoding Algorithm
A decoding algorithmis an algorithm you use to generate text from your language model
最好不要翻译成解码,目前的很多思想就是使概率最大的词成为预测对象
整个其实就是一种最短路径问题
• Greedy decoding 【贪心搜索不太现实,可以去了解一下维特比算法的缺点(当然这和维特比算法还是有区别的)】
• Beam search
不同于贪心的将词库中所有词都拿出来进行打分,beam search只根据decoder的输出抽出优先度最高的k个单词,这样不能保证得到最优解,但是极大的提高了运算速度【可以参考word2vec的负采样算法 negative-sampling】。
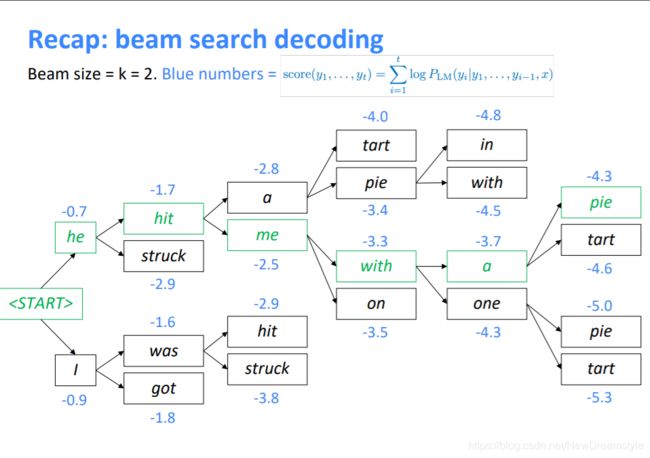
打分机制(这里的1/t标准化是很有必要的----------因为随着句子的增长分数会越来越低): s c o r e ( y 1 , . . . y t ) = 1 t l o g P L M ( p 1 , . . . p t ∣ x ) = 1 t ∑ i = 1 t l o g P L M ( y i ∣ y 1 , . . y i − 1 , x ) score(y_1,...y_t) =\dfrac{1}{t}logP_{LM}(p_1,...p_t|x)=\dfrac{1}{t} \sum_{i=1}^t logP_{LM}(y_i|y_1,..y_{i-1},x) score(y1,...yt)=t1logPLM(p1,...pt∣x)=t1i=1∑tlogPLM(yi∣y1,..yi−1,x)
实际当中k通常设置为5-10,下图是算法效果随着k值变化的情况

课件中主要提到k过大时候可以考虑更多的词,解决了k较小时的语法等问题 ,但是
—1,在神经机器翻译中会导致BLEU分数过低【BLEU主要基于模型预测语句(candidate)和标准目标语句(target)中词共现来评分,当k较大,那么每歩考虑的单词也越多所以不确定性也越大。个人人为这不能算是一种缺点 ) : 】。
—2,在开放性任务中(hey, Siri)会导致过于普遍性的回答比如 不管你问什么都回答i don’t konw / fine。
另外beam search 是在测试阶段为了获得更好的准确性而采取的一种策略,在训练阶段无需使用
• Sampling-based decoding【基于采样的解码方式】
有两种方式:
1,pure sampling(纯采样):指完全不考虑argmax,在语料中随机选择一个
2,Top-k sampling :基于argmax 的方法,先选出前k个最优选项,在这n个候选项中随机选择一个。值得深思的是,

当k越大时:get more diverse/risky output;当k越小时:get more generic/safe output.
乍一看,这似乎与beam search相矛盾,但事实你需要分清采样和beam search的不同,而且它们的generic也是有所区别的。在beam search和Top-n sampling中 k都是decoder基于argmax找出的前k个候选单词,但之后的选择最终单词的方式是不同的,beam-search因为其打分机制它要额外考虑整个x,所以如果候选单词越多它越想选择更通用的单词,及k越大越倾向于整句的贪婪,得到的回复也就越通用;top-n sampling则是在k个候选中随机找出一个(它没有考虑x)所以增加k纯粹就是增加了选择性,减少了k也就只能选择那些较优先的单词。
【注,个人认为初始候选的k个单词的优先级和最终被选择的优先级并不是强相关,但也不算是弱相关。不这么想的话不太好理解,打算做一下这方面的研究】
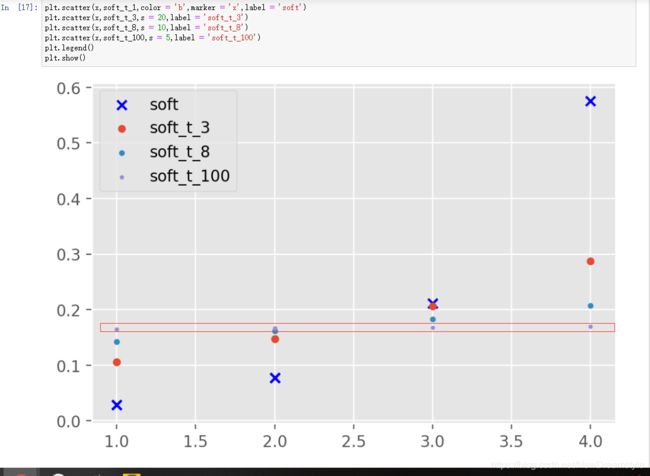
• Softmax temperature相关链接
这个我就直接上课件了,不做解释。图二是我针对t的不同做的一个可视化可以更直观的感受一下
(t增大,每个种类间的不同会被削弱。图二中当t=100时,每个点概率几乎相同)

Section-2,NLG tasks and neural approaches to them
1,Summarization【总结,文章摘要】
这里主要讨论神经模型—neural summarization
1_1,copy mechanisms
主要是利用attention进行copy,这种方法有很多问题,不多叙述
1_2,bottom-up-summarization
自底向上的摘要式总结,Bottom-Up Abstractive Summarization, Gehrmann et al, 2018
主要解决了神经网络在内容选择上表现不佳的问题
2,Dialogue【对话系统】!
我的兴趣方向【段位太低,不能说是研究方向…哈哈】
对话系统包含任务导向对话AI assistant【比如iron man jarvis系统】和社交对话。比较常见的也就是问答系统
等级介绍;github开源项目;精品博客-1;精品博客-2
2_1,seq2seq-based dialogue
由于之前seq2seq-attention的火爆,很多对话系统是基于这个模型的。但是它存在许多缺点:
• Genericness(无聊没用的回复);
-------使用sampling decoding algorithm而不使用beam search,或者给与这些词汇较大惩罚力度
还有 conditioning fixes 目前水平不够还未研究,Why are Sequence-to-Sequence Models So Dull?, Jiang et al, 2018
•Irrelevent response(不相关的回复);
------采取在input S 和回复 T中优化最大互信息【maximum mutual information】 l o g p ( S , T ) p ( S ) p ( T ) log\dfrac{p(S,T)}{p(S)p(T)} logp(S)p(T)p(S,T)
•Repetition(重复严重);
------简单高效的办法:直接禁止这类输出…
•Lack of context(记不住之前的对话内容);
•Lack of consistent person(满满的机器感…)
此外还有 negotiation dialogue;conversational question answering: CoQA等等,这不再叙述
3,Storystelling
讲故事–,很多开发者大会都会拿AI创作诗词来装哔,个人觉得毫无意义,毫无意义,毫无意义!(勿喷)。如下图是根据泰勒斯威夫特的歌词(情歌为主)为训练集所生成的一段话

滑稽吗…或者浪漫?
Section-3,NLG evaluation
对于生成的语句我们需要评估
1-流畅度
2-准确性
3-切题度
4-多样性
5-简洁性
目前还没有是什么大统一的自动评估方案,只能逐个关注并解决
比较常见的— BLEU; ROUGE; METEOR; F1 等等都是属于 word overlap based metrics。
但是越开放性的任务,这种评估方式效果越差。
还有一种是基于similarity of the wording embedding的评估方法,效果同样感人。
需要寻找不再是基于word的评估方式,比方说整个词库?因果关系?
个人觉得这一方面很难说一千个人眼里有一千个哈姆雷特,即使是个真人碰到一个变态或者…也是会卡壳。我觉得需要参考LSTM 的门思想,以dialogue为例,特别要注重conversation之间的tradeoff,就是我不单单要思考怎么回答(生成语句),也要思考你为什么这么问 ,你为什么对我前一次的回答做出这样的回应等等等。
Section-4,Thoughts on NLG research

我个人的想法
现在NLG 普遍是基于NMT的模型结构【word embedding encoder decoder attention】,不可否认的是这些思想在翻译等方面的确很高效,但若是想接近人与人之间的交流,挑战这种开放性的任务,我觉得是需要跳出这种圈子(似乎是废话…哈哈),因果关系,知识图谱似乎能带来许多光明。语言是复杂,神奇,且富有创造力的。这些传统的基于概率的评估方式,训练方式我觉得不会是最终模板。或许是我无知者无畏…

我们都很期待,但如果哪天真的做出来了,通过了某某测试。。。从你脑海闪过的是恐惧还是兴奋呢
2019-07-19-05:55