2019 VisualBERT: a Simple and Performant Baseline for Vision and Language
摘要
我们提出VisualBERT,一种建模广泛视觉和语言任务的简单和灵活的框架。VisualBERT包含一些Transformer层的堆叠,这些层隐式的将输入文本和与输入图像相关的区域与自注意力对齐。我们进一步提出了两个基于视觉的语言模型目标来预训练图像标题数据的VisualBERT。在VQA、VCR、NLVR、和Flickr30K这四个视觉和语言任务上的实验表明,VisualBERT优于先进模型,且简单得多。进一步的分析表明,VisualBERT可以在没有任何显式监督的情况下将语言元素接地到图像区域上,甚至对语法关系很敏感,例如跟踪动词和与其论据对应的图像区域之间的关联。
一、介绍
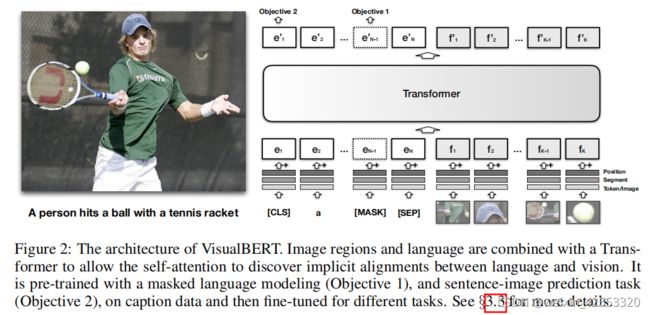
我们提出的VisualBERT,设计用于捕获图像和相关文本中的丰富语义。它整合了BERT和预训练的对象提案系统如Faster-RCNN。从对象提案中提取的图像特征被视为无序的输入表示,并与文本一起输入到VisualBERT中,文本和图像输入被多个Transformer层共同处理(如图2)。单词和对象提案之间丰富的交互作用使模型能捕捉到文本和图像之间的复杂关联。
与BERT类似,对外部资源预训练的VisualBERT可以有利于下游应用。为学习图像和文本之间的关联,我们考虑用图像标注数据(其中图像的详细语义用自然语言表示)预训练VisualBERT。我们提出两个基于视觉接地的语言模型进行预训练:(1)部分文本被掩盖,模型根据剩余的文本和视觉上下文学习预测掩码的词;(2)模型被训练以确定所提供的文本是否与图像相匹配。我们表示,这种在图像标注数据上的预训练对VisualBERT学习可转移文本和视觉表示非常重要。
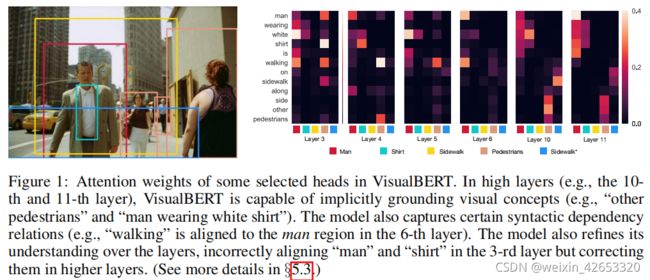
我们在四个视觉和语言任务上进行多个实验:(1)视觉问答(VQA2.0);(2)视觉常识推理;(3)视觉推理的自然语言(NLVR);(4)区域到词组的接地(Flickr30K)。结果表明,通过在COCO图像标题数据集上预训练VisualBERT,VisualBERT优于最先进的模型。我们进一步提供了详细的消融研究,以证明设计选择。进一步的定量和定性研究揭示了VisualBERT如何分配注意力权重来内部对齐词和图像区域。我们证明通过预训练,VisualBERT学习接地实体和编码词和图像区域间的某些依赖关系,这有助于改善模型对图像的详细语义的理解(图1)。
二、相关工作
理解图像中的详细语义对图像理解是关键的,之前的研究表明建模这种语义可以有益视觉和语言模型。在VisualBERT中,自注意力机制允许模型捕捉对象间的隐含关系,而且,我们认为在图像标注数据上预训练是教模型如何捕捉这种关系的有效方法。
三、视觉和语言的一种联合表示模型
3.1 背景
BERT是一种子词作为输入,使用语言建模目标进行训练的Transformer。一个输入句子中的所有子词都被映射到一组嵌入E,每个嵌入e被计算为以下的总和:1)特定于子词的一种标记嵌入et;2)一种分割嵌入es,表示标记来自文本的哪部分(如隐含对的假设);3)一种位置嵌入ep,表示标记在句子中的位置。输入嵌入E然后被送入一个多层Transformer,构建子词的上下文表示。
BERT的训练通常分为两步:预训练和微调。预训练使用两个语言建模目标的结合来做:(1)掩码语言建模:输入标记的一些部分被一个特殊标记随机取代,如[MASK],模型需要预测这些标记的身份,(2)下一个句子预测,其中给模型一个句子对,并训练对它们是否是文档中的两个连续句子进行分类。最后,为了将BERT应用于特定的任务,引入了特定于任务的输入、输出层和目标,并根据预先训练好的参数对任务数据对模型进行微调。
3.2 VisualBERT
想法的核心是用Transformer中的自注意力机制来隐式对齐文本和输入图像中的区域。除BERT的所有组成部分,我们引入一组视觉嵌入F,以建模一个图像。每个f对应于图像中的一个边界区域,来自一个对象检测器。
F中的每个嵌入通过对以下三个嵌入的总和进行计算:1)fo,通过一个卷积神经网络计算的边界区域f的一个视觉特征表示;2)fs,表示它是一个图像嵌入而不是文本嵌入的一种分割嵌入;3)fp,一种位置嵌入,当单词和边界区域之间的对齐作为输入的一部分时使用,并设置为对齐的单词对应的位置嵌入的总和。之后将视觉嵌入和原始的文本嵌入一起送入多层Transformer,允许模型隐式地发现两个输入之间的有用的对齐,并建立一个新的联合表示。
3.3 训练VisualBERT
我们的训练过程包含三个阶段:
任务不可知预训练:我们使用两个视觉接地语言模型目标在COCO上训练VisualBERT,(1)图像的掩码语言建模,文本输入的一些元素被掩盖,而对应的图像区域的向量不被掩盖;(2)句子-图像预测,对于COCO,其中有多个标注对应于一个图像,我们提供了一个由两个标注组成的文本片段,其中一个标注是描述图像,而另一个有50%的机会是另一个相应的标注,50%的机会是一个随机绘制的标注。该模型被训练来区分这两种情况。
特定任务的预训练:在将VisualBERT微调到下游任务之前,我们发现使用图像目标的掩码语言建模的任务的数据来训练模型是有益的。此步骤允许模型使用新的目标域。
微调:这一步反映了BERT微调,其中引入了特定于任务的输入、输出和目标,并训练Transformer以最大限度地提高任务的性能。
四、实验
对每个数据集,我们评估我们模型的三种变体:
VisualBERT: 具有BERT参数初始化的完整模型,进行COCO预训练、对任务数据进行预训练和对任务进行微调。
有/没有早期融合的VisualBERT: 图像表示和文本不是在最初的Transformer层中融合,而是在最后一个新的Transformer层中,使测试通过整个Transformer堆栈中语言和视觉间的交互对性能是否重要。
有/没有COCO预训练的VisualBERT: 我们跳过关于COCO标注的任务不可知的预训练,使我们能够验证这一步骤的重要性。
4.1 VQA
使用VQA 2.0,结果图表1,包括使用与我们的方法(第一部分)相同的视觉特征和边界区域建议数量的基线,我们的模型(第二部分),以及其他无与伦比的方法(第三部分),使用外部问答对来自视觉基因组(+VG),多个检测器(+Multiple Detectors)和它们的模型的集合。在类似的设置下,我们的模型明显更简单,并且优于现有的工作。

五、分析
本部分我们进行广泛分析,关于我们方法的哪些部分对VisualBERT的强壮性能是重要的。
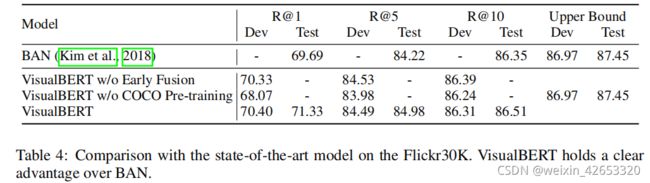
六、总结和将来工作
我们提出VisualBERT,一种共同的视觉和语言表示的预训练模型,尽管VisualBERT简单,但在四个评估任务上实现强烈的性能。将来的分析表示,模型使用注意力机制以可解释的方式捕获信息。在未来的工作中,我们很好奇是否可以将VisualBERT扩展到仅限图像的任务,如场景图解析和情况识别。在更大的标题数据集上的视觉基因组和概念标题也是一个有效的方向。