NLG一、seq2seq详解以及相应trick介绍

paper:https://arxiv.org/pdf/1406.1078.pdf
code:https://github.com/google/seq2seq
18年的时候使用这个模型做标题生成,今天来总结一下这个比较经典的模型结构。对于自动摘要或者标题生成的任务,一般有两种方法:抽取式和生成式。其中抽取式是从文章中对段落和句子打分进行抽取,而生成式是根据输入序列模型直接输出一个序列,相对比较智能一些,而本次分享的这篇论文就是生成式的一个经典框架。本论文是在2014年Google Brain团队和Yoshua Bengio 两个团队提出的,最初的主要目的是解决机器翻译问题,同时首次提出了GRU和Encoder-Decoder模型,也称为seq2seq。
一、seq2seq模型概要
Seq2Seq模型主要是用来解决将一个序列X转化为另一个序列Y的一类问题,比如机器翻译、自动摘要、对话系统中答案的生成等等都可以使用这个框架。这个过程有点类似比较传统的HMM、MEMM、CRF, 通过一系列随机变量X,去预测另外一系列随机变量Y。但是不同的是,HMM模型中的随机序列与随机变量系列一一对应而Seq2Seq模型则并不是指一一对应的关系。
Seq2Seq生成模型的主要思路是在已知输入序列和前序生成序列的条件下,最大化下一目标词的概率,而最终希望得到的是整个输出序列的生成出现的概率最大:
说明:
1、其中T表示输出序列的时间序列大小,y1:t-1表示输出序列的前t-1个时间点对应的输出,X为输入序列。通常情况下,训练模型的时候y1:t-1使用的是ground truth tokens,然而在测试过程中,ground truth tokens是不可知的,需要使用前序预测到的y‘1:t-1来表示,这将会引发问题Exposure Bias。
2、在预测输出序列的每个token时,采用的都是最大化下一目标词(token)的概率,来得到token,对于整个句子或者说序列来说,这种解法是贪心策略,带来的是局部最佳。对于一个端到端的生成应用来说,目标是整个序列是最佳的,换句话说,希望最后的生成序列的tokens顺序排列的联合概率最大,找到一个全局最优。
二、seq2seq模型结构
seq2seq模型主要分为两个部分:Encoder和Decoder。Encoder主要完成对输入数据的编码,Decoder是对编码后的向量进行解码来输出整个输出序列。

上图Figure1是seq2seq的基本结构,Encoder把输入序列[x1,x2,…,xm](由m个固定长度为d的向量构成)使用RNN、LSTM、GRU以及BILSTM等等常用的序列编码器进行编码后,形成一个语义向量C;Decoder基于这个C向量输出输出序列为[y1,y2,…,yn](由n个固定长度为d的向量构成),输入序列和输出序列的长度可以不一样。
注意:输入和输出序列的向量维度是一样的,而且共用一个词表。
1)首先说明Encoder的计算过程,每个 X 代表一个句子中的每个词;每个圈代表每个隐藏状态,用 h 表示。用 t 代表时间,所以 h 如下计算(其中 f 是激活函数)。算完每个 h,就表示这个句子已经读完了。
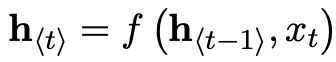
2)最后一个隐藏状态就是整个输入序列的向量表示了,使用向量C来表示。
3)再次说明一下Decoder的计算过程,由于Decoder需要顺序解码,因此只能使用单向的RNN、LSTM或者GRU了,隐藏状态计算与Encoder的区别是:所有的隐藏单元的输入都是Encoder的语义向量C,而且还增加了输出y作为输入,公式如下:

最终每个词的输出使用如下公式计算:
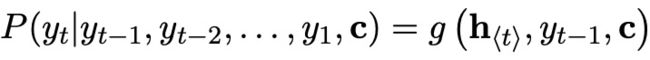
这里的激活函数g要对应输出到词表里的词,一般采用softmax作为激活函数。
4)最终模型的目标是要求解所有训练中输入数据与输出数据pair对的平均最大,损失函数如下:
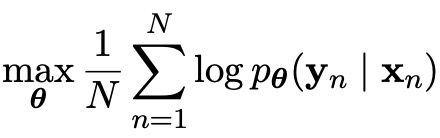
θ是模型的参数,n是训练数据的样本数量。
扩展:深入理解Encoder-Decoder框架,其实Encoder和Decoder都可以采用多层来实现。*****
三、seq2seq+attention模型结构
从传统的seq2seq框架可以看出,Encoder是把所有的输入序列编码为一个固定的语义向量C,由于RNNs长依赖的问题,这个向量并不能包含所有的输入序列信息;而Decoder又受限于这个向量C的表示。论文《Neural Machine Translation by Jointly Learning to Align and Translate》提出了attention机制来解决这个问题。模型结构如下图所示:

Encoder阶段使用BiRNN来进行编码,将Encoder中的每一个时刻的隐藏状态都保存至一个列表中[h1,h2,…,hm],在Decoder解码每一个时刻i的输出时,都需要计算Encoder的每个时刻的隐藏状态hi与Decoder的输出时刻的前一个时刻的关系si-1的关系,进而得到Encoder的每个时刻的隐藏状态对Decoder该时刻的影响程度。如此,Decoder的每个时刻的输出都将获得不同的Encoder的序列隐藏状态对它的影响,从而得到不同的语义向量Ci。
seq2seq+attention框架与原始的seq2seq最重要的区别在于Decoder引入Encoder端语义向量C的方式不一样,下面是seq2seq+attention的方式:

Decoder阶段的每个时刻的隐藏状态si,都会根据由Encoder阶段的隐藏状态序列对Decoder阶段上一个时刻(i-1)的隐藏状态的影响也就是我们的语义向量Ci和上一时刻的的状态si-1,上一个时刻的输出yi-1三者通过一个非线性函数得出。Decoder阶段每次解码一个词的时候都会对应不同的Encoder阶段的语义向量Ci,Ci是根据Encoder编码阶段的各个隐藏状态(向量)的权重和,下面介绍一下该语义向量的计算方式:
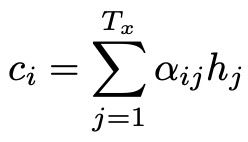
此公式中每个时刻的权重αij表示Encoder编码阶段的第j个隐藏状态对Decoder解码阶段的第i个隐藏状态的权重影响。hj就是Encoder阶段每个时刻的隐藏状态。


其中,eij为Encoder编码阶段的第j个隐藏状态和Decoder解码阶段的第i-1个隐藏状态的联合前馈网络关系。a是一个前馈神经网络,比如形式如下:

总结一下:整个计算Ci的过程为:分别计算Encoder编码阶段的每个隐藏状态和Decoder解码阶段的第i-1个隐藏状态前馈关系,再进行Softmax归一化处理计算出该Encoder编码阶段的隐藏状态的权重aij,最后将所有的Encoder编码阶段的隐藏状态的进行权重求和。
四、seq2seq模型的不足以及解决的trick
4.1、OOV与低频词
问题描述:OOV表示的是词汇表外的未登录词,低频词则是词汇表中的出现次数较低的词。在Decoder阶段时预测的词来自于词汇表,这就造成了未登录词难以生成,低频词也比较小的概率被预测生成。
trick1(Pointer-Generator):
论文《Abstractive Text Summarization using Seq2Seq RNNs and Beyond》中使用Pointer-Generator机制来解决OOV和低频词问题。由于文本摘要的任务的特点,很多OOV 或者不常见的的词其实可以从输入序列中找到,因此一个很自然的想法就是去预测一个开关(switch)的概率P(si=1)=f(hi,yi-1,ci),如果开关打开了,就是正常地预测词表;如果开关关上了,就需要去原文中指向一个位置作为输出。
trick2(copy机制):
当生成一段文本的时候,这个生成单词可以有两种来源:一种是通过普通seq2seq生成;另一种是从原文本拷贝过来(这就是copy机制),比较有代表性的是下面两篇paper:《Get To The Point: Summarization with Pointer-Generator Networks》和《Incorporating Copying Mechanism in Sequence-to-Sequence Learning》。
《Get To The Point: Summarization with Pointer-Generator Networks》:
将每步输出的单词概率看作一个混合模型(生成的单词概率分布与拷贝原文的单词概率分布的混合),利用注意力得分作为拷贝单词的概率,公式如下:
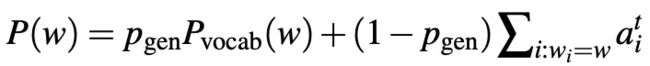
《Incorporating Copying Mechanism in Sequence-to-Sequence Learning》:

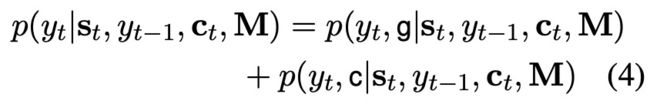 M是输入隐藏层状态的集合,ctct是attention score,stst是输出的隐藏状态,g代表生成,c代表复制。
M是输入隐藏层状态的集合,ctct是attention score,stst是输出的隐藏状态,g代表生成,c代表复制。
生成还是复制基于概率最大来选择,加了一个简单的限制规则,如果yt在输入中没出现,那么肯定不会是copy,p(yt,c|∗)=0;如果yt在只输入中出现,而词表中没有,那么肯定是copy,p(yt,g|∗)=0。
为了复制较长短语,作者改变了yt−1的表达式,加了一项selected read。yt−1的表达式由两项拼接而成,第一项是词的embedding,第二项叫做selective read,其目的是为了拷贝较长的短语。理解的话很直观,如果前一个词在输入中出现了,那么有一个权重的累加,否则为零。
trick3(pointer softmax):
《Pointing the Unknown Words》,本篇提出了pointer softmax的机制,为了解决copy or generate 和 where to copy两个问题。也称为pointer-generator network。
1)copy or generate
用一个参数ztzt来决定是point,copy还是generate,用一个多层感知机来预测。输入由当前时刻attention得出的语义向量ctct和前一时刻decoder的隐藏层状态st−1st−1以及输出yt−1yt−1拼接构成。其实这个多层感知机的输入和NMT中decoder预测下一状态的输入是一模一样的,只是一个是学习对应的位置,一个是学习预测每个词的概率。
2)where to point
在attention softmax的基础上,额外用了一个location softmax来解决where to point的问题。目标是max p(lt|zt=0,(y,z) 4.2、Encoder阶段的Beam Search 问题描述:我们知道在Seq2Seq模型的最终目的是希望生成的序列发生的概率最大,也就是生成序列的联合概率最大。在实际预测输出序列的每个token的时候,采用的都是最大化下一目标词(token)的概率,因为Decoder的当前时刻的输出是根据前一时刻的输出,上一个时刻的隐藏状态和语义向量Ci.通过依次求每个时刻的条件概率最大来近似获得生成序列的发生最大的概率,这种做法属于贪心思维的做法,获得是局部最优的生成序列。 trick:论文《Sequence-to-Sequence Learning as Beam-Search Optimization》论文中提出Beam-Search来优化上述的局部最优化问题。Beam-Search属全局解码算法,Encoder解码的目的是要得到生成序列的概率最大,可以把它看作是图上的一个最优路径问题:每一个时刻对应的节点大小为整个词汇表,路径长度为输出序列的长度。可以由动态规划的思想求得生成序列发生的最大概率。假设词汇表的大小为v,输出序列的长度为n.设t时刻各个节点(各个词w)对应的最优路径为dt=[d1,d2,…,dv].则下一个时刻(t+1)的各个节点对应的最优路径为dt加上t时刻的各个节点(各个词w)到(t+1)的各个节点(各个词w)的最短距离,算法的复杂度为o(nv^2).因为词汇表的大小v比较大,容易造成算法的复杂度比较大。为了降低算法的复杂度,采用Beam Search算法,每步t只保留K个最优解(之前是保留每个时刻的整个词汇表各个节点的最优解),算法复杂度为o(nKv)。 扩展:然而实际中Beam-Search由于它总是选择一条分支路径,导致最后的解码结果都差不多,缺乏多样性,改进措施如下: 思路一:通过增加惩罚项,比如对同一组的第二、第三选项进行降权,从而避免每次搜索结果都来自于同一路径。对于权重的选择,可以通过强化学习得到;也可以通过设置参数、调整参数来得到。 思路二:计算每条路径的概率分,如果后面生成的话跟第一组相似,就对该组进行降权,避免组与组之间相似度过高。 4.3、Exposure Bias 问题描述:Seq2Seq模型训练的过程中,解码阶段下一时刻的输出是需要依赖上一时刻的输出和上一时刻的隐藏状态和语义变量Ci.此时上一时刻的输出使用的是ground truth token;而在验证Seq2Seq模型的时候,由于不知道上一时刻的真实token,上一时刻的输出使用的是上上个时刻的预测的输出token,这将引发Exposure Bias(曝光偏差问题)。 trick:使用Beam Search的Encoder的方式也能一定程度上降低Exposure Bias问题,因为其考虑了全局解码概率,而不仅仅依赖与前一个词的输出,所以模型前一个预测错误而带来的误差传递的可能性就降低了。论文《Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks》中提出了DAD的方法,论文中提到Exposure Bias的主要问题是训练过程中模型不曾接触过自己预测的结果,在测试过程中一旦预测出现错误,那么模型将进入一个训练过程中从未见过的状态,从而导致误差传播。论文中提出了一个训练过程逐渐地迫使模型处理自己的错误,因为在测试过程中这是必须经历的。DAD提出了一种退火算法来解决这个问题,在训练过程中引入一个概率值参数εi ,每次以εi的概率选取真实的token作为输入, 1-εi的概率选取自己的prediction作为输入。逐渐降低εi,最终模型全都利用自己的prediction作为下一步的输入,和测试过程一致。 4.4、Sampled Softmax 问题描述:Seq2Seq模型的代价函数的loss便是sampled_softmax_loss。为什么不是softmax_loss呢?我们都知道对于Seq2Seq模型来说,输入和输出序列的class便是词汇表的大小,而对于训练集来说,输入和输出的词汇表的大小是比较大的。为了减少计算每个词的softmax的时候的资源压力,通常会减少词汇表的大小,但是便会带来另外一个问题,由于词汇表的词量的减少,语句的Embeding的id表示时容易大频率的出现未登录词‘UNK’。于是,希望寻找到一个能使seq2seq模型使用较大词汇表,但又不怎么影响计算效率的解决办法。 trick:论文《On Using Very Large Target Vocabulary for Neural Machine Translation》论文中提出了计算词汇表的softmax的时候,并不采用全部的词汇表中的词,而是进行一定手段的sampled的采样,从而近似的表示词汇表的loss输出。sampled采样需要定义好候选分布Q。即按照什么分布去采样。 4.5、seq2seq为什么需要bucket 问题描述:在处理序列问题时,每个batch中的句子的长度其实是不一的,通常做法是取batch中语句最长的length作为序列的固定的长度,不足的补PAD。如果batch里面存在一个非常长的句子,那么其他的句子的都需要按照这个作为输入序列的长度,训练模型时这将造成不必要的计算浪费。 trick:相当于对序列的长度做一个分段,切分成多个固定长度的输入序列,比如说小于100为一个bucket,大于100小于150为另一个bucket…。每一个bucket都是一个固定的computation graph。这样一来,对于模型输入序列的固定长度将不再单一,从一定程度上减少了计算资源的浪费。 4.6、连续生成重复内容的问题 问题描述:在Seq2Seq的解码阶段,生成序列是很可能会生成连续的重复词。 trick:论文《Get To The Point: Summarization with Pointer-Generator Networks》使用Pointer-Generator Networks)中使用Coverage mechanism来缓解重复词的问题,模型中维护一个Coverage向量,这个向量是过去所有预测步计算的attention分布的累加和,表示着该模型已经关注过原文的哪些词,并且让这个coverage向量影响当前步的attention计算。其中ci表示之前时刻的预测的attention分布和。 此外,该论文中添加了一个coverage loss用于惩罚对重复的attention。ai表示当前时刻的attention,ci表示之前时刻的预测计算的attention分布的累加和。 扩展:苏剑林之前对生成重复内容问题做了一个比较深入的剖析,请参考:https://kexue.fm/archives/8128 4.7、seq2seq中“根本停不下来”的问题 问题描述:在Seq2Seq的解码过程中,我们是逐个token地递归生成的,直到出现 trick:论文《Consistency of a Recurrent Language Model With Respect to Incomplete Decoding》比较系统地讨论了这个现象,并提出了一些对策。 主要的解决思路就是如何在解码的时候生成 1)对于原生的随机解码采用加入有界隐向量的方式; 2)对于top-k随机解码和Nucleus随机解码采用主动添加 3)对于确定性搜索采用自截断设计:想办法让 参考文献: [1]https://arxiv.org/pdf/1406.1078.pdf [2]https://arxiv.org/pdf/1409.0473.pdf [3]https://arxiv.org/abs/1602.06023.pdf [4]https://arxiv.org/pdf/1603.06393.pdf [5]https://arxiv.org/pdf/1603.08148.pdf [6]https://arxiv.org/abs/1506.03099.pdf [7] https://arxiv.org/abs/1606.02960.pdf [8]https://arxiv.org/abs/1412.2007.pdf [9]https://arxiv.org/pdf/1704.04368.pdf [10]https://arxiv.org/abs/2002.02492.pdf [11]https://blog.csdn.net/u014732537/article/details/81206267 [12]https://kexue.fm/archives/7500 [13]https://blog.csdn.net/thormas1996/article/details/81081772 [14]https://kexue.fm/archives/8128 [15]https://zhuanlan.zhihu.com/p/69159062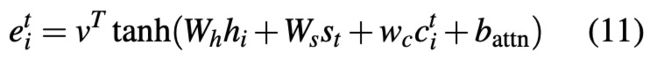

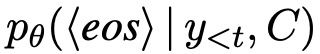 有正的下界,而且这个下界随着t的增大而增大,最终逐渐趋于1。
有正的下界,而且这个下界随着t的增大而增大,最终逐渐趋于1。