从零开始语音识别(2)--- 语音信号处理
- 语音信号特征提取流程

- 预加重:preemphasis
 反应到代码其实就是1行:
反应到代码其实就是1行:
np.append(signal[0], signal[1:] - coeff * signal[:-1])
- 加窗分帧

为什么要加上帧移?
加窗的代价是一帧信号两端的部分被削弱了,没有像中央的部分那样得到重视。弥补的办法是,帧不要背靠背地截取,而是相互重叠一部分。相邻两帧的起始位置的时间差叫做帧移,常见的取法是取为帧长的一半,或者固定取为 10 毫秒

def enframe(signal, frame_len=frame_len, frame_shift=frame_shift, win=np.hamming(frame_len)):
"""Enframe with Hamming widow function.
:param signal: The signal be enframed
:param win: window function, default Hamming
:returns: the enframed signal, num_frames by frame_len array
"""
num_samples = signal.size
// num_frames表示总共有多少个帧
// 帧长frame_len表示一帧包含多少个点
// 帧移frame_shift表示一个帧移中包含多少个点
num_frames = np.floor((num_samples - frame_len) / frame_shift) + 1
frames = np.zeros((int(num_frames), frame_len))
for i in range(int(num_frames)):
frames[i, :] = signal[i * frame_shift:i * frame_shift + frame_len]
frames[i, :] = frames[i, :] * win
return frames
为什么不使用矩形窗:两个信号时域相乘等于频域卷积,矩形窗的频域的主瓣窄,旁瓣宽,会导致频率泄露。
3.离散傅里叶变换
DFT具有对称性,在N点DFT之后,只需要保证前N/2+1个点即可
def get_spectrum(frames, fft_len=fft_len):
"""Get spectrum using fft
:param frames: the enframed signal, num_frames by frame_len array
:param fft_len: FFT length, default 512
:returns: spectrum, a num_frames by fft_len/2+1 array (real)
"""
cFFT = np.fft.fft(frames, n=fft_len)
valid_len = int(fft_len / 2) + 1
spectrum = np.abs(cFFT[:, 0:valid_len])
return spectrum
4.梅尔滤波器组生成fbank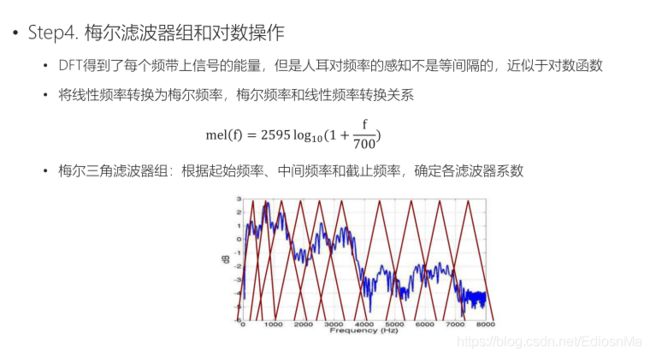

def mel_filter(frame_pow, fs, n_filter, nfft):
"""
mel 滤波器系数计算
:param frame_pow: 分帧信号功率谱
:param fs: 采样率 hz
:param n_filter: 滤波器个数
:param nfft: fft点数
:return: 分帧信号功率谱mel滤波后的值的对数值
mel = 2595 * log10(1 + f/700) # 频率到mel值映射
f = 700 * (10^(m/2595) - 1 # mel值到频率映射
上述过程本质上是对频率f对数化
"""
mel_min = 0 # 最低mel值
mel_max = 2595 * np.log10(1 + fs / 2.0 / 700) # 最高mel值,最大信号频率为 fs/2
mel_points = np.linspace(mel_min, mel_max, n_filter + 2) # n_filter个mel值均匀分布与最低与最高mel值之间
hz_points = 700 * (10 ** (mel_points / 2595.0) - 1) # mel值对应回频率点,频率间隔指数化
filter_edge = np.floor(hz_points * (nfft + 1) / fs) # 对应到fft的点数比例上
# 求mel滤波器系数
fbank = np.zeros((n_filter, int(nfft / 2 + 1)))
for m in range(1, 1 + n_filter):
f_left = int(filter_edge[m - 1]) # 左边界点
f_center = int(filter_edge[m]) # 中心点
f_right = int(filter_edge[m + 1]) # 右边界点
for k in range(f_left, f_center):
fbank[m - 1, k] = (k - f_left) / (f_center - f_left)
for k in range(f_center, f_right):
fbank[m - 1, k] = (f_right - k) / (f_right - f_center)
# mel 滤波
# [num_frame, nfft/2 + 1] * [nfft/2 + 1, n_filter] = [num_frame, n_filter]
filter_banks = np.dot(frame_pow, fbank.T)
filter_banks = np.where(filter_banks == 0, np.finfo(float).eps, filter_banks)
# 取对数
filter_banks = 20 * np.log10(filter_banks) # dB
return filter_banks
- mfcc
前面提取到的FBank特征,往往是高度相关的。因此可以继续用DCT(离散余弦变换)变换,将这些相关的滤波器组系数进行压缩。对于ASR来说,通常取2~13维,扔掉的信息里面包含滤波器组系数快速变化部分。
num_ceps = 12
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1:(num_ceps+1)]
plot_spectrogram(mfcc.T, 'MFCC Coefficients')
DCT是线性变换,会丢失语音信号中原本的一些高度非线性成分。在深度学习之前,受限于算法,mfcc配GMMs-HMMs是ASR的主流做法。当深度学习方法出来之后,由于神经网络对高度相关的信息不敏感,mfcc不是最优选择,经过实际验证,其在神经网络中的表现也明显不如fbank。