详解目标检测算法坐标回归方式-anchor-based方法
本文讨论或者复习一下目前最流行的深度学习目标检测算法的坐标回归方式,注意,本文讨论的是anchor-based,至于anchor-free的方法,每一种anchor-free各自对应一种后处理,咱们这边就不详细讨论了。
一、常用的faster rcnn、retinanet、ssd等cls+reg head类型。
总体来说,根据anchor来提供初始坐标,然后利用anchor的初始值去回归线性变化时的参数(偏移值和尺寸值),最后将这些参数配合固定anchors成为具体的坐标,细节如下:
1、回顾anchor是怎么在这些网络中运作生成的。
整体流程简单,如下代码(细节下文详细给出):
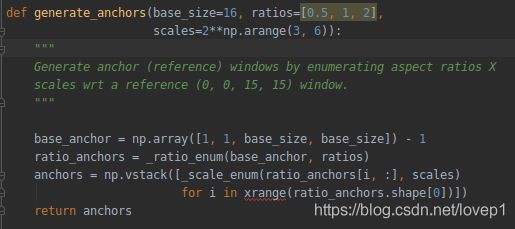
anchors的生成需要参数如下:base_size-用来生成基础anchors, rations-长宽比参数, scales-面积比参数,基于以上3组数据,在每一层的feature-map上生成密密麻麻的anchors。
首先,利用base_anchor的值生成基础anchor,我们通常设定为16,则直接回生成一个[0,0, 15, 15]的矩形。
然后,将上述anchor进行坐标变化,变换成中心点与宽高的形式,也就是[xmin,ymin, xmax,ymax]转换成[w,h,x_center,y_center],则[0,0,15,15]变成[16,16,7.5,7.5 ]。

进一步,此时,利用w和h对矩形计算面积,此时的面积为base_anchor的面积,利用这个面积除以rations,则可以得到不同的面积数组,如size=16*16时,rations=[0.5, 1, 2],则面积的list为[512,256,128],然后将面积的list进行开平方,得到ws,将ws*rations得到hs,则3个ws有3个hs,则每个中心点有[x_center,y_center,ws1-3,hs1-3]个anchors。比如[512,256,128]开平方后ws得到[23,16,11],经过rations变化hs得到[12,16,22],则anchors为[-3.5,2,18.5,13],[0,0,15,15],[2.5,-3,12.5,18],从下面的代码我们可以看到,所有的中心点都是从[7.5,7.5]开始计算的,


生成完成后,得到如下图所示(图片来源:https://blog.csdn.net/qq_26974871/article/details/81251851):

最后,再利用scale参数,将上一步得到的所有anchors的w和h乘以scales得到新的ws和hs,上一步得到的3个anchors每一个都按照scale扩展,则变成了9个anchors。举例如下:
如上一步得到[-3.5,2,18.5,13],[0,0,15,15],[2.5,-3,12.5,18]之后,则假定针对坐标[-3.5,2,18.5,13],whxy格式为[23,12,7.5,7.5],乘以scale=[8,16,32],得到[184,96,7.5,7.5],[368,192, 7.5,7.5],[736,384, 7.5, 7.5],再将其转化为xxyy格式,得到[-84,-40,99,55],[-176,-88, 191,103],[-360,-184, 375, 199],完整anchors形状如下图:

如上所示,针对目标检测网络如faster-rcnn、retinanet、ssd等,最后的featuremap上每一个特征点都会按照流程生成上面的anchor集合(这是原始坐标-绝对坐标哈,不是resize的坐标),因此,只要超参数配置得当,这样的机制可以覆盖住任意大小的目标,尤其是fpn结构时,但是同样也会带来庞大的计算量(retinanet曾经号称历史最强anchors数)。
2、怎么利用anchors进行回归
如上文所述,得到每一个特征点的anchors后,此时,我们开始分析目标检测网络预测时如何配合这些anchor进行真正的坐标回归。我们注意到,每一个特征点都会对应9个anchors,然后网络在预测时,实际上预测的是针对这9个anchors的坐标的偏移和变化,也就是说,网络预测的不是真正的坐标,很多同学可能会以为是预测坐标,细节如下:
首先,从faster-rcnn的paper中拿到基本的线性回归的公式,如下:

我们假定anchors的值为xa,ya,wa,ha,真实坐标为x,y,w,h,网络计算最终坐标值为x*,y*,w*,h*,我们可以看到上式,经过上式变换后,将ground-trouth的坐标值变成了tx,ty,tw,th的值。也就是说,我们只要在算法中预测tx*,ty*,tw*,th*就行了,经过同样的变换,只要tx与tx*、ty与ty*、tw与tw*、th与th*一致,则x与x*、y与y*,w与w*、h与h*就是一致的。那么算法到底预测的是什么?是坐标吗?从上式可以看出,算法压根就不会理解什么坐标,他只会从数据中分析,上式中x与y我们称之为平移的ground truth,w和h称之为缩放的ground truth,算法其实就是按照上述公式预测tx*,ty*,tw*,th*,然后经过一系列线性变换公式(式2)将anchors进行平移和缩放就变成了预测真实坐标,在训练时则与标注gt进行iou计算,在测试时,直接后处理输出计算坐标,为什么坐标回归网络叫做回归,就是使用了线性回归的方式。
不过注意的是,有的算法实现方式不一样,在训练时,有的code直接学习tx*,将标注的坐标转化为tx,计算tx*与tx的差异,有的code将模型预测的tx*转化为x*,直接计算x与x*的差异,但是究其原理,都是一样的。
得到坐标计算的差异后,我们进一步的可以引出anchor-based算法的损失函数,即:
Loss = locc_cls + l_reg
其中l_reg最简单做法就是预测均方差损失等等。
综上,这个便是最常见的cls_head+reg_head的坐标预测方法
二、常用的yolo算法的yolo_head的坐标预测方式
1、anchor在yolo_head中是如何产生的
anchor在yolo中并不是faster rcnn类似的产生的,yolo中的anchors值是直接人为指定的,也就是说,不需要设置什么scale和rations,yolo会直接利用设定好的anchos数组,按照其独有的fpn结构3层featuremap上每层使用3个固定的anchors值作为本层featuremap的anchors。例如在coco数据集上,固定的anchors数组为10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326(yolov3-416的模型)。
如何得到这些anchors呢,使用kmeans算法来对数据集进行聚类,我们详细说明yolo的kmeans算法:
1、提取数据集中所有的bbox,将所有类别的坐标全部提取出来放在一起
2、得到所有数据的w和h数据,注意,在不同版本的yolo算法中,计算使用的w和h有的是使用原始数据,有的是使用算法输入尺寸的数据,也就是将w和h按比例缩小到输入尺寸,最好是使用输入尺寸。
3、初始化9个anchors,随机选取k个w和h的值作为初始值(注意,yolo系列的算法一般都是使用9个anchors,但是算法做改进的同时,增加召回率,增加anchors个数也是可行的,但是后续网络结构中需要对应增加模型输出)
4、计算每一个bbox和每个anchor box的的iou值,注意,普通的kmeans方法是使用欧氏距离来计算差异的,但是在yolo中,使用的是iou来作为标准,且最终的差异值用1-iou来计算(iou越大越可以表示是一个簇)
5、通过第4步得到每一个bbox到anchors box之间的距离,将根据当前bbox距离所有anchors中最小的值分配然后将这个box分配给那个anchors,然后再求这些bbox的w和h的均值作为新的anchor尺寸
6、重复第4步和第5步,直至发现更新anchors值后bbox的分类簇不会发生变化,即完成kmeans聚类。
详细代码最好参见yolov5的自动聚类算法,那个确实做的比较好。
2、anchors是如何在算法中起效的
从第一步,我们得到基于当前数据集的最佳anchors超参数,我们依据大尺寸的featuremap检测小目标、深层feature_map检测大目标的原则,将anchors均匀分配至后处理计算中,即前文说的3层featuremap每一层各使用固定的3个anchors。
预测方式:yolo的预测与其他方法的方式有差异,我们直接看原文的图:

如上图所示, 首先,yolo预测的是tx、ty,tw、th,其中bx、by、bw、bh即bbox的在feature-map上的中心点坐标和宽高信息,cx和cy代表着当前grid的值,其实也就是各个grid左上角的坐标,pw、ph则就是anchors相对于特征图的宽和高,真正的坐标转化公式如下图所示:
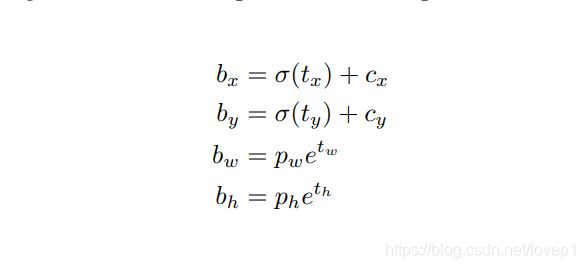
简单介绍一下如何操作,算法预测得到tx、ty,tw、th后,针对每一个grid,都会存在3组tx、ty,tw、th对应anchors来得到变换坐标,将tx进行sigmod后,得到中心点的坐标偏移,然后加上当前grid的cx偏移,则得到中心点坐标cx,同理得到cy。tw和th则使用exp配合anchor的w和h得到,具体代码实现可以看到的我github实现:

综上,便是yolo系列的算法利用anchors进行坐标回归的方式。
三、常用的anchor-free算法举例(不讨论原理)
1、cornernet/cornernet-lite:上下角点代表目标,具体方式详见我以前的文章
2、centernet-object as points:中心点加上宽高代表目标
3、fcoenet:目标像素点和距离边界的4个值(4维向量)
4、centernet-triples:上下角点+中心点代表目标
5、extremenet:上下左右4个极值点
6、reppoints:一组角点代表目标,更接近于可变性卷积。
7、............还有很多anchor free的算法,精度很多都达到了0.49在coco上,此处不举例了。
欢迎同学对我上述写的文章不正确的地方进行提出和指正。