Faster-RCNN深度剖析+源码debug级讲解系列(一)RPN网络和Bbox回归
前言
因为Faster-RCNN是一个非常经典的two-stage网络了,所以本来是没打算做这期内容的,但是博主觉得一方面这个网络通过各种改造仍然具备在很多竞赛中拿到top成绩的能力,另一方面这个网络的细节很多,可能非常容易被忽视。所以博主打算带大家一起剖析下Faster-RCNN的源码。当然非常基础的部分比如backbone网络构建这些,我就省略了,只重点去看一下RPN网络和分类网络两次调整BoundingBox的细节,ROI Pooling和NMS的细节等容易被忽略的地方。这个系列的第一期我们先一起来看下RPN网络和Region Proposal的生成和处理。延续整个细节的特色,我们仍然去debug每一行源码。
一.源码debug准备
- 代码的版本
这次debug采用的版本是我很喜欢的一个up主复现的版本,我觉得这个版本较为简单上手:
传送门 - 数据集
使用的数据集是voc2007数据集。数据集的准备方法如下:
1.训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
2.训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
3.在voc2frcnn.py里调整train_percent参数,来划分训练和验证集的比例。利用voc2frcnn.py文件生成对应的txt。
4.运行根目录下的voc_annotation.py,运行前需要将classes改成你自己的classes。注意不要使用中文标签,文件夹中不要有空格!
5.执行完以上的内容,会生成2007_train.txt,每一行对应其图片位置及其真实框的位置。
6.在model_data下面创建voc_classes.txt,文档中输入需要分的类,每个类占一行。
7.准备完毕,执行train.py。
C:\Users\adamc\AppData\Local\conda\conda\envs\fasterrcnn\python.exe D:/pyprojects/cv-code-debug/faster-rcnn-pytorch-master/train.py
Loading weights into state dict...
Finished!
Epoch 1/50: 0%| | 1/5958 [02:50<282:33:53, 170.76s/it, lr=0.0001, roi_cls=0.316, roi_loc=0.645, rpn_cls=0.0935, rpn_loc=0.0445, total=1.1]
看到训练开始了,说明流程跑通,可以进行debug了。
二.RPN源码剖析
我们重点来看rpn.py这个文件,RegionProposalNetwork这个类。
class RegionProposalNetwork(nn.Module):
def __init__(
self, in_channels=512, mid_channels=512, ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32], feat_stride=16,
mode = "training",
):
super(RegionProposalNetwork, self).__init__()
self.feat_stride = feat_stride
self.proposal_layer = ProposalCreator(mode)
#-----------------------------------------#
# 生成基础先验框,shape为[9, 4]
#-----------------------------------------#
self.anchor_base = generate_anchor_base(anchor_scales=anchor_scales, ratios=ratios)
n_anchor = self.anchor_base.shape[0]
#-----------------------------------------#
# 先进行一个3x3的卷积,可理解为特征整合
#-----------------------------------------#
self.conv1 = nn.Conv2d(in_channels, mid_channels, 3, 1, 1)
#-----------------------------------------#
# 分类预测先验框内部是否包含物体
#-----------------------------------------#
self.score = nn.Conv2d(mid_channels, n_anchor * 2, 1, 1, 0)
#-----------------------------------------#
# 回归预测对先验框进行调整
#-----------------------------------------#
self.loc = nn.Conv2d(mid_channels, n_anchor * 4, 1, 1, 0)
#--------------------------------------#
# 对FPN的网络部分进行权值初始化
#--------------------------------------#
normal_init(self.conv1, 0, 0.01)
normal_init(self.score, 0, 0.01)
normal_init(self.loc, 0, 0.01)
def forward(self, x, img_size, scale=1.):
n, _, h, w = x.shape
#-----------------------------------------#
# 先进行一个3x3的卷积,可理解为特征整合
#-----------------------------------------#
x = F.relu(self.conv1(x))
#-----------------------------------------#
# 回归预测对先验框进行调整
#-----------------------------------------#
rpn_locs = self.loc(x)
rpn_locs = rpn_locs.permute(0, 2, 3, 1).contiguous().view(n, -1, 4)
#-----------------------------------------#
# 分类预测先验框内部是否包含物体
#-----------------------------------------#
rpn_scores = self.score(x)
rpn_scores = rpn_scores.permute(0, 2, 3, 1).contiguous().view(n, -1, 2)
#--------------------------------------------------------------------------------------#
# 进行softmax概率计算,每个先验框只有两个判别结果
# 内部包含物体或者内部不包含物体,rpn_softmax_scores[:, :, 1]的内容为包含物体的概率
#--------------------------------------------------------------------------------------#
rpn_softmax_scores = F.softmax(rpn_scores, dim=-1)
rpn_fg_scores = rpn_softmax_scores[:, :, 1].contiguous()
rpn_fg_scores = rpn_fg_scores.view(n, -1)
#------------------------------------------------------------------------------------------------#
# 生成先验框,此时获得的anchor是布满网格点的,当输入图片为600,600,3的时候,shape为(12996, 4)
#------------------------------------------------------------------------------------------------#
anchor = _enumerate_shifted_anchor(np.array(self.anchor_base), self.feat_stride, h, w)
rois = list()
roi_indices = list()
for i in range(n):
roi = self.proposal_layer(rpn_locs[i], rpn_fg_scores[i], anchor, img_size, scale=scale)
batch_index = i * torch.ones((len(roi),))
rois.append(roi)
roi_indices.append(batch_index)
rois = torch.cat(rois, dim=0)
roi_indices = torch.cat(roi_indices, dim=0)
return rpn_locs, rpn_scores, rois, roi_indices, anchor
首先构建了ProposalCreator,这部分我们在调用的时候再分析。
然后代码通过调用generate_anchor_base来生成了阈值的anchor。
def generate_anchor_base(base_size=16, ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32]):
anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4), dtype=np.float32)
for i in range(len(ratios)):
for j in range(len(anchor_scales)):
h = base_size * anchor_scales[j] * np.sqrt(ratios[i])
w = base_size * anchor_scales[j] * np.sqrt(1. / ratios[i])
index = i * len(anchor_scales) + j
anchor_base[index, 0] = - h / 2.
anchor_base[index, 1] = - w / 2.
anchor_base[index, 2] = h / 2.
anchor_base[index, 3] = w / 2.
return anchor_base
anchor_base的shape是(9,4),代表着九个anchor。在ratios和anchor_scales的两层循环中,去计算anchor的坐标。base_size代表基准大小,默认是16(对应下采样16倍)。anchor_scales调节框的大小,分别放大8,16,32倍;ratios调节框的胖瘦,分别对anchor的高进行0.5,1,2的开方倍放缩。同时对应的宽进行相应的调整,保证同一个scale下的3个不同宽高比的面积是不变的。我们打印出来这九个anchor的位置坐标,这些坐标相对原图尺寸的:
[[ -45.254833 -90.50967 45.254833 90.50967 ]
[ -90.50967 -181.01933 90.50967 181.01933 ]
[-181.01933 -362.03867 181.01933 362.03867 ]
[ -64. -64. 64. 64. ]
[-128. -128. 128. 128. ]
[-256. -256. 256. 256. ]
[ -90.50967 -45.254833 90.50967 45.254833]
[-181.01933 -90.50967 181.01933 90.50967 ]
[-362.03867 -181.01933 362.03867 181.01933 ]]
后面会调用_enumerate_shifted_anchor函数,把这些anchor放在原图上:
def _enumerate_shifted_anchor(anchor_base, feat_stride, height, width):
# 计算网格中心点
shift_x = np.arange(0, width * feat_stride, feat_stride)
shift_y = np.arange(0, height * feat_stride, feat_stride)
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shift = np.stack((shift_x.ravel(),shift_y.ravel(),
shift_x.ravel(),shift_y.ravel(),), axis=1)
# 每个网格点上的9个先验框
A = anchor_base.shape[0]
K = shift.shape[0]
anchor = anchor_base.reshape((1, A, 4)) + \
shift.reshape((K, 1, 4))
# 所有的先验框
anchor = anchor.reshape((K * A, 4)).astype(np.float32)
return anchor
这里的计算网格中心点的代码,很多anchor based的框架都会使用。这里很明显是在原图的尺寸上计算了每一组框中心点的坐标,再加上框的坐标偏移量,得到的就是每个框在原图上的真实坐标了。而且这个坐标是通过左上角点和右下角的点表示的(xmin,ymin,xmax,ymax)。
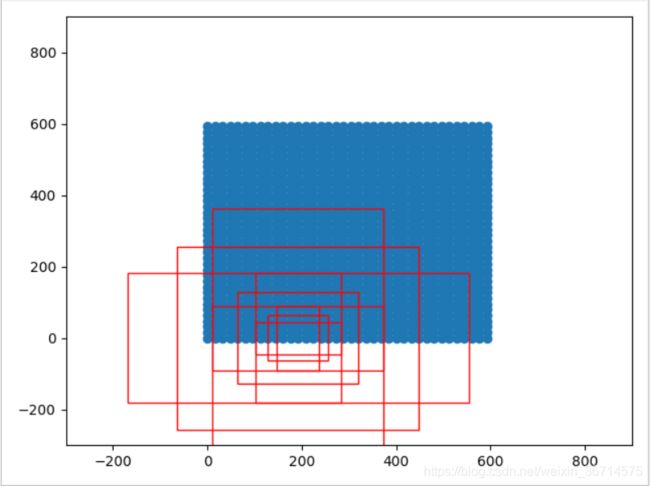
随机选一组框画出来就如下图所示:
self.conv1 = nn.Conv2d(in_channels, mid_channels, 3, 1, 1)
#-----------------------------------------#
# 分类预测先验框内部是否包含物体
#-----------------------------------------#
self.score = nn.Conv2d(mid_channels, n_anchor * 2, 1, 1, 0)
#-----------------------------------------#
# 回归预测对先验框进行调整
#-----------------------------------------#
self.loc = nn.Conv2d(mid_channels, n_anchor * 4, 1, 1, 0)
这里是RPN网络的构建代码,一个3x3的卷积对backbone出来的特征图进行进一步的特征提取,两个1x1的卷积,一个的channel数量是9x2代表9个anchor是否包含物体的预测,另一个channel是9x4代表每个anchor的坐标调整。
下面我们来剖析一下forward()函数,看看RPN的前向传播:
n, _, h, w = x.shape
#-----------------------------------------#
# 先进行一个3x3的卷积,可理解为特征整合
#-----------------------------------------#
x = F.relu(self.conv1(x))
#-----------------------------------------#
# 回归预测对先验框进行调整
#-----------------------------------------#
rpn_locs = self.loc(x)
rpn_locs = rpn_locs.permute(0, 2, 3, 1).contiguous().view(n, -1, 4)
#-----------------------------------------#
# 分类预测先验框内部是否包含物体
#-----------------------------------------#
rpn_scores = self.score(x)
rpn_scores = rpn_scores.permute(0, 2, 3, 1).contiguous().view(n, -1, 2)
rpn_softmax_scores = F.softmax(rpn_scores, dim=-1)
rpn_fg_scores = rpn_softmax_scores[:, :, 1].contiguous()
rpn_fg_scores = rpn_fg_scores.view(n, -1)
对3x3的特征提取卷积进行Relu激活,然后分别送入两个1x1卷积。然后把channle维度放到最后一维,调整shape分别为(B,A,4)和(B,A,2)来方便后续进行softmax。A代表anchor的总数,如果输入是800*800,那么这一步的A为50*50*9=22500个anchor。
最后rpn_fg_scores输出softmax结果,并取出包含物体的概率,最后rpn_fg_scores的shape是(B,A)。
rois = list()
roi_indices = list()
for i in range(n):
roi = self.proposal_layer(rpn_locs[i], rpn_fg_scores[i], anchor, img_size, scale=scale)
batch_index = i * torch.ones((len(roi),))
rois.append(roi)
roi_indices.append(batch_index)
rois = torch.cat(rois, dim=0)
roi_indices = torch.cat(roi_indices, dim=0)
return rpn_locs, rpn_scores, rois, roi_indices, anchor
这部分开始在B这个维度上进行循环,通过proposal_layer来进行bbox的坐标调整。proposal_layer是实例化ProposalCreator这个类。下面我们分析这个类:
class ProposalCreator():
def __init__(self, mode, nms_thresh=0.7,
n_train_pre_nms=12000,
n_train_post_nms=600,
n_test_pre_nms=3000,
n_test_post_nms=300,
min_size=16):
self.mode = mode
self.nms_thresh = nms_thresh
self.n_train_pre_nms = n_train_pre_nms
self.n_train_post_nms = n_train_post_nms
self.n_test_pre_nms = n_test_pre_nms
self.n_test_post_nms = n_test_post_nms
self.min_size = min_size
def __call__(self, loc, score,
anchor, img_size, scale=1.):
if self.mode == "training":
n_pre_nms = self.n_train_pre_nms
n_post_nms = self.n_train_post_nms
else:
n_pre_nms = self.n_test_pre_nms
n_post_nms = self.n_test_post_nms
anchor = torch.from_numpy(anchor)
if loc.is_cuda:
anchor = anchor.cuda()
#-----------------------------------#
# 将RPN网络预测结果转化成建议框
#-----------------------------------#
roi = loc2bbox(anchor, loc)
#-----------------------------------#
# 防止建议框超出图像边缘
#-----------------------------------#
roi[:, [0, 2]] = torch.clamp(roi[:, [0, 2]], min = 0, max = img_size[1])
roi[:, [1, 3]] = torch.clamp(roi[:, [1, 3]], min = 0, max = img_size[0])
#-----------------------------------#
# 建议框的宽高的最小值不可以小于16
#-----------------------------------#
min_size = self.min_size * scale
keep = torch.where(((roi[:, 2] - roi[:, 0]) >= min_size) & ((roi[:, 3] - roi[:, 1]) >= min_size))[0]
roi = roi[keep, :]
score = score[keep]
#-----------------------------------#
# 根据得分进行排序,取出建议框
#-----------------------------------#
order = torch.argsort(score, descending=True)
if n_pre_nms > 0:
order = order[:n_pre_nms]
roi = roi[order, :]
score = score[order]
#-----------------------------------#
# 对建议框进行非极大抑制
#-----------------------------------#
keep = nms(roi, score, self.nms_thresh)
keep = keep[:n_post_nms]
roi = roi[keep]
return roi
主要通过call函数执行回归:
roi = loc2bbox(anchor, loc)
这里调用了loc2box函数。传入的anchor我们知道是在原图的具体坐标(xmin,ymin,xmax,ymax)。
def loc2bbox(src_bbox, loc):
if src_bbox.size()[0] == 0:
return torch.zeros((0, 4), dtype=loc.dtype)
src_width = torch.unsqueeze(src_bbox[:, 2] - src_bbox[:, 0], -1)
src_height = torch.unsqueeze(src_bbox[:, 3] - src_bbox[:, 1], -1)
src_ctr_x = torch.unsqueeze(src_bbox[:, 0], -1) + 0.5 * src_width
src_ctr_y = torch.unsqueeze(src_bbox[:, 1], -1) + 0.5 * src_height
dx = loc[:, 0::4]
dy = loc[:, 1::4]
dw = loc[:, 2::4]
dh = loc[:, 3::4]
ctr_x = dx * src_width + src_ctr_x
ctr_y = dy * src_height + src_ctr_y
w = torch.exp(dw) * src_width
h = torch.exp(dh) * src_height
dst_bbox = torch.zeros_like(loc)
dst_bbox[:, 0::4] = ctr_x - 0.5 * w
dst_bbox[:, 1::4] = ctr_y - 0.5 * h
dst_bbox[:, 2::4] = ctr_x + 0.5 * w
dst_bbox[:, 3::4] = ctr_y + 0.5 * h
return dst_bbox
首先对于x,y,w,h的计算全部都是在原图尺寸上进行的,并没有在grid的层面上进行。
src_width = torch.unsqueeze(src_bbox[:, 2] - src_bbox[:, 0], -1)
src_height = torch.unsqueeze(src_bbox[:, 3] - src_bbox[:, 1], -1)
src_ctr_x = torch.unsqueeze(src_bbox[:, 0], -1) + 0.5 * src_width
src_ctr_y = torch.unsqueeze(src_bbox[:, 1], -1) + 0.5 * src_height
根据anchor的坐标计算出宽和高,以及中心点的(x_center,y_center)坐标。
dx = loc[:, 0::4]
dy = loc[:, 1::4]
dw = loc[:, 2::4]
dh = loc[:, 3::4]
根据预测值取出x,y,w,h的调整偏移量。
ctr_x = dx * src_width + src_ctr_x
ctr_y = dy * src_height + src_ctr_y
w = torch.exp(dw) * src_width
h = torch.exp(dh) * src_height
在原始尺寸进行坐标偏移。偏移量都是以anchor的宽高为基准的相对量。
dst_bbox[:, 0::4] = ctr_x - 0.5 * w
dst_bbox[:, 1::4] = ctr_y - 0.5 * h
dst_bbox[:, 2::4] = ctr_x + 0.5 * w
dst_bbox[:, 3::4] = ctr_y + 0.5 * h
调整完之后仍然将其重新转化为(xmin,ymin,xmax,ymax)的左上右下角的表示方法。
最后返回值shape仍然是(A,4),对于800*800原始图片,仍然是(22500,4)。此时已经是在原始图像上基于RPN调整后的bbox了。
roi[:, [0, 2]] = torch.clamp(roi[:, [0, 2]], min = 0, max = img_size[1])
roi[:, [1, 3]] = torch.clamp(roi[:, [1, 3]], min = 0, max = img_size[0])
对于超出原图的尺寸进行裁剪,对于裁剪和NMS这些判断一般都是在原图尺寸上进行的,在之前分析的yolov3源码中,可以看到同样的操作。
min_size = self.min_size * scale
keep = torch.where(((roi[:, 2] - roi[:, 0]) >= min_size) & ((roi[:, 3] - roi[:, 1]) >= min_size))[0]
roi = roi[keep, :]
score = score[keep]
min_size默认是16,这里是过滤掉宽或高小于16的框。假设剩下M个框,则roi的shape是(M,4),score的shape是(M)。
order = torch.argsort(score, descending=True)
if n_pre_nms > 0:
order = order[:n_pre_nms]
roi = roi[order, :]
score = score[order]
按照有object的置信度对所有框进行排序,取出前n_pres_nms个,默认这个参数是12000个,实际使用时可以调节。
keep = nms(roi, score, self.nms_thresh)
keep = keep[:n_post_nms]
roi = roi[keep]
return roi
然后对于这12000个框进行了nms处理,再通过n_post_nms控制最终的bbox输出。在训练时,这个默认值为600。
rois = list()
roi_indices = list()
for i in range(n):
roi = self.proposal_layer(rpn_locs[i], rpn_fg_scores[i], anchor, img_size, scale=scale)
batch_index = i * torch.ones((len(roi),))
rois.append(roi)
roi_indices.append(batch_index)
rois = torch.cat(rois, dim=0)
roi_indices = torch.cat(roi_indices, dim=0)
对B进行循环,求出每次的bbox回归,并进行排序和截取。最终的结果通过torch.cat()进行合并,并且标记了每个batch的index。注意直到这里仍然是对应的原图尺寸,未进行任何的比例缩放。
以上就是整个RPN部分的源码,以及第一次Region Proposal是如何调整坐标的。