模型精度再被提升,统一跨任务小样本学习算法 UPT 给出解法!
近日,阿里云机器学习平台PAI与华东师范大学高明教授团队、达摩院机器智能技术NLP团队合作在自然语言处理顶级会议EMNLP2022上发表统一多NLP任务的预训练增强小样本学习算法UPT(Unified Prompt Tuning)。这是一种面向多种NLP任务的小样本学习算法,致力于利用多任务学习和预训练增强技术,在仅需要标注极少训练数据的情况下,提升大规模预训练语言模型在多种场景下的模型精度。
论文:
Jianing Wang, Chengyu Wang, Fuli Luo, Chuanqi Tan, Minghui Qiu, Fei Yang, Qiuhui Shi, Songfang Huang, Ming Gao. Towards Unified Prompt Tuning for Few-shot Text Classification. EMNLP (Findings) 2022
背景
随着预训练语言模型的规模逐步地扩大,千亿、万亿甚至更大规模的预训练语言模型的分布式训练和优化工作不断涌现。预训练语言模型规模的扩大,带来这一类模型在自然语言理解等相关任务效果的不断提升。然而,这些模型的参数空间比较大,如果在下游任务上直接对这些模型进行微调,为了达到较好的模型泛化性,需要较多的训练数据。在实际业务场景中,特别是垂直领域、特定行业中,训练样本数量不足的问题广泛存在,极大地影响这些模型在下游任务的准确度。基于提示微调(Prompt Tuning)的小样本学习技术能充分利用预训练过程中模型获得的知识,在给定小训练集上训练得到精度较高的模型。然而,在小样本学习场景下,训练数据的有限性仍然对模型的准确度造成一定的制约。因此,如果可以在小样本学习阶段,有效利用其它跨任务的数据集,可以进一步提升模型的精度。
算法架构
跨任务小样本学习算法UPT(Unified Prompt Tuning)是对已有小样本学习算法的学习机理进行的一种深度扩展。UPT是一种统一的学习范式,可以将各种下游任务和预训练任务统一成POV(Prompt-Options-Verbalizer)的形式,使得模型可以学习利用Prompt解决各种NLP任务的通用方法。在我们的工作中,UPT的任务构造形式如下所示:
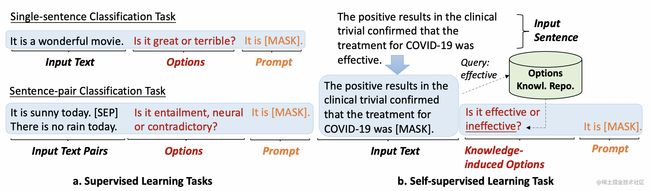
由此可见,无论是单句分类任务,还有双句匹配任务,亦或是预训练阶段的自监督学习任务,UPT可以将他们转化成一种统一的范式进行学习。这种学习方式兼顾了经典的小样本学习算法的优势,又在学习过程中引入了“元学习”(Meta Learning)的思想,大大提升了模型对下游任务的泛化性,缓解了其在小样本学习阶段遇到的过拟合问题。当我们训练得到这一Meta Learner之后,我们可以复用先前的算法,对Meta Learner进行Few-shot Fine-tuning。
统一的Prompting范式
具体地,预训练模型在不同的下游任务上进行Prompt-Tuning时,需要为特定任务设计固定的Prompt模式(PVP,即Prompt-Verbalizer-Pair),模型很难同时利用这些Task共有的信息,我们把各种NLP任务统一成如下格式:
- P(Prompt):表示任务相关的Prompt,至少包含一个[MASK]token;
- O(Option):通过提问的形式列出Verbalizer中的候选项;
- V(Verbalizer):定义的label word与标签的映射关系。
对于监督学习的任务,我们给出以下两个例子,分别对应单句文本分类和双句文本匹配:
- 评论分类:“[X]. Is great or bad? It was [MASK].”;
- 论文连贯性预测:“[X1]. Is this paragraph the same as the next: [X2]?It was [MASK].”
融入自监督任务
对于自监督任务,在Pre-training阶段,我们没有见过现有的这种模式,以至于在Prompt-Tuning时很难让模型快速学习到Prompt的信息,因此本部分旨在改进原始的自监督任务Masked Language Modeling(MLM),并拓展到Prompt中。需要注意的是,我们并不重新训练语言模型,而是将Prompt-MLM作为一个辅助任务。
原始的MLM是给定一个句子,随机挑选一个或多个位置并替换为[MASK],并让模型通过MLM head预测每个[MASK]位置的Word(或sub-word)。例如给定一个句子“Disney movies are so wonderful that I insist on watching two every week.”,随机Mask一个Word:“Disney movies are so [MASK] that I insist on watching two every week.”,然后让模型预测该位置可能的词。
我们提出的Prompt-MLM的主要流程如下图所示:
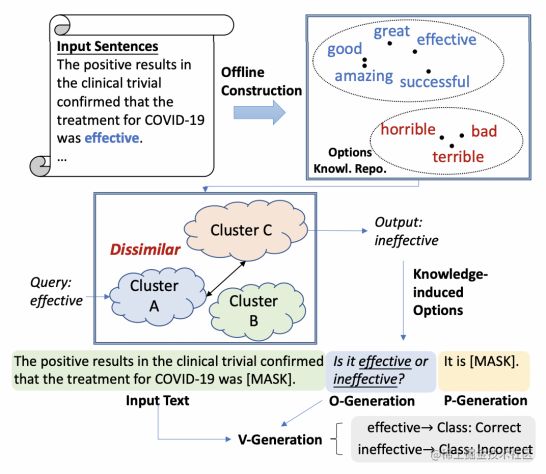
我们首先从预训练语料中检测出高频的形容词,并且进行词义相似度聚类。对于一句输入的句子,我们对该文本进行词性标注,选出该文本形容词所在的位置,作为Mask的位置。之后选出与该形容词最不相似的Cluster中的某个形容词,作为另一个选项,构建出Options。最后,我们将MLM任务转化为基于Prompt的二分类任务,同时无需进行任何数据标注。
算法精度评测
为了验证上述算法的有效性,我们对经典和自研的小样本学习算法进行了精度评测。在实验中,我们使用Roberta-large作为预训练语言模型,对每个下游任务,在训练过程中我们只抽取每个类别的16个样本进行学习,在所有测试集上进行评测。在下表中,我们列出了标准Fine-tuning,经典小样本学习算法LM-BFF、PET、P-tuning、PPT等的在9个公开数据集上的实验效果,使用准确度(Accuracy,%)作为模型效果评测指标:
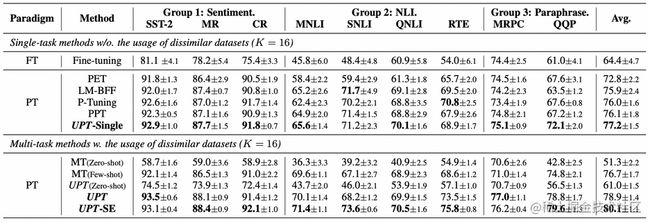
由上述结果可见,我们提出的自研算法UPT在多个数据集上具有明显精度提升。我们也在多个SuperGLUE的数据集上验证了UPT的实验效果。结果如下所示:

此外,PAI团队也荣获FewCLUE中文小样本学习公开评测榜单第一名的成绩(看这里),成绩超越腾讯、百度、平安等资深厂商。为了更好地服务开源社区,UPT算法的源代码即将贡献在自然语言处理算法框架EasyNLP中,欢迎NLP从业人员和研究者使用。
EasyNLP开源框架:https://github.com/alibaba/EasyNLP
参考文献
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022 (accepted)
- Tianyu Gao, Adam Fisch, Danqi Chen. Making Pre-trained Language Models Better Few-shot Learners. ACL/IJCNLP 2021: 3816-3830
- Timo Schick, Hinrich Schütze. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. EACL 2021: 255-269
- Timo Schick, Hinrich Schütze. It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners. NAACL-HLT 2021: 2339-2352
- Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, Jie Tang. GPT Understands, Too. CoRR abs/2103.10385 (2021)
- Chengyu Wang, Jianing Wang, Minghui Qiu, Jun Huang, Ming Gao. TransPrompt: Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification. EMNLP 2021: 2792-2802
论文信息
论文名字:Towards Unified Prompt Tuning for Few-shot Text Classification
论文作者:王嘉宁、汪诚愚、罗福莉、谭传奇、邱明辉、杨非、石秋慧、黄松芳、高明
论文pdf链接:https://arxiv.org/abs/2205.05313