seq2seq模型_对话生成:seq2seq模型原理及优化

更多干货内容敬请关注「平安寿险PAI」(公众号ID:PAL-AI),文末有本期分享内容资料获取方式。
人机对话作为人机交互系统的核心功能之一,发挥着十分重要的作用。目前,生成式的人机对话存在内容把控性较弱,生成内容不一定符合场景需求的问题。所以,在实际运用中往往需要对模型做出更多的调整和控制,使生成的对话更适用于具体场景。
1月8日,由平安寿险AI团队在Paper Weekly直播间进行的主题为「对话生成模型」的技术分享,由资深算法工程师姚晓远主讲,其内容分4个部分:
- 寿险的人机对话业务介绍
- Seq2Seq 对话模型原理
- 基于主题规划和文本属性控制的Seq2Seq模型优化
- Seq2Seq 模型在寿险业务的实践介绍
分享老师:姚晓远
平安寿险人工智能研发团队资深算法工程师。毕业于武汉大学,获得硕士学位,研究方向为自然语言处理。曾任职于百度,现为寿险人工智能研发团队资深算法工程师,具有 5 年人工智能研发经验。曾作为主要开发人员参与图片广告、事件图谱、智能客服等项目,目前担任人机交互算法研发负责人,主要进行对话生成、问答匹配算法研发。
以下是根据本期技术分享内容整理的文字稿。
一、寿险的人机对话业务介绍
1. 对话机器人的常见应用
目前,对话机器人是一个热门话题,大家熟知的应用和产品主要有三种:
第一种是虚拟助手,能对个人输入完成相应的任务或提供相应服务,典型的商业产品包括如siri、cortana、度秘等;
第二种是智能音箱,通过语音交互,完成用户任务,也能对智能家居设备进行控制。典型的商业产品包括如echo、天猫精灵、小爱同学等;
第三种是闲聊对话,在开放域与用户进行闲聊。典型的商业产品如:微软小冰。

2. 寿险业务场景的对话机器人
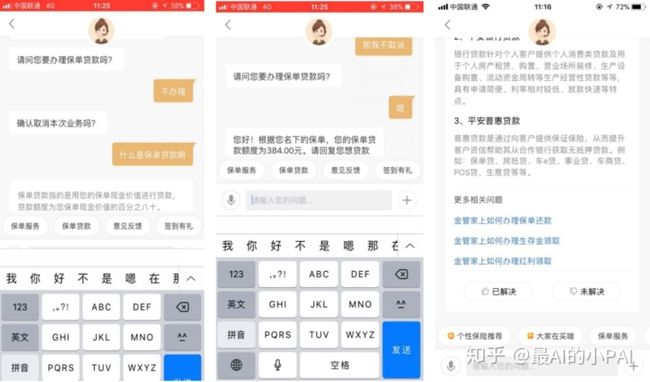
在保险业务场景下,最为人熟悉的对话机器人应用就是“客服机器人”。
平安寿险客服机器人主要基于自然语言处理、深度学习、OCR、风控等技术,可实现寒暄、业务咨询、业务办理(属业内首创)、产品及服务推荐等功能,为用户提供一站式“服务+推荐”的优秀体验。
3. 对话机器人的任务类型
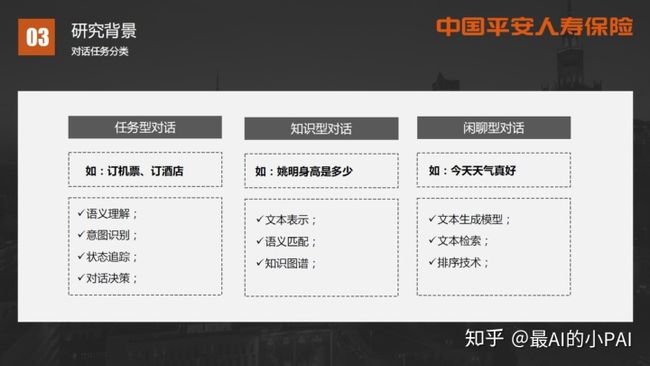
对话机器人的任务类型可以分为三类:
第一类是任务型对话,主要解决如订机票、订酒店等问题。它涉及的技术包括:语义理解、意图识别、状态追踪、对话决策等;
第二类是知识型对话,在寿险客服的场景里,用户可能会问“你这个保险要交多少钱?”这类问题。它涉及的技术包括:文本表示、语义匹配、知识图谱等;
第三类是闲聊型对话,用户可能只想找人聊聊天,对话不涉及到知识或业务,比如说“今天天气真好”。它涉及的技术包括:文本生成模型、文本检索、排序技术等;
4. 让闲聊更有用
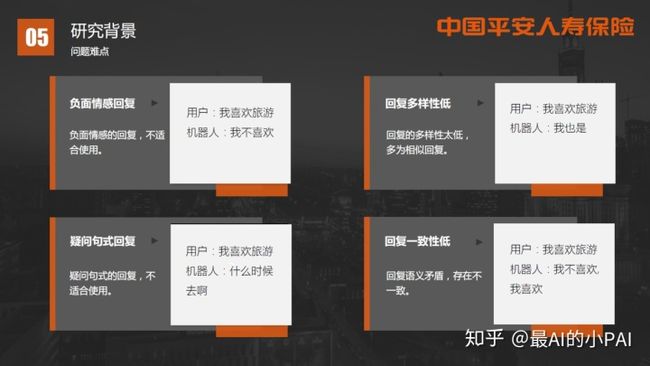
以解决闲聊型任务为例,大家较为熟悉的,是用seq2seq生成闲聊型机器人。但普通seq2seq可能出现如负面情感的回复、疑问句式的回复、回复的多样性较低等问题,导致用户体验差或者对话上下文不够连贯。

在没有任何约束的聊天情境下,这种回复可能问题不大。但在寿险业务场景中,客服机器人需要引导客户尽快结束闲聊,开启(或延续上一个)任务型对话。
在这种背景下,如果客服机器人回复一个疑问句式,给用户的感觉会比较奇怪。另外,如果在较严肃的对话场合中,客服机器人给出了一个负面情感倾向的回应,用户体验也会较差。
因此,负面情感回复、疑问句式回复、回复多样性低、一致性低,都是研发寿险客服机器人需要攻克的难点。
二、Seq2Seq 对话模型原理
1. 模型探析
生成一段对话回复的模型可以简单分为三类:
一是规则模板。典型的技术就是AIML语言。这种回复实际上需要人为设定规则模板,对用户输入进行回复。
优点是:1、实现简单,无需大量标注数据;2、回复效果可控、稳定。
不足是:1、如果需要回复大量问题,则需要人工设定大量模板,人力工作量大;2、使用规则模板生成的回复较为单一,多样性低。
二是生成模型。主要利用编码器-解码器结构对回复进行。典型技术是Seq2Seq、transformer。
优点是:无需规则,能自动从已有对话文本中学习如何生成文本。
不足是:1、生成效果不可控,训练好的模型更像是一个“黑盒”,也无法干预模型的生成效果;2、倾向生成万能回复,如“好的”、“哈哈”等,所以多样性与相关性低。
三是检索模型。利用文本检索与排序技术从问答库中挑选合适的回复。
优点是:由于数据来源于已经生成好的回复,或是从已抓取的数据得到的回复,所以语句通顺性高,万能回复少;
不足是:1.不能生成新的回复文本,只能从问答库中得到文本进行回复;2.当检索或排序时,可能只停留在表面的语义相关性,难以捕捉真实含义。
2. RNN模型回顾
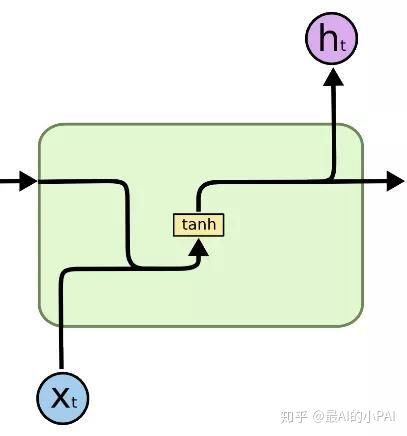
RNN是能够对序列进行建模的神经网络。它的每一个时刻的状态,由当前的输入以及上一个时间步的状态来决定,经过线性变化和激活函数,就可以完成一个RNN建模。
这里存在的问题是,在神经网络训练过程中,更新参数需要计算梯度,这里的梯度计算里存在连乘,导致梯度趋于0或者趋于无穷大,使得模型无法有效地学习到长距离的依赖关系。
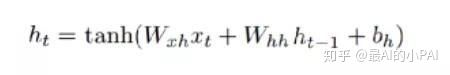
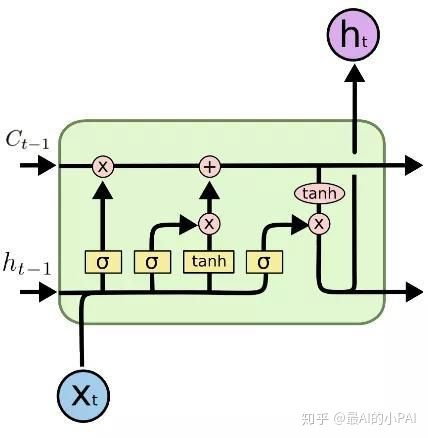
LSTM是RNN的一种常见的改进模型,引用了门机制去解决梯度爆炸或者梯度消散的问题。门计算所需要用到的参数,由模型自己去进行学习。每一个门都有对应的参数,每一个门的每次计算,是根据当前的输入前一刻的状态,以及内部状态,来计算门的值是什么,最后再对整个状态进行更新。
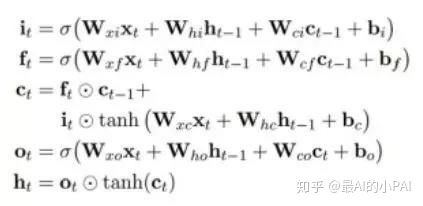
GRU是另一个对RNN进行改进的模型,可以看作是LSTM的变形。相对于LSTM ,GRU模型减少了一个门,参数量也会变少。因此,最终GRU的速度比RNN、LSTM更快一些。

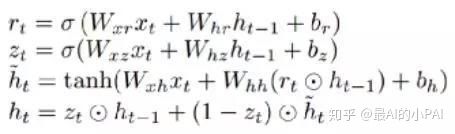
3. seq2seq模型回顾
了解RNN后,我们就可以引入seq2seq模型了。在seq2seq模型里,实际上输入的是一段序列文本,生成的也是一段序列文本。
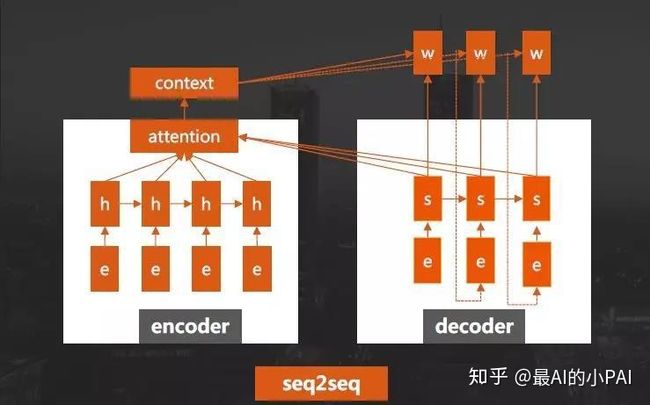
Encoder:seq2seq的编码器是单层或多层的RNN(双向),会对输入的文本进行编码变成一个向量输出。
Decoder:seq2seq的解码器,也是一个单层或多层的RNN(非双向),然后根据context信息对每一步进行解码,输出对应的文本。
这里提到的每步context,最简单的方法是直接拿encoder的输入文本信息的最后一个状态,或者是整个状态进行加总,得到一个固定的向量。然后,再将这个向量作为decoder的context进行输入。
但这样的问题是,这个context是一个固定长度的向量,表达能力比较有限,所以在这个基础上,又提出了Attention机制。
Attention机制:每步解码都会根据当前状态对encoder的文本进行动态权重计算,然后对权重进行归一化。得到归一化后,再算出一个当前加权后的context,作为decode的context。这样处理后的表达能力就会就会更强一些。
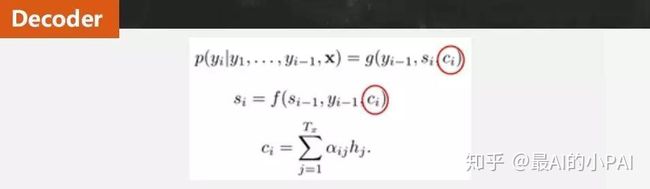
下图是一种比较常见的Attention形式,通过加法来完成。其他的Attention形式可能会通过乘积来完成权重计算。

优化目标:有了前面的组件后,我们可以定义一个优化目标。优化目标实际上就是对每一步的单词计算一个交叉熵,然后把它给加起来,最后得到一个损失函数。
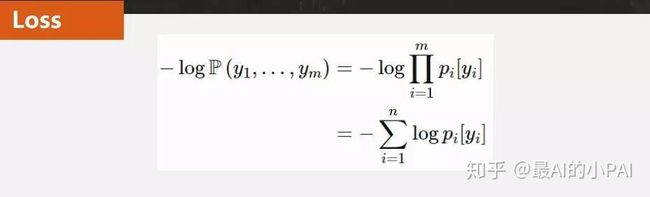
4. Beam Search
前面提到seq2seq模型以及训练目标是如何训练的,再涉及到的问题,就是模型是如何进行预测的。这里可能会存在的问题是:
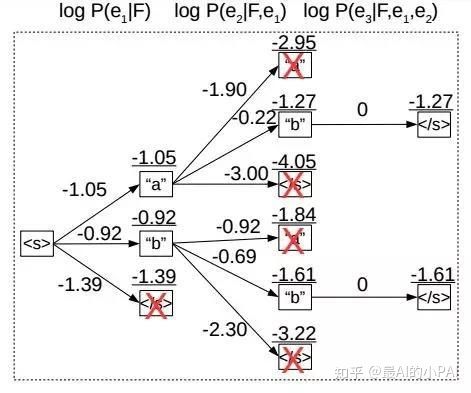
贪心搜索:每一步搜索都取概率最大的分支,容易陷入局部最优解。
比如,可能当前一步的概率很大,但后面的概率都很小,这样搜索出来的文本就不是全局的最优解。
但如果对整个空间进行搜索,可能搜索空间太大,无法全部搜索。
Beam Search:采取折中的办法,每次搜索只保留最优的k条路径,搜索结果优于贪心搜索,因为每一步并非按最大的去选一个;时间复杂度也可以根据对“K”的设置进行控制;(如下图:每次搜索只保留最优的2条路径)
但在对话来说,Beam Search可能会产生的问题是:可能都是十分相近的句子。
举个例子:当用户说“我喜欢打篮球”,搜索出来的结果可能是“我也是。”“我也是!”“我也是……”只有标点符号不同,这样多样性依然很低。
三、基于主题规划和文本属性控制的 Seq2Seq 模型优化
基于已有的seq2seq模型以及上述需要解决的问题,我们调研了大量论文,下面摘取对“对话生成”借鉴意义比较大的重点来阐述。
1. Copy机制
这里介绍的论文是发表在ACL2017的《Get To The Point: Summarization with Pointer-Generator Networks》
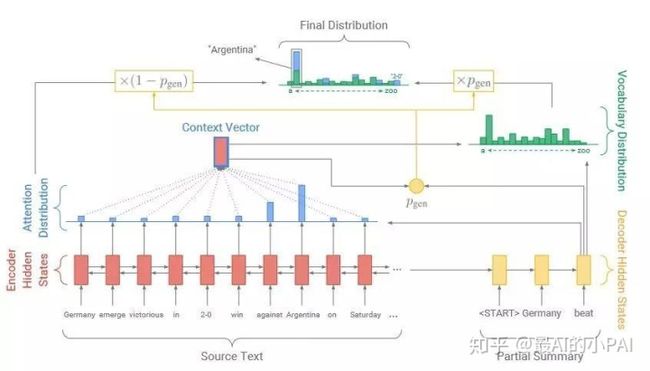
Copy机制最初设计用于解决OOV问题。当生成一段文本的时候,这个生成单词可以有两种来源:一种是通过普通seq2seq生成;另一种是从原文本拷贝过来。比如普通的生成任务里,他往往有大量的OOV(out of vocabulary),这样的词是无法生成的,以至于回复效果会变差。
Copy机制的好处在于,当生成单词的时候,既可以是生成的,也可以是从Source Text里面直接拷贝过来。
当然,Copy机制有很多实现办法,这里讲的是最容易理解与实现的一种,即将每步输出的单词概率看作一个混合模型(生成的单词概率分布与拷贝原文的单词概率分布的混合),利用注意力得分作为拷贝单词的概率。
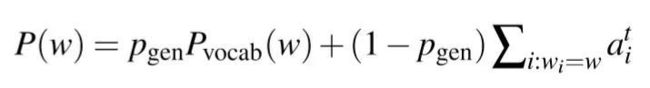
注意力的得分的明显特点是,它经过了归一化,代表了这段文本中不同单词在当前步骤的重要程度,可以看作拷贝不同单词的概率。这个最早用在point network模型里面。
将Copy机制用于闲聊后,回答的相关性和流畅性会更高。举个例子,当用户说“我老家是湖南的”,普通的seq2seq生成回答“我也是”就结束了。有了Copy机制后,对原文拷贝单词的概率会更大,可能生成的回答是“我也是湖南的。” 这样回答相关性会更高。
2. 基于控制主题的seq2seq的模型——主题控制
前面曾提到普通的seq2seq生成的内容,其实没有办法把控生成的语义信息。我们希望生成更有意义的回复,以提高闲聊相关性、流畅性。
论文里提到的“Content-Introducing”(为便于理解,我们称之为“控制主题”模型),就是通过增加关键词信息,用关键词去影响生成回复的语义(主题),以下介绍两种解决思路。
思路一:用关键词作为硬约束
这里介绍的论文是发表在ACL2016的《Sequence toBackward and Forward Sequences: A Content-Introducing Approach to GenerativeShort-Text Conversation》
我们先考虑一种最简单的情况:假设预测出的关键词在生成文本中一定会出现。这里论文提出一种直观且简单的预测关键词方法:利用互信息进行预测,即取与问题互信息最大的词作为关键词。
有了关键词,下面我们考虑如何对回复进行生成。每次的生成包含两步:第一步,生成包含关键词的前半句话;第二步,生成后半句话;
如下图,当被问及“Where are you from”,首先生成地点单词“Osaka”,第一步根据地点单词生成前半句“from”“am”“I”,第二步再生成后半句“Japan”。相当于一个单词把文本隔成两段,分两步生成整句话。
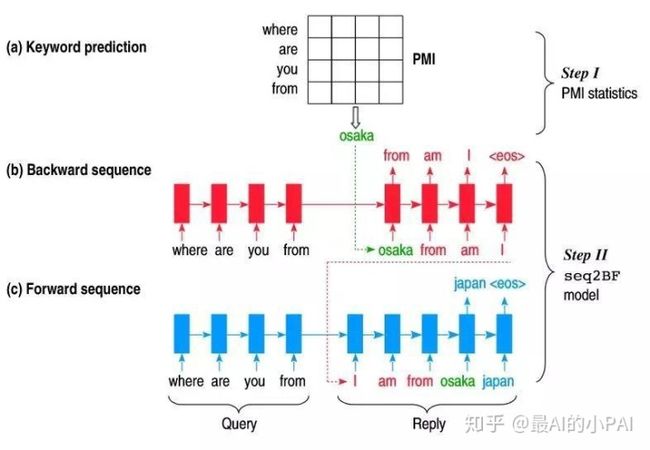
这里可能存在的问题是,当遇到预测的单词不准,或者在对话中出现较少时,上下句可能衔接不够流畅。在此引入第二种思路。
思路二:用关键词作为软约束
这里介绍的论文是发表在Emnlp2016的《Towards implicit content-introducing for generative short-textconversation systems》。
第二个思路假设关键词在生成文本中不一定会出现,只作为额外信息输入到网络里;设计cue word gru单元,将关键词信息加入到每一步的状态更新;
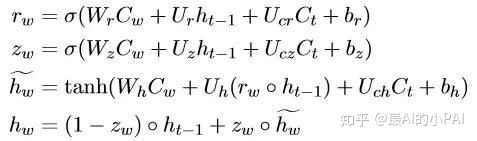
首先,这里有两个GRU单元。一个普通GRU负责记录对话的状态、上下文等内容,另一个Cue word GRU记录当前关键词信息,利用设计的fusion unit结构融合普通GRU与Cue word GRU单元。
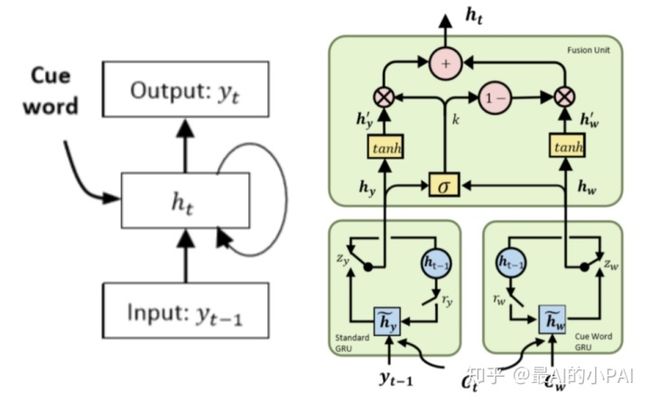
个人理解,这与门机制类似,要将两个部分的信息合在一起。那每个信息需要流入多少呢?实际上就是通过一个网络去计算。通过加权合并,就可以知道普通seq2seq的信息和关键词信息。最终,模型就能学习出如何生成一个既能承接上句,又包含关键词语义的回复。
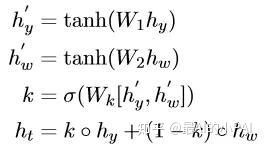
思路三:用关键词同时约束主题与情感
在这里,我们介绍的论文是,于2018年发表在Emnlp的《A Syntactically Constrained Bidirectional-Asynchronous Approach for Emotional Conversation Generation》。目前我们团队只做了调研,还没有展开实验。

论文里,假设每个生成的回复都包括一个情感关键词与主题关键词,即序列为[y_ct, w_tp, y_md,w_et, y_ce],其中w_tp为主题关键词,w_et为情感关键词,y_ct,y_md,y_ce为剩下对应位置的文本序列。
首先预测情感关键词与主题关键词。有了两个关键词后,就可以考虑如何生成文本。每次首先生成中间的文本序列y_md,再分别生成剩下的两段文本,最后对这段文本的真实方向进行二分类,输出最终生成的文本。
3. 基于控制主题的seq2seq的模型——属性控制
为了避免出现负面情感或疑问句式的回应,我们希望模型能学习到文本的属性信息(句式、情感信息),从而能够控制生成文本风格,使生成的回复更为可控。下面我们考虑的是对文本属性进行控制的生成模型。
思路一:直接融合属性信息
这里介绍的是一个相对简单的模型(如下图),输入的文本除了encoder的信息,还包括属性embedding的信息。这样一来,每一步解码都会带上属性信息,模型就会学习如何根据两段信息合理地生成单词。
举个例子,比如在label embedding,第1个是正面情感的embedding,第2个是肯定句式的embedding,最后就会生成一个正面情感的肯定句。
思路二:用条件变分编码器
这里介绍的论文是《Generating Informative Responses with Controlled Sentence Function》。
这篇论文中使用条件变分编码器的网络结构去控制回复的句式,使模型生成一些更有信息量的回复。
在变分编码器中,我们希望隐变量z更好的进行编码。这篇文章通过约束中间隐变量z,使z更多地去编码句式属性的信息。
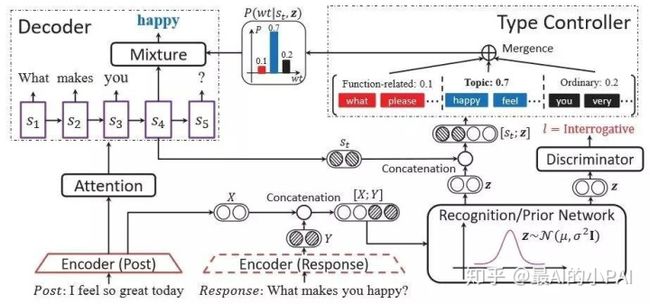
这里采用的是通过加入判别器来实现对z的约束。判别器对编码后得到的中间隐变量z,经过分类判断它是陈述句、疑问句或是祈使句。
为了更好地对生成的单词进行建模,论文中分别对控制句式相关的词、主题相关的词、普通词计算概率,最后利用一个混合模型计算出最后的概率。
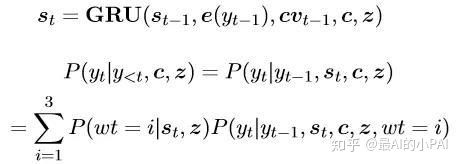
混合模型在每次生成单词时,会先用隐变量信息计算生成哪种词,得到三种单词分别的生成概率,最后进行加权得到生成一个单词的概率。
由于加入了条件变分编码器和判别器,最终的训练loss是三个部分之和:先验分布与后验分布的kl散度、判别器分类交叉熵、普通seq2seq的loss。
4. 改进Beam Search——提高回复多样性
前面主要解决的是生成回复不可控的问题,如控制回复属性(情感、句式)、控制回复主题等内容。后面,我们继续调研大量文章,来解决回复多样性的问题。以下讨论的是改进Beam Search。
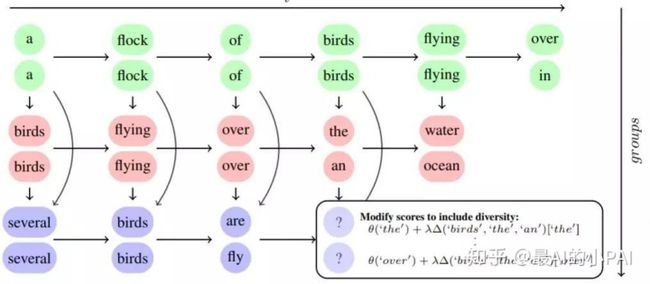
Beam Search的多样性低,主要因为它总是选择一条分支路径,导致最后的生成回复都差不多。
思路一:通过增加惩罚项,比如对同一组的第二、第三选项进行降权,从而避免每次搜索结果都来自于同一路径。对于权重的选择,可以通过强化学习得到;也可以通过设置参数、调整参数来得到(如下图)。

思路二:计算每条路径的概率分,如果后面生成的话跟第一组相似,就对该组进行降权,避免组与组之间相似度过高(如下图)。
四、Seq2Seq 模型在寿险业务的实践介绍
1. 实验数据
基于以上模型的调研和优化,结合寿险的业务场景,我们进行了一些实验与效果评估。
实验数据来自于微博,我们参考了一些论文的设计方法,将情感标签分为6类:喜爱、悲伤、厌恶、生气、高兴、其他;句式标签分为3类:疑问句、祈使句、陈述句。
数据样例请参考下图。

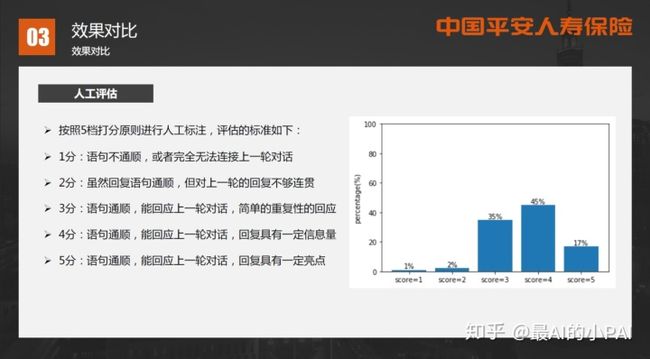
2. 效果对比
从实验数据看(如下图),如果用seq2seq、copy可能会生成疑问句,这是我们在业务场景下不愿意看到的情况。而我们改进的模型c-seq2seq、vae-seq2seq生成的回复,大部分能保证是正面和肯定句式的回复。

我们的效果评估主要运用人工评估方式。在对话场景中,很多千变万化的回复可能都是好的,并非说生成的对话一定跟训练集或测试集的目标越接近才越好,所以很难用自动化标准去评估。
3. 模型对比
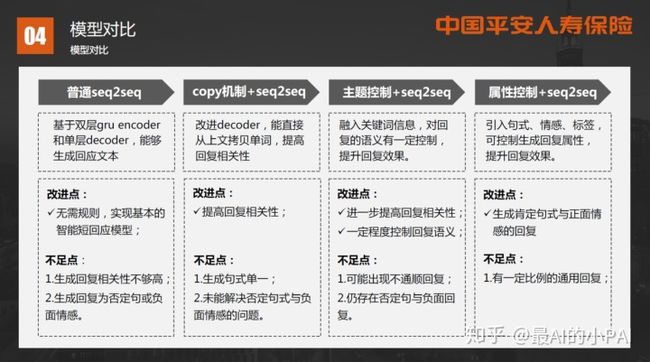
普通seq2seq存在生成回复相关性不够高、生成回复为否定句或负面情感的问题。
Copy机制+seq2seq:提高了回复相关性,但依然无法解决回复为否定句或负面情感的问题。
主题控制+seq2seq:既提高回复相关性,也可以控制回复语义,提升回复效果,但可能出现回复不通顺的问题,并存在否定句式与负面回复。
属性控制+seq2seq:比较能满足场景需要,但有一定比例的通用回复,可以通过改进Beam Search、后排序的办法来提高个性化回复的得分,从而提高回复多样性。
4. 总结
在对话生成任务上,探索了copy机制、主题控制、属性控制、diverse beam search等多种提高回复效果的方法。在内部场景中进行实验,其中的属性控制模型能有效提升回复质量,获得了较好效果。
五、资料获取
获取本期直播视频及资料方式如下:
1 / 关注「平安寿险PAI」(ID:PAL-AI)
2 / 后台回复“对话生成模型”即可获取下载链接

Reference:
- Abigail See, Peter J. Liu, and Christopher D. Manning. Getto the point: Summarization with pointer-generator networks. In Proceedings ofthe 55th Annual Meeting of the Association for ComputationalLinguistics (Volume1: Long Papers), pp. 1073-1083, July 2017.
- Mou L, Song Y, Yan R, et al. Sequence to Backward andForward Sequences: A Content-Introducing Approach to Generative Short-TextConversation[J]. 2016.
- Yao L, Zhang Y, Feng Y, et al. Towards implicitcontent-introducing for generative short-text conversationsystems[C]//Proceedings of the 2017 Conference on Empirical Methods in NaturalLanguage Processing. 2017:2190-2199.
- Li J, Sun X. A Syntactically ConstrainedBidirectional-Asynchronous Approach for Emotional ConversationGeneration[C]//Proceedings of the 2018 Conference on Empirical Methods inNatural Language Processing. 2018:678-683.
- Ke P, Guan J, Huang M, et al. Generating InformativeResponses with Controlled Sentence Function[C]//Proceedings of the 56thAnnual Meeting of the Association for Computational Linguistics (Volume 1: LongPapers). 2018, 1: 1499-1508.
- Li J, Monroe W, Jurafsky D. A Simple, Fast, DiverseDecoding Algorithm for Neural Generation[J]. arXiv preprint arXiv:1611.08562,2016.
- Vijayakumar A K, Cogswell M, Selvaraju R R, et al. Diversebeam search: Decoding diverse solutions from neural sequence models[J]. arXivpreprint arXiv:1610.02424, 2016.