神经网络:GRU基础学习
1、GRU 简介
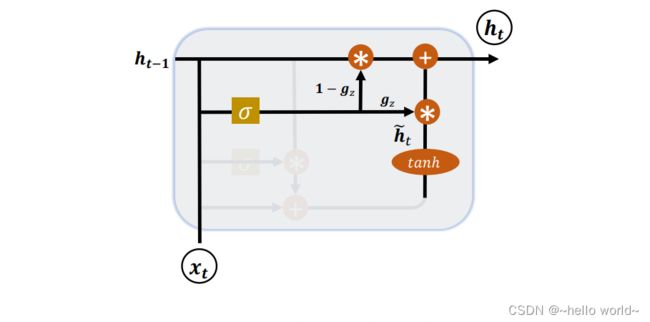
LSTM 具有更长的记忆能力,在大部分序列任务上面都取得了比基础的 RNN 模型更好的性能表现,更重要的是,LSTM 不容易出现梯度弥散现象。但是 LSTM 结构相对较复杂,计算代价较高,模型参数量较大。研究发现,遗忘门是 LSTM 中最重要的门控,甚至发现只有遗忘门的简化版网络在多个基准数据集上面优于标准 LSTM 网络。在众多的简化版 LSTM 中,门控循环网络(Gated Recurrent Unit,简称 GRU)是应用最广泛的 RNN 变种之一。GRU 把内部状态向量和输出向量合并,统一为状态向量 ,门控数量也减少到 2 个:复位门(Reset Gate)和更新门(Update Gate),如图下所示:

2、复位门
复位门用于控制上一个时间戳的状态 h−1 进入 GRU 的量。门控向量 由当前时间戳输入 和上一时间戳状态 h−1 变换得到,关系如下:

其中 和 为复位门的参数,由反向传播算法自动优化,为激活函数,一般使用 Sigmoid 函数。门控向量 只控制状态 h−1,而不会控制输入 :
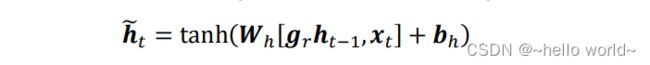
当 = 0 时,新输入 h ̃ 全部来自于输入 ,不接受 h−1,此时相当于复位 h−1。当 = 1 时,h−1 和输入 共同产生新输入h ̃ ,如下图所示:

3、更新门
更新门用控制上一时间戳状态 h−1 和新输入h ̃ 对新状态向量 h 的影响程度。更新门控向量 由下列公式的得到:

其中 和 为更新门的参数,由反向传播算法自动优化,为激活函数,一般使用 Sigmoid 函数。 用与控制新输入h ̃ 信号,1 − 用于控制状态 h−1 信号:
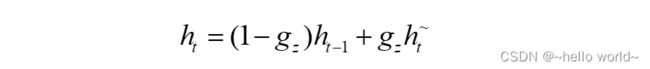
可以看到,h ̃ 和 h−1 对 h 的更新量处于相互竞争、此消彼长的状态。当更新门 = 0时,h 全部来自上一时间戳状态 h−1;当更新门 = 1时,h 全部来自新输入h ̃。
4、GRU 使用方法
同样地,在 TensorFlow 中,也有 Cell 方式和层方式实现 GRU 网络。GRUCell 和 GRU 层的使用方法和 SimpleRNNCell、LSTMCell、SimpleRNN 和 LSTM 非常类似。首先是 GRUCell 的使用,创建 GRUCell 对象,并在时间轴上循环展开运算。例如:
inputs = [tf.zeros([2,50,64])]
rnn = tf.keras.layers.RNN(tf.keras.layers.GRUCell(64))
output = rnn(inputs)
print(output.shape) # [2, 64]
通过 layers.GRU 类可以方便创建一层 GRU 网络层,通过 Sequential 容器可以堆叠多层 GRU 层的网络。例如:
net = keras.Sequential([
layers.GRU(64, return_sequences=True),
layers.GRU(64)
])
out = net(x)
out.shape
TensorShape([4, 64])
.
5、GRU 情感分类问题实战
首先是 Cell 方式。GRU 的状态 List 只有一个,和基础 RNN 一样,只需要修改创建Cell 的类型,代码如下:
# 构建 2 个 Cell
self.rnn_cell0 = layers.GRUCell(units, dropout=0.5)
self.rnn_cell1 = layers.GRUCell(units, dropout=0.5)
对于层方式,修改网络层类型即可,代码如下:
# 构建 RNN
self.rnn = keras.Sequential([
layers.GRU(units, dropout=0.5, return_sequences=True),
layers.GRU(units, dropout=0.5)
])
Cell 方式完整代码
import tensorflow as tf
import numpy as np
import tensorflow as keras
from tensorflow.keras import losses,Sequential,optimizers,layers,datasets
#批量大小
batchsz=128
#词汇表大小N_vocab
total_words=10000
#句子最大长度 s,大于的句子部分将截断,小于的将填充
max_review_len=80
#词向量特征长度
embedding_len=100
# 加载IMDB数据集,此处的数据采用数字编码,一个数字代表一个单词
(x_train,y_train),(x_test,y_test)=datasets.imdb.load_data(num_words=total_words)
# 截断和填充句子,使得等长,此处长句子保留句子后面的部分,短句子在前面填充
x_train=tf.keras.preprocessing.sequence.pad_sequences(x_train,maxlen=max_review_len)
x_test=tf.keras.preprocessing.sequence.pad_sequences(x_test,maxlen=max_review_len)
# 构建数据集,打散,批量,并丢掉最后一个不够batchsize的batch
train_db=tf.data.Dataset.from_tensor_slices((x_train,y_train))
test_db=tf.data.Dataset.from_tensor_slices((x_test,y_test))
train_db=train_db.shuffle(1000).batch(batchsz,drop_remainder=True)
test_db=test_db.batch(batchsz,drop_remainder=True)
class MyLMST(tf.keras.Model):
def __init__(self,units):
super(MyLMST,self).__init__()
self.state0=[tf.zeros([batchsz,units])]
self.state1=[tf.zeros([batchsz,units])]
#词向量编码[b,80]=>[b,80,100]
self.embedding=layers.Embedding(total_words,embedding_len,input_length=max_review_len)
#构建2个cell,使用dropout技术防止过拟合
self.run_cell0=layers.GRUCell(units,dropout=0.5)
self.run_cell1=layers.GRUCell(units,dropout=0.5)
self.outlayer = Sequential([
layers.Dense(units),
layers.Dropout(rate=0.5),
layers.ReLU(),
layers.Dense(1)
])
def call(self,inputs,training=None):
x=inputs
#获取词向量[b,80]=>[b,80,100]
x=self.embedding(x)
#通过2个LSTM CELL,[b,80,100]=>[b,64]
state0=self.state0
state1=self.state1
# word:[b, 100]
for word in tf.unstack(x,axis=1):
out0,state0=self.run_cell0(word,state0,training)
out1,state1=self.run_cell1(out0,state1,training)
#末层最后一个输出作为分类网络的输入:[6,64]=>[b,1]
x=self.outlayer(out1,training)
#通过激活函数p(y is pos[x])
prob=tf.sigmoid(x)
return prob
def main():
units=64
epochs=20
learning_rate=0.001
model=MyLMST(units)
#装配
model.compile(optimizer=optimizers.Adam(learning_rate),
loss=losses.BinaryCrossentropy(),
metrics=['accuracy'],experimental_run_tf_function=False)
#训练和验证
model.fit(train_db,epochs=epochs,validation_data=test_db)
#测试
model.evaluate(test_db)
if __name__=='__main__':
main()
层方式完整代码
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Sequential, layers, optimizers, losses
import numpy as np
# 加载数据
# 批大小
batchsize = 128
# 词汇表大小
total_words = 10000
# 句子最大长度s,大于的句子部分将截断,小于的将填充
max_review_len = 80
# 词向量特征长度n
embedding_len = 100
# 加载IMDB数据集,此处的数据采用数字编码,一个数字代表一个单词
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# 截断和填充句子,使得等长,此处长句子保留句子后面的部分,短句子在前面填充
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
# 构建数据集,打散,批量,并丢掉最后一个不够batchsize的batch
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsize, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsize, drop_remainder=True)
# 网络模型
class MyRNN(keras.Model):
# Cell方式构建多层网络
def __init__(self, units):
super(MyRNN, self).__init__()
# [b, 64], 构建Cell初始化状态向量,重复使用
self.state0 = [tf.zeros([batchsize, units]), tf.zeros([batchsize, units])]
self.state1 = [tf.zeros([batchsize, units]), tf.zeros([batchsize, units])]
# 词向量编码[b, 80] => [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len)
# 构建RNN
self.rnn = keras.Sequential([
layers.GRU(units, dropout=0.5, return_sequences=True),
layers.GRU(units, dropout=0.5)
])
# 构建分类网络,用于将CELL的输出特征进行分类,2分类
# [b, 80, 100] => [b, 64] => [b, 1]
self.outlayer = Sequential([
layers.Dense(units),
layers.Dropout(rate=0.5),
layers.ReLU(),
layers.Dense(1)])
def call(self, inputs, training=None):
# [b, 80]
x = inputs
# 获取词向量:[b, 80] => [b, 80, 100]
x = self.embedding(x)
# 通过2个RNN CELL,[b, 80, 100] => [b, 64]
x = self.rnn(x)
# 末层最后一个输出作为分类网络的输入:[b, 64] => [b, 1]
x = self.outlayer(x, training)
# 通过激活函数,p(y is pos|x)
prob = tf.sigmoid(x)
return prob
def main():
units = 64
epochs = 20
model = MyRNN(units)
# 装配
model.compile(optimizer=optimizers.Adam(1e-3),
loss=losses.BinaryCrossentropy(), metrics=['accuracy'],
experimental_run_tf_function=False)
# 训练和验证
model.fit(db_train, epochs=epochs, validation_data=db_test)
# 测试
model.evaluate(db_test)
if __name__ == '__main__':
main()