【ML】降维:LDA线性判别分析
LDA线性判别分析
有监督降维。目标是降维后的组内(同一类别)方差小,组间(不同类别)方差大。
作用:
-
降维

-
分类


LDA的原理
1.将原有的 p p p维数据集,转换为 k k k维数据, k < p kk<p
寻找当前所在的 p p p线性空间的一个 k k k维线性子空间,在这个 k k k维空间表示这些数据(将数据投影到 k k k维空间);
2.按照类别区分新生成的 k k k维数据,同一类别的数据点距离越近越好,不同类别间距离越远越好
与PCA相比,LDA更关心分类而不是方差。
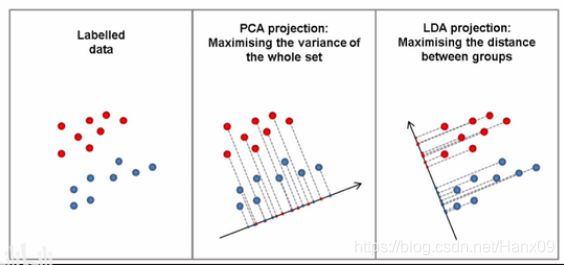
如果将数据直接投影到连接两中心的向量上降维,数据会有重叠,并不是最优。本来可以进行线性分割数据,降维后无法进行线性分割了。
为减少重叠,降维的数据应满足两个特征:
- 不同类别数据降维后相互间的差异大;
- 同一类别数据降维后相互间的差异小;
也就是说,最大化类间距离和最小化类内距离。

LDA的推导
设有包含 n n n个样本的训练数据集 T T T,共有 C C C个类别,第 i i i个类别有 n i n_i ni个样本,可写第 i i i个类别的数据集 D i = { x i j , j = 1 , 2 , . . . , n i } D_i=\{x_i^j, j=1,2,...,n_i\} Di={xij,j=1,2,...,ni},其中每个样本 x i j x_i^j xij都是 p p p维的列向量, i = 1 , 2 , . . . , C i=1,2,...,C i=1,2,...,C,每个类别的样本均值及方差为,
μ i = 1 n i ∑ j = 1 n i x i j \mu_i=\frac{1}{n_i}\sum_{j=1}^{n_i}x_i^j μi=ni1j=1∑nixij
s i 2 = 1 n i − 1 ∑ j = 1 n i ( x i j − μ i ) 2 s_i^2=\frac{1}{n_i-1}\sum_{j=1}^{n_i}(x_i^j-\mu_i)^2 si2=ni−11j=1∑ni(xij−μi)2
整体的均值,
μ = 1 n ∑ i = 1 C ∑ j = 1 n i x i j \mu=\frac{1}{n}\sum_{i=1}^C\sum_{j=1}^{n_i}x_i^j μ=n1i=1∑Cj=1∑nixij
情形一: C = 2 C=2 C=2
数据集只有两个类别,我们现在要将原始数据降低到只有一维。设 w w w是一个合适的投影方向,现在推导 w w w应该满足什么条件。
样本 x i j x_i^j xij在 w w w方向的投影,
y i j = w T x i j , j = 1 , . . . , n i , i = 1 , 2 y_i^j=w^Tx_i^j,\quad j=1,...,n_i,i=1,2 yij=wTxij,j=1,...,ni,i=1,2
投影后每个类别的样本均值与样本方差为,
μ ~ i = 1 n i ∑ j = 1 n i y i j = 1 n i ∑ j = 1 n i w T x i j = w T μ i , i = 1 , 2 \tilde{\mu}_i=\frac{1}{n_i}\sum_{j=1}^{n_i}y_i^j=\frac{1}{n_i}\sum_{j=1}^{n_i}w^Tx_i^j=w^T\mu_i,\quad i=1,2 μ~i=ni1j=1∑niyij=ni1j=1∑niwTxij=wTμi,i=1,2
s ~ i 2 = 1 n i − 1 ∑ j = 1 n i ( y i j − μ ~ i ) 2 = 1 n i − 1 ∑ j = 1 n i ( w T ( x i j − μ i ) ) 2 = w T s i 2 w , i = 1 , 2 \tilde{s}_i^2=\frac{1}{n_i-1}\sum_{j=1}^{n_i}(y_i^j-\tilde{\mu}_i)^2=\frac{1}{n_i-1}\sum_{j=1}^{n_i}(w^T(x_i^j-\mu_i))^2=w^Ts_i^2w,\quad i=1,2 s~i2=ni−11j=1∑ni(yij−μ~i)2=ni−11j=1∑ni(wT(xij−μi))2=wTsi2w,i=1,2
我们希望投影后两类样例中心尽量地分离,即
max ∣ μ 1 ~ − μ 2 ~ ∣ = max ∣ w T ( μ 1 − μ 2 ) ∣ \max \quad|\tilde{\mu_1}-\tilde{\mu_2}|=\max \quad|w^T(\mu_1-\mu_2)| max∣μ1~−μ2~∣=max∣wT(μ1−μ2)∣
同时,我们希望投影后类内部方差 s ~ i 2 \tilde{s}_i^2 s~i2越小越好,于是,得到目标函数,
max w J ( w ) = ∣ μ 1 ~ − μ 2 ~ ∣ 2 s ~ 1 2 + s ~ 2 2 = w T ( μ 1 − μ 2 ) ( μ 1 − μ 2 ) T w w T ( s 1 2 + s 2 2 ) w \max_{w} \quad J(w)=\frac{|\tilde{\mu_1}-\tilde{\mu_2}|^2}{\tilde{s}_1^2+\tilde{s}_2^2}=\frac{w^T(\mu_1-\mu_2)(\mu_1-\mu_2)^Tw}{w^T(s_1^2+s_2^2)w} wmaxJ(w)=s~12+s~22∣μ1~−μ2~∣2=wT(s12+s22)wwT(μ1−μ2)(μ1−μ2)Tw
定义类间散度矩阵 S b S_b Sb及类内散度矩阵 S w S_w Sw如下,
S w = ∑ i = 1 2 ∑ j = 1 n i ( x i j − μ i ) ( x i j − μ i ) T S_w=\sum_{i=1}^2\sum_{j=1}^{n_i}(x_i^j-\mu_i)(x_i^j-\mu_i)^T Sw=i=1∑2j=1∑ni(xij−μi)(xij−μi)T
S b = ( μ 1 − μ 2 ) ( μ 1 − μ 2 ) T S_b=(\mu_1-\mu_2)(\mu_1-\mu_2)^T Sb=(μ1−μ2)(μ1−μ2)T
则可写目标函数,
max w J ( w ) = w T S b w w T S w w \max_{w} \quad J(w)=\frac{w^TS_bw}{w^TS_ww} wmaxJ(w)=wTSwwwTSbw
最大化 J ( w ) J(w) J(w)只需对 w w w求偏导,并令导数等于0,即令分子为0,
( w T S w w ) S b w = ( w T S b w ) S w w (w^TS_ww)S_bw=(w^TS_bw)S_ww (wTSww)Sbw=(wTSbw)Sww
记 λ = w T S b w w T S w w \lambda=\frac{w^TS_bw}{w^TS_ww} λ=wTSwwwTSbw,这是最优目标函数值,一个常数,带入上式得到,
S b w = λ S w w S_bw=\lambda S_ww Sbw=λSww
S w S_w Sw是协方差阵,可逆,两边左乘 S w − 1 S_w^{-1} Sw−1,
S w − 1 S b w = λ w S_w^{-1}S_bw=\lambda w Sw−1Sbw=λw
至此,我们得到,最大化的目标对应了矩阵的最大特征值,而投影方向就是这个特征值对应的特征向量。
情形二: C > 2 C>2 C>2
数据集不只两个类别,降一维已经不能满足分类要求,需要 k k k个基向量来做投影, W = ( w 1 , w 2 , . . . , w k ) W=(w_1,w_2,...,w_k) W=(w1,w2,...,wk),其中 w i w_i wi是 p p p维列向量,记样本 x x x在这组基上投影的结果为 y = ( y 1 , y 2 , . . . , y k ) y=(y_1,y_2,...,y_k) y=(y1,y2,...,yk),
y i = w i T x , y = W T x y_i=w_i^Tx,\quad y=W^Tx yi=wiTx,y=WTx
类似地,可以定义,
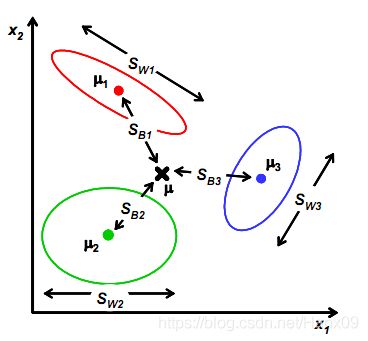
- 类间散度矩阵
S b = ∑ i = 1 C n i ( μ i − μ ) ( μ i − μ ) T S_b=\sum_{i=1}^Cn_i(\mu_i-\mu)(\mu_i-\mu)^T Sb=i=1∑Cni(μi−μ)(μi−μ)T - 类内散度矩阵
S w = ∑ i = 1 C S w i , S w i = ∑ x ∈ D i ( x − μ i ) ( x − μ i ) T S_w=\sum_{i=1}^C S_{w_i},\quad S_{w_i}=\sum_{x\in D_i}(x-\mu_i)(x-\mu_i)^T Sw=i=1∑CSwi,Swi=x∈Di∑(x−μi)(x−μi)T - 全局散度矩阵
S t = S b + S w = ∑ i = 1 n ( x i − μ ) ( x i − μ ) T S_t=S_b+S_w=\sum_{i=1}^n (x_i-\mu)(x_i-\mu)^T St=Sb+Sw=i=1∑n(xi−μ)(xi−μ)T
多分类LDA有多种实现方法:采用 S b , S w , S t S_b,S_w,S_t Sb,Sw,St中的任意两个。
例如:
max w t r ( W T S b W ) t r ( W T S w W ) ⟹ S b W = λ S w W \max_w \frac{tr(W^TS_bW)}{tr(W^TS_wW)}\Longrightarrow S_bW=\lambda S_w W wmaxtr(WTSwW)tr(WTSbW)⟹SbW=λSwW
参考:
线性判别分析LDA详解