深度学习基础学习-RNN与LTSM、GRU
最近看文献看到了LTSM(Long Short Term Memory)相关的文献,所以把了解到的内容做一个记录
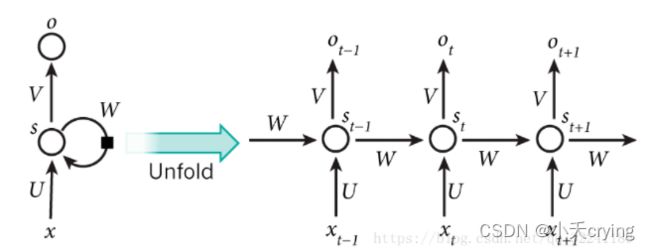
RNN
循环神经网络(Recurrent Neural Network, RNN),以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)。
因为与时间序列相关,所以多用于自然语言处理、语音识别、机器翻译等领域
1、RNN的结构
RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
其实简单来看RNN,RNN一共有三层,输入层、隐藏层,输出层

我们主要在隐藏层进行数据的循环更新
具体来看这其中的隐藏层

- x1、x2、x3对应不同的t时刻,或者说是对应的时间序列对应的样本
- h1、h2、h3、h4是隐藏层状态,表示样本在时间t处的的记忆,隐藏状态可以理解为: h=f(现有的输入+过去记忆总结)
- y1、y2、y3、y4是输出
以计算第一个隐藏层为例子
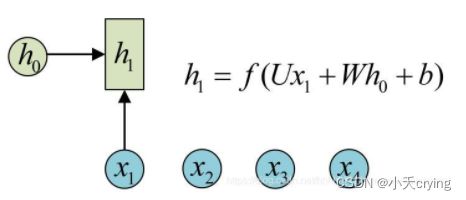
输入x1,引入了U、W两个权重,加上一个偏置b,得到隐藏层状态h1

再进行加权V与偏置c送入激活函数即可得到我们的输出y1
ps:这里的权重W、U、V都是共享权重的
基于RNN的前向传播与梯度反传这里就不做记录了,相关问题可以查阅一下其他资料
LSTM
长短期记忆神经网络(Long Short Term Memory,LSTM),他是循环神经网络RNN的一种特殊存在,它是具有记忆长短期信息的能力的神经网络,是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。LSTM循环网络除了外部的RNN循环外,还具有内部的LSTM细胞循环(自环)
这里首先要引入长期依赖(Long Term Dependencies)的问题和梯度消失、梯度爆炸的问题
长期依赖(Long Term Dependencies)
在深度学习领域中(尤其是RNN),“长期依赖“问题是普遍存在的。长期依赖产生的原因是当神经网络的节点经过许多阶段的计算后,之前比较长的时间片的特征已经被覆盖。
梯度消失、梯度爆炸
梯度消失和梯度爆炸是困扰RNN模型训练的关键原因之一,产生梯度消失和梯度爆炸是由于RNN的权值矩阵循环相乘导致的,相同函数的多次组合会导致极端的非线性行为。梯度消失和梯度爆炸主要存在RNN中,因为RNN中每个时间片使用相同的权值矩阵。
处理梯度爆炸可以采用梯度截断的方法。所谓梯度截断是指将梯度值超过阈值的梯度手动降到其阈值。虽然梯度截断会一定程度上改变梯度的方向,但梯度截断的方向依旧是朝向损失函数减小的方向。
对比梯度爆炸,梯度消失不能简单的通过类似梯度截断的阈值式方法来解决,因为长期依赖的现象也会产生很小的梯度。很明显,如果我们刻意提高小梯度的值将会使模型失去捕捉长期依赖的能力。
基于上述的问题,LTSM通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力。
传统的RNN节点输出仅由权值,偏置以及激活函数决定。RNN是一个链式结构,每个时间片使用的是相同的参数。
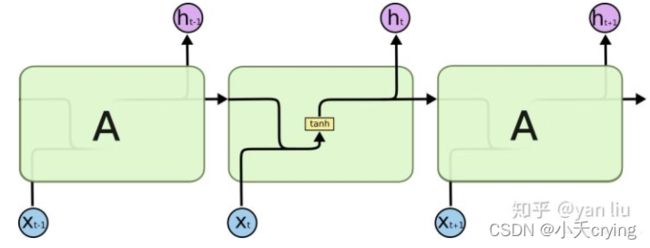
LSTM之所以能够解决RNN的长期依赖问题,是因为LSTM引入了门(gate)机制用于控制特征的流通和损失(如同下面要讲的LSTM的结构)。
1、LSTM结构
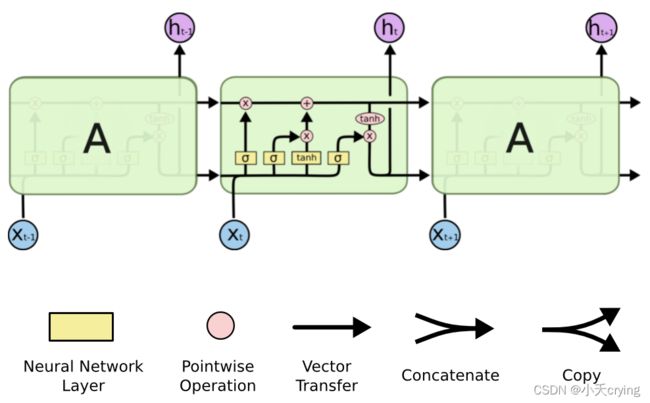
上图的第二排表示操作
- 每个黄色方框表示一个神经网络层,由权值,偏置以及激活函数组成;
- 每个粉色圆圈表示元素级别操作;
- 箭头表示向量流向
- 相交的箭头表示向量的拼接;
- 分叉的箭头表示向量的复制
上述黄色部分具体说明一下,不同的神经网络层,标注了不同的激活函数

- σ表示sigmoid函数,它的输出是在0到1之间的
- t a n h tanh tanh是双曲正切函数,它的输出在-1到1之间
LSTM是由一系列LSTM单元(LSTM Unit)组成,相比于原始的RNN的隐藏层(hidden state), LSTM增加了一个细胞状态(cell state)或者是单元状态,他在单元的最上面那条线进行更新。

LSTM区别于RNN的地方,主要就在于它在算法中加入了一个判断信息有用与否的“处理器”,这个处理器作用的结构被称为cell。
一个cell当中被放置了三扇门,分别叫做输入门、遗忘门和输出门。一个信息进入LSTM的网络当中,可以根据规则来判断是否有用。只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘。通过不同的门来保护和控制细胞状态。
其中一个时刻的输入输出及相关状态可以见下图

- 输入:t时刻的样本xt 、前一时刻的隐藏层状态ht-1 、前一时刻的单元状态ct-1
- 输出:t时刻的隐藏层状态ht 、t时刻的单元状态ct
接下来逐层介绍
(1)遗忘门(决定丢弃信息)
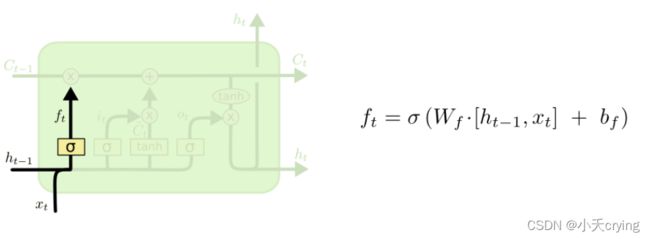
f t f t ft叫做遗忘门,表示 C t − 1 Ct-1 Ct−1的哪些特征被用于计算 C t Ct Ct
这一块的输入是 x t x t xt和 h t − 1 ht-1 ht−1拼接的向量,将输入送给 s g m o i sgmoi sgmoid函数
这里单独说一下 s g m o i d sgmoid sgmoid函数的作用
sgmoid层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。当你观察一个训练好的LSTM时,你会发现门的值绝大多数都非常接近0或者1,其余的值少之又少,这里的0 代表“不许任何量通过”,1 就指“允许任意量通过”。
将经过 s g m o i d sgmoid sgmoid的输出 f t f t ft与 C t − 1 Ct-1 Ct−1相乘即可做到信息的“遗忘”
(2)输入门(确定更新的信息及输出层的输入)
这个门分为两个部分
1)状态更新值的计算
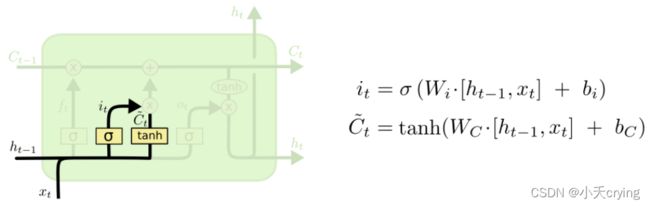
这里的 i t it it和 f t ft ft的使用方式一样,用于控制 C t ′ Ct' Ct′的哪些特征用于更新 C t Ct Ct
t a n h tanh tanh这个激活函数将内容归一化到-1到1
2)确定更新后的输入信息
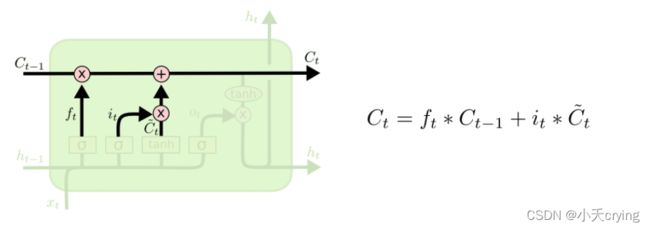
通过上一步的计算得到 i t it it与 C t ′ Ct' Ct′相乘的结果,这个过程确定了“遗忘”和保留的信息
通过遗忘门的输出 f t f t ft与 C t − 1 Ct-1 Ct−1相乘的结果,也确定了这一步“遗忘”和保留的信息
最后,将上述两个结果进行相加,得到了单元状态的更新 C t Ct Ct,也就是t时刻输出的输入值
(3)输出门(输出信息)
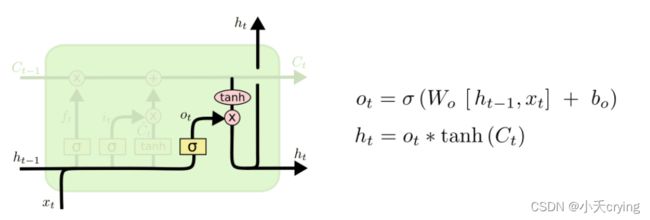
h t ht ht 由输出门 o t ot ot和单元状态 C t Ct Ct经过 t a n h tanh tanh归一化到[-1,1]后的结果相乘 得到
其中 o t ot ot的计算方式和 f t ft ft以及 i t it it 相同
至此一个单元的全过程介绍完毕,这部分参照了LSTM 详解
总的来说,长短期记忆网络LSTM是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。LSTM是使用RNN的一个飞跃。LSTM算法在人工智能之机器学习、翻译语言、控制机器人、图像分析、文档摘要、语音识别、图像识别、手写识别、控制聊天机器人、预测疾病、点击率和股票、合成音乐等领域有着广泛应用。
GRU
门控循环神经网络GRU(Gate Recurrent Unit)是循环神经网络的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
其实GRU在设计上是借鉴了LSTM的,LSTM在1997年提出,而GRU在2014年提出,思想上肯定有相同的。
1、GRU的输入输出结构

输入:t时刻的输入xt,和t-1时刻的隐藏层状态ht-1 ,这个隐藏层状态包含了之前节点的相关信息。也就是之前阶段的“记忆”
输出:t时刻隐藏节点的输出yt和传递给下一个节点的隐状态ht
详细结构如下


是Hadamard Product,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。
![[公式]](http://img.e-com-net.com/image/info8/e59c65c2f21649f69b3c1ea9ae1c9991.jpg)
则代表进行矩阵加法操作。
2、GRU单元
接下来也是针对GRU单元进行分析,与LSTM相似,GRU也是通过门控制来对信息进行过滤,但参数更少,也节省了更多的时间
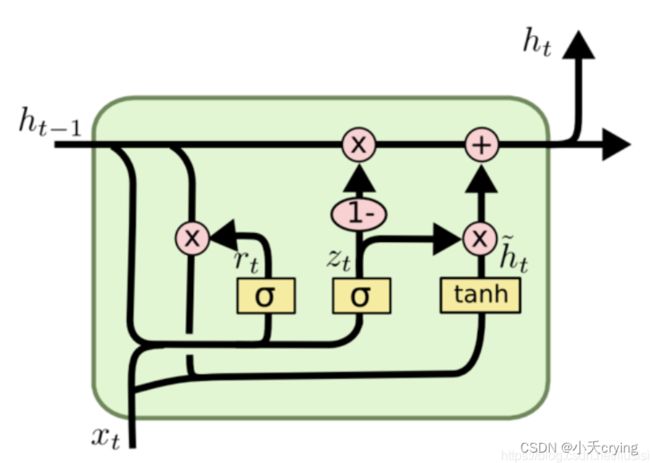

- σ表示sigmoid函数,它的输出是在0到1之间的
- t a n h tanh tanh是双曲正切函数,它的输出在-1到1之间
类比LSTM有三个门,而GRU有两个门
去掉了细胞单元Ct
输出的时候取消了二阶的非线性函数
里面应用到的公式


其中 r r r为控制重置的门控(reset gate), z z z为控制更新的门控(update gate)
这两个门控状态是通过上一个传输下来的状态 h t − 1 ht-1 ht−1,和当前节点的输入 x t xt xt来获取的
(1)重置门(更新候选隐藏状态)
其实和LSTM中的遗忘门类似,也是决定信息中有多少遗忘的部分,然后进行一个候选隐藏状态 h t ′ ht' ht′的更新
1)首先我们获取重置门控信号 r t rt rt,这里的范围是(0,1),方面后面信息的遗忘
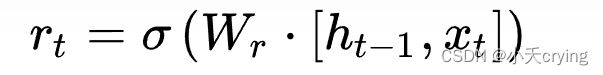
Wr 是权重矩阵
2)得到门控信号后,先通过重置门控得到重置之后的数据,也就是

这里通过上一步获取的[0,1]的 r t rt rt与前一时刻的 h t − 1 ht-1 ht−1相乘,达到了数据重置的目的
3)再将上一步得到的结果与 x t xt xt进行拼接,通过tanh激活函数得到(-1,1)的结果,进而得到 h t ht ht~

对应上面的详细图来看会直观一些
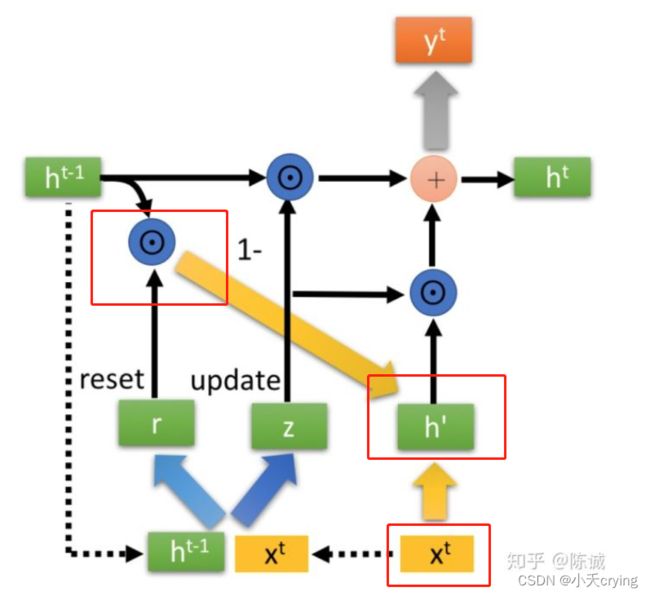

- r t rt rt的范围是(0,1)
- 当 r t rt rt趋近于零的时候,模型会把过去隐藏信息丢弃,只留下当前输入的信息。
- 当 r t rt rt趋近于1的时候,认为过去的信息都有作用,并将其添加到当前信息中。
- 这里的 h ′ h' h′包含了当前输入的 x t xt xt和针对性的对t-1时刻的隐藏层状态 h t − 1 ht-1 ht−1进行了保留
(2)更新门(更新最终隐藏状态)
更新最终的隐藏状态 h t ht ht
1)获取更新门控信号 h t ht ht

其实和 r t rt rt功能一样,输出的范围是(0,1),方便后面信息保存于遗忘,门控信号越接近1,代表”记忆“下来的数据越多;而越接近0则代表”遗忘“的越多。
2)更新更新最终隐藏状态 h t ht ht

GRU很聪明的一点就在于,我们使用了同一个门控 z t zt zt就同时可以进行遗忘和选择记忆(LSTM则要使用多个门控)。
接下来具体分析一下这个公式
-
第一项

表示对原本隐藏状态的选择性“遗忘”。
z t zt zt的范围是(0,1),那么 1 − z 1-z 1−z的范围也是(0,1),那么这里的 1 − z 1-z 1−z也可以想象成遗忘门,与上一时刻的隐藏层状态 h t − 1 ht-1 ht−1相乘,可以对上一时刻的隐藏层状态 h t − 1 ht-1 ht−1信息选择性进行遗忘。 -
第二项

z z z的范围仍然是(0,1),与第一步的候选隐藏状态 h t ′ ht' ht′相乘,表示对候选隐藏状态 h t ′ ht' ht′进行一个数据的选择性遗忘。

-
综合
结合上述,这一步的操作就是忘记传递下来的 t-1时刻 中的某些维度信息,并加入当前节点输入的某些维度信息。
另外想说的一点,这里的两个“用来遗忘的” z z z和 1 − z 1-z 1−z他们是相关的,可以理解成一个权重互补的状态,一遍保持一个恒定的状态
最终综合而成,形成了最后最终隐藏状态的更新