使用Flink的各种技术实现WordCount逻辑
使用Flink的各种技术实现WordCount逻辑
在大数据程序中,WordCount程序实现了统计词频的作用,这个WordCount程序也往往在大数据分析处理中一直占着非常重要的地位。统计一天内某网站的访问次数,需要对网站排序后求其词频,统计一段时间内某个用户的登陆次数,也是对网站用户分组后的词频计算.....等等,很多的大数据应用示例都是在WordCount的基础之上进行改良发展,最终实现大数据分析的关键逻辑。
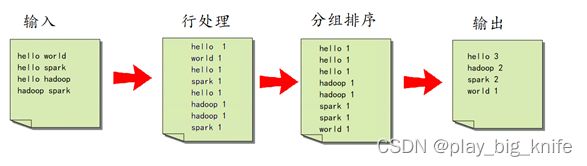
对于wordcount程序来说,基本思想在于输入文件中有每行的英文单词组成的句子,通过行处理的思想,将每个句子的英文单词分割出来,以(单词,1)这种key-value的形式来计数,再通过分组排序,将相同的单词放在一组,最后对每组的单词进行汇总统计。其思想流程图如下图所示。
对于wordcount程序的处理框架,Flink提供了不同级别的编程抽象,通过调用抽象的数据集调用算子构建DataFlow就可以实现对分布式的数据进行流式计算和离线计算,DataSet是批处理的抽象数据集,DataStream是流式计算的抽象数据集,他们的方法都分别为Source、Transformation、Sink
Source主要负责数据的读取
Transformation主要负责对数据的转换操作
Sink负责最终计算好的结果数据输出。
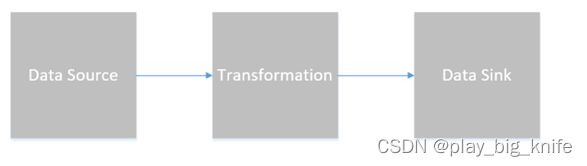
Source读取词频文件的数据,通过Transformation的转换操作将文件中的英文句子切分单词,并分组统计,最终可以Sink到控制台中输出结果。flink的思想结构如下图。
根据这种思想结构,结合不同的Transformation转换函数,常用算子如:
map算子对一个DataStream中的每个元素使用用户自定义的map函数进行处理,每个输入元素对应一个输出元素,最终整个数据流被转换成一个新的DataStream。输入每一个句子,就可以通过map后的函数split空格,然后返回形如(单词,1)的新数据流DataStream。
FlatMap只要处理处理一个输入元素,通过后面的函数可以实现输出一个或者多个输出元素的时候,尤其表现在输出一个元素,如wordcount中输出形如(单词,1)的这种元组类型的元素。就可以用到flatMap()。
reduce方法可以对分组后的元素进行统计处理。
当然, wordcount 也可以结合到不同的情况中。如滑动窗口内的wordcount,就需要结合SlidingWindow。
下面就结合不同情况下使用Flink实现wordCount的词频计算。
一、第一种情况:读取words.txt文件通过flink进行流式分析。
这里需要用到DataStream的Source源DataStreamSource.步骤如下。
1、打开Intellij IDEA,然后点击FIle-->New-->project。

2、打开Project对话框后,左边点击maven,右边不需要点击,只要确认jdk的版本,然后Next进入下一步。
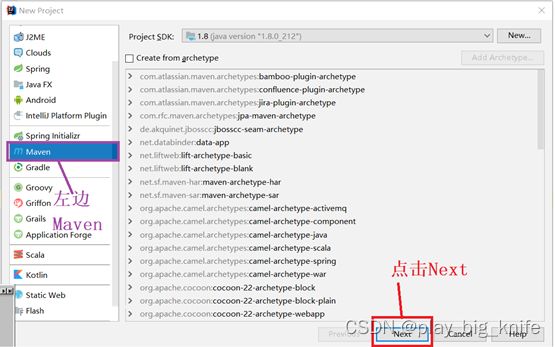
3、在弹出的对话框中,输入groupId和artifactId,然后继续点击Next进入下一步。
4、最后Finish结束配置。
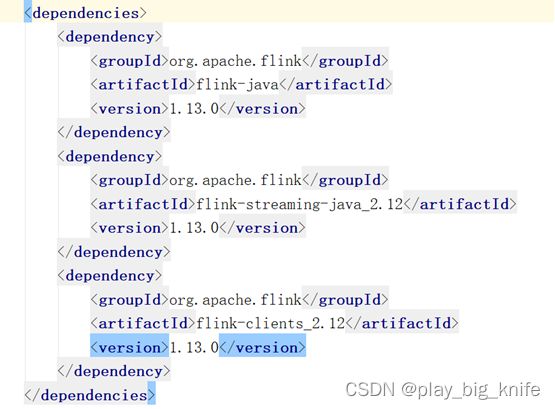
5、在pom.xml中设置dependency的依赖包。
6、建立flink的streaming流式wordcount程序。
注意在敲程序时,设定lambda表达式,方式如下
File -----> Project Structure...
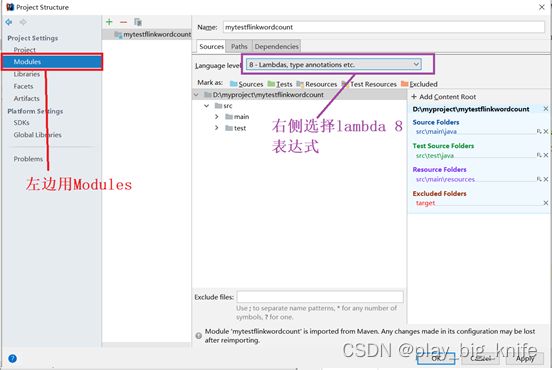
在弹出的对话框中,左边选择Modules,右边选择Lambda表达式8,如下图所示。
最终代码如下。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import org.apache.flink.api.common.typeinfo.Types;
public class MyWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource lineds=env.readTextFile("f://data//words.txt");
SingleOutputStreamOperator> wordstream=lineds.flatMap
((String line, Collector> out)->{
String[] words=line.split(" ");
for(String word:words){
out.collect(Tuple2.of(word,1L));
}
}).returns(Types.TUPLE(Types.STRING,Types.LONG));
KeyedStream,String> groupds=wordstream.keyBy(ds->ds.f0);
groupds.sum(1).print();
env.execute();
}
}
程序中读取硬盘中的words.txt文件,运行后的输出结果如下图。
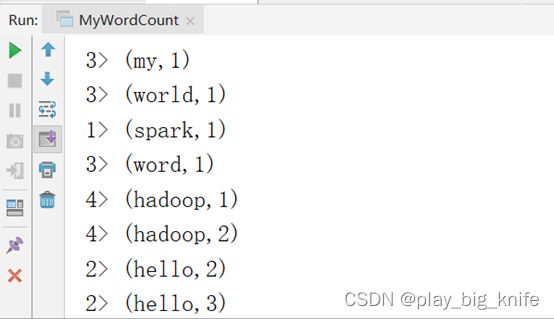
前面就是线程号,后面进行wordcount词频的统计。
二、第二种情况,通过flink对words.txt完成批处理的分析。
这里需要使用Data的数据源Source。其它步骤与前面的DataStreamSource数据源的项目创建步骤一致,这里直接上代码。
程序如下。
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class YouWordCount {
public static void main(String[] args) throws Exception{
ExecutionEnvironment env=ExecutionEnvironment.getExecutionEnvironment();
DataSource lineds=env.readTextFile("f://data//words.txt");
FlatMapOperator> wordds=lineds.flatMap((String line,Collector> out)->{
String[] words=line.split(" ");
for(String word:words){
out.collect(Tuple2.of(word,1L));
}
});
UnsortedGrouping> groupds=wordds.groupBy(0);
AggregateOperator> result=groupds.sum(1);
result.print();
}
}
三、第三种情况:Flink收集流数据的word来计算词频
Wordcount不但可以收集硬盘上的文件,还可以收集linux中的实时流。使用linux系统的 nc 指令提供实时流,命令如下:
nc -l 9000
后面的9000是流传输的端口号,用flink来监控linux中的实时流。
代码如下。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class HeWordCount {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource lineds=env.socketTextStream("192.168.110.156",9000);
lineds.flatMap((String line,Collector> out)->{
String[] words=line.split(" ");
for(String word:words){
out.collect(Tuple2.of(word,1L));
}
}).keyBy(ds->ds.f0).sum(1).print();
env.execute();
}
}
四、Flink对实时流的Wordcount使用滚动窗口
这里使用Flink程序对实时流可以使用滚动窗口计算5秒内的英文词频。
谈到滚动窗口,不免需要说到Flink中的窗口。
Flink按照时间生成Window,可以根据窗口实现原理的不同分成三类。
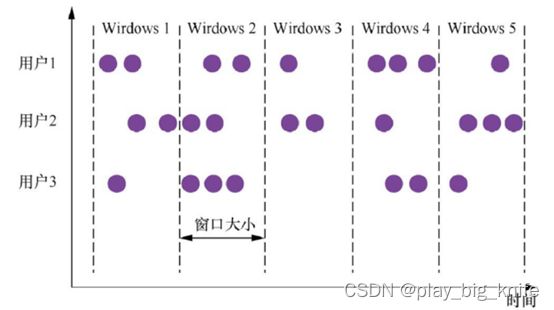
1、滚动窗口(Tumbling Window)
滚动窗口是将数据依据固定的窗口⻓度对数据进行切片。
滚动窗口的特点是:时间对⻬、窗口⻓度固定,并且没有重叠。
滚动窗口中有分配器,分配器会将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。
其原理图如下。
2、滑动窗口(Sliding Window)
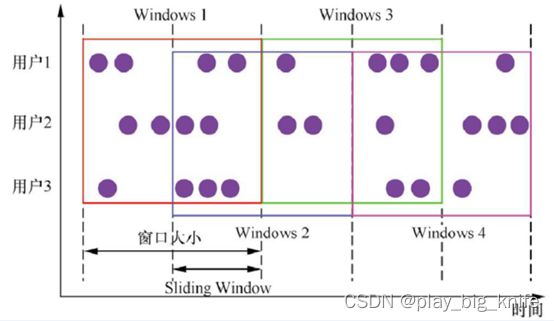
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口⻓度和滑动间隔组成。
滑动窗口的特点是:时间对⻬、窗口⻓度固定,并且有重叠。
滑动窗口中也有分配器,这个分配器将元素分配到固定⻓度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率,因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。
其原理图如下图。

3、会话窗口(Session Window)
会话窗口是由一系列事件组合一个指定时间⻓度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
会话窗口的特点是时间无对⻬。
会话也叫session,会话窗口中也有分配器,session窗口分配器通过session活动来对元素进行分组,session窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。
一个session窗口通过一个session间隔来配置,这个session间隔定义了非活跃周期的⻓度。
当这个非活跃周期产生,那么当前的session将关闭并且后续的元素将被分配到新的session窗口中去。
其原理图如下所示。
图中看出,时间是不对齐的。
这个案例中使用时间对齐不重叠的滚动窗口。
代码如下。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class HeWordCount {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource lineds=env.socketTextStream("192.168.110.156",9000);
lineds.flatMap((String line,Collector> out)->{
String[] words=line.split(" ");
for(String word:words){
out.collect(Tuple2.of(word,1L));
}
}).returns(Types.TUPLE(Types.STRING,Types.LONG))
.keyBy(ds->ds.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1)
.print();
env.execute();
}
}
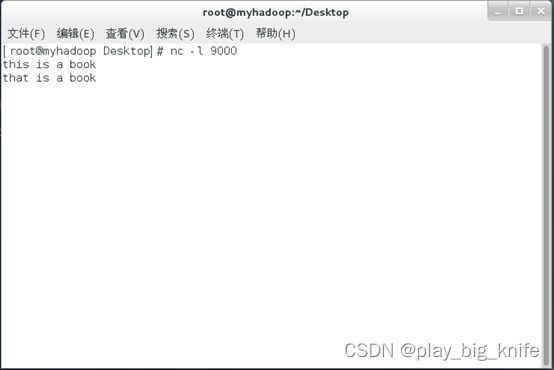
启动linux虚拟机,在进行nc -l 9000,wordcount程序会统计实时的计算词频的数据流。
在linux中启动nc命令后输入内容如下图所示。
运行程序后的结果如下图所示。

五、使用flink SQL来实现5秒内的wordcount词频。
flink sql相当于使用了sql语句来实现5秒内的wordcount词频统计。
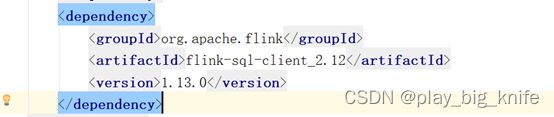
使用flink SQL需要使用flink-sql的依赖。
在程序实现上,使用flink-SQL实现5秒内的wordcount词频代码如下 。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import org.apache.flink.table.api.Table;
import static org.apache.flink.table.api.Expressions.$;
import org.apache.flink.api.common.typeinfo.Types;
public class SheWordCount {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings=EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv=StreamTableEnvironment.create(env,settings);
DataStreamSource lineds=env.readTextFile("f://data//words.txt");
SingleOutputStreamOperator> wordStream=lineds.flatMap
((String line,Collector> out)->{
String[] words=line.split(" ");
for(String word:words){
out.collect(Tuple2.of(word,1L));
}
}).returns(Types.TUPLE(Types.STRING,Types.LONG));
Table table=tableEnv.fromDataStream(wordStream,$("word"),$("count"));
Table result=table.groupBy($("word"))
.select($("word"),$("count").sum());
tableEnv.toRetractStream(result,Types.TUPLE(Types.STRING,Types.LONG)).print();
env.execute();
}
}
至此,使用Flink在各种情况下计算wordcount词频统计基本介绍完毕,
github地址:
https://github.com/wawacode/flink_wordcount