混合注意力机制(CABM-keras代码复现)
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息注意力机制就是一种加权。
通俗讲,注意力机制就是希望网络能够自动学出来图片或者文字序列中的需要注意的地方。
卷积是是一个线性的过程,为了增加非线性特征,加入了池化层和激活层。这个过程是一系列矩阵乘法和元素对应非线性乘法,特征元素用过加法相互作用。
注意力机制加入了对应元素相乘,可以加大特征的非线性,而且简化了其他运算。
注意力机制可以分为:
- 通道注意力机制:对通道生成掩码mask,进行打分,代表是senet, Channel Attention Module
- 空间注意力机制:对空间进行掩码的生成,进行打分,代表是Spatial Attention Module
- 混合域注意力机制:同时对通道注意力和空间注意力进行评价打分,代表的有BAM, CBAM
(1)空间注意力
对输入的特征图分别从通道维度进行求平均和求最大,合并得到一个通道数为2的卷积层,然后通过一个卷积,得到了一个通道数为1的spatial attention,最后将特征图和spatial attention相乘。

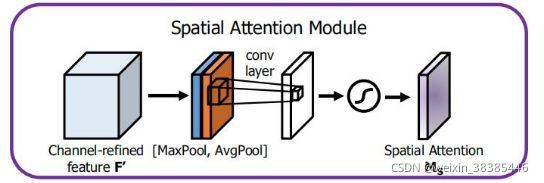
理论上这个模块可以插到任意层,但是由于该模块是所有通道共用一个转换矩阵,实际上只在输入图像后才有意义,卷积后每个卷积核所产生的信息是不同的。
(2)通道注意力
特征图(H*W*C)分别同时做全局平均池化(1*1*C)和全局最大池化(1*1*C),同时输入全连接层,并进行相加(1*1*C),再输入激活函数层(sigmoid),生成权重(1*1*C),最后将权重与特征图(H*W*C)相乘。


(3)混合注意力
CBAM全称是Convolutional Block Attention Module, 是在ECCV2018上发表的注意力机制代表作之一。在该论文中,作者研究了网络架构中的注意力,注意力不仅要告诉我们重点关注哪里,还要提高关注点的表示。 目标是通过使用注意机制来增加表现力,关注重要特征并抑制不必要的特征。为了强调空间和通道这两个维度上的有意义特征,作者依次应用通道和空间注意模块,来分别在通道和空间维度上学习关注什么、在哪里关注。此外,通过了解要强调或抑制的信息也有助于网络内的信息流动。
主要网络架构也很简单,一个是通道注意力模块,另一个是空间注意力模块,CBAM就是先后集成了通道注意力模块和空间注意力模块。

代码的实现:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: mengxie
@software: PyCharm
@file: UNet.py
@time: 2021/9/10
@desc:
"""
import tensorflow as tf
from keras import backend as K
from keras import Model, layers
from keras.applications import vgg16
from keras.layers import Lambda, Activation,Input, Conv2D, Multiply,BatchNormalization, Activation, Reshape, MaxPooling2D, concatenate, UpSampling2D, Dropout,Concatenate,Dense, GlobalAveragePooling2D, GlobalMaxPool2D
#通道注意力(特征, 卷积核个数, 每层名字 )
def channel_attention(input_feature, unit, name, ratio=8):
print("input_feature:", input_feature.shape)
channel = input_feature.get_shape()[-1]
print(channel)
# Channel Attention
avgpool = GlobalAveragePooling2D(name=name+'channel_avgpool')(input_feature) #avg_pool = tf.reduce_mean(input_feature, axis=[1 ,2], keepdims=True)
print("avgpool:", avgpool.shape)
#assert avgpool.get_shape()[1:] == (1, 1, channel)
maxpool = GlobalMaxPool2D(name=name+'channel_maxpool')(input_feature)
#assert maxpool.get_shape()[1:] == (1, 1, channel)
# Shared MLP
Dense_layer1 = Dense(unit//ratio, activation='relu', name=name+'channel_fc1')
Dense_layer2 = Dense(unit, activation='relu', name=name+'channel_fc2')
avg_out = Dense_layer2(Dense_layer1(avgpool))
max_out = Dense_layer2(Dense_layer1(maxpool))
channel = layers.add([avg_out, max_out])
channel = Activation('sigmoid', name=name+'channel_sigmoid')(channel)
channel_scale = Reshape((1, 1, unit), name=name+'channel_reshape')(channel)
channel_out = Multiply()([input_feature, channel_scale])
print("channel_out:", channel_out.shape)
return channel_out
#空间注意力通道(特征, 每层名字,卷积核尺寸 )
def spatial_attention(input_feature, name, kernel_size=7,):
avg_pool = layers.Lambda(lambda x: tf.reduce_mean(x, axis=3, keepdims=True, name=name+'spatial_avgpool'))(input_feature)
assert avg_pool.get_shape()[-1] == 1
max_pool = layers.Lambda(lambda x: tf.reduce_max(x, axis=3, keepdims=True, name= name+'spatial_maxpool'))(input_feature)
assert max_pool.get_shape()[-1] == 1
spatial = concatenate([avg_pool, max_pool], axis=3)
assert spatial.get_shape()[-1] == 2
spatial = Conv2D(1, (kernel_size, kernel_size), strides=1, padding='same', name=name+'spatial_conv2d')(spatial)
spatial_out = Activation('sigmoid', name=name+'spatial_sigmoid')(spatial)
out = Multiply()([input_feature, spatial_out])
return out
#混合注意力机制(CABM)(特征, 卷积核个数, 每层名字 )
def cbam_block(input_feature, unit, name, ratio=8):
"""Contains the implementation of Convolutional Block Attention Module(CBAM) block.
As described in https://arxiv.org/abs/1807.06521.
"""
attention_feature = channel_attention(input_feature, unit, name, ratio)
attention_feature = spatial_attention(attention_feature, name, kernel_size=7)
return attention_feature总结:
空间注意力机制就是通过,一定的方法训练出一个变换空间,用来感受我们的目标位置。并且添加到后续的网络中增加训练效果。
通道注意力也就是通过学习,增强有用特征的占用比。
参考链接:
https://blog.csdn.net/qq_29407397/article/details/105616932 https://blog.csdn.net/qq_29407397/article/details/105616932【CV中的Attention机制】简单而有效的CBAM模块------知乎(非常棒)
https://blog.csdn.net/qq_29407397/article/details/105616932【CV中的Attention机制】简单而有效的CBAM模块------知乎(非常棒)