新加坡国立大学&哈工大提出《Incremental-DETR》,基于自监督学习的增量 Few-Shot 目标检测,性能SOTA!...
关注公众号,发现CV技术之美
本文分享论文『Incremental-DETR: Incremental Few-Shot Object Detection via Self-Supervised Learning』,由新国立&哈工大提出 Incremental-DETR 进行基于自监督学习的增量 Few-Shot 目标检测,性能SOTA!
详细信息如下:

论文链接:https://arxiv.org/abs/2205.04042[1]
项目链接:未开源
01
摘要
增量few-shot目标检测的目的是只需从新类中提取少量标记的训练数据中,在不忘记基类知识的情况下检测出新类。大多数相关的先前工作都是关于增量目标检测的,它依赖于每个新类的丰富训练样本的可用性,这在很大程度上限制了新数据可能稀少的真实环境的可伸缩性。
在本文中,作者提出了增量DETR,它通过在DETR目标检测器上进行微调和自监督学习来进行增量few-shot目标检测。为了缓解新类别数据较少的严重过拟合问题,作者首先通过使用选择性搜索作为伪标签生成的其他object proposals,对DETR的特定类别组件进行自监督。
作者进一步介绍了一种增量的few-shot优化策略,该策略对DETR的类特定组件进行知识提取,以鼓励网络在检测新类时不发生灾难性遗忘。在标准增量目标检测和增量few-shot目标检测设置上进行的大量实验表明,本文的方法显著优于最先进的方法。
02
Motivation
在过去的十年中,由于深度学习的巨大成功,许多的通用目标检测器已经开发出来。然而,大多数基于深度学习的目标检测器只能从训练期间看到的一组固定基类中检测目标。在不损失基类(即目标检测器原始的类)性能的情况下,将目标检测器扩展到其他看不见的新类,需要对来自新类和基类的大量训练数据进行进一步的训练。仅使用来自新类的训练数据进行简单的微调可能会导致灾难性遗忘问题,当来自基类的训练数据不再可用时,基类的知识很快就会被遗忘。
此外,这些基于深度学习的目标检测器还存在严重的过度匹配问题,因为获取大量昂贵且繁琐的带标注的训练数据会变得稀缺。相比之下,人类在不断学习新概念而不忘记先前学习的知识方面比机器要好得多,尽管之前没有示例,而且只有少数新示例可用。人类与机器学习算法之间的这种差距激发了人们对增量few-shot目标检测的兴趣,该算法旨在不断将模型扩展到只有少量样本的新类,而不会忘记基类。
本文主要解决增量few-shot目标检测问题。为此,作者提出了增量DETR,通过在最近提出的DETR目标检测器进行微调以及自监督学习,实现增量few-shot目标检测。本文的灵感来自于few-shot目标检测器中常用的微调技术,该技术基于,带有类无关特征提取器和区域建议网络(RPN)的两阶段Faster R-CNN框架。
在第一阶段,整个网络基于丰富的基础数据进行训练。在第二阶段,类无关特征提取器和RPN被冻结,只有预测头在一个由基本类和新类组成的平衡子集上进行微调。除了使用Faster R-CNN,本文还使用了最先进的DETR目标检测器,该检测器由CNN主干网(从输入图像中提取特征图)、减少特征图通道维数的投影层、将特征图转换为一组对象查询特征的编码器-解码器Transformer、充当回归头的三层前馈网络,以及作为分类头的线性投影组成。根据基于Faster R-CNN的方法,作者推测DETR的CNN主干、Transformer和回归头是类不可知的。
本文的方法的关键部分是将DETR的类无关和类特定部分的训练分为两个阶段:1) 基础模型预训练和自监督的微调,以及2)增量few-shot微调。具体而言,在第一阶段的第一部分,整个网络是根据来自基类的丰富数据进行预训练的。在第一阶段的下一部分中,作者提出了一种自监督学习方法,以确定类特定的投影层和分类头以及可用的丰富基类数据。在第二阶段,类不可知的CNN主干、Transformer和回归头被冻结。作者仅在几个新类的示例上定义了类特定的投影层和分类头。通过在两个阶段中识别和冻结类不可知组件,可以减轻灾难性遗忘。作者在这两个阶段中对类特定组件的微调缓解了过度匹配问题,同时使网络能够检测新的类目标。
人类可以在基类图像的背景中从先验知识中轻松观察和提取其他有意义的object proposals。基于这一直觉,作者利用选择性搜索算法生成额外的object proposals,这些object proposals可能作为伪ground truth标签存在于背景中,以便在第一阶段确定网络,以检测类别不可知的object proposals。具体而言,作者在类特定投影层和分类头上进行多任务学习,其中生成的伪标签用于自监督模型,同时充分监督丰富的基类数据。这有助于模型在不忘记基类的情况下推广到新类。此外,除了现有的DETR损失外,作者还提出了分类蒸馏损失和mask特征蒸馏损失,用于我们的增量few-shot微调阶段,以阻止灾难性遗忘。
03
方法
Problem Definition
设表示包含图像x及其对应的对象y的ground truth集y的数据集D。我们进一步将基类和新类的训练数据集分别表示为和。定义了类增量学习后,我们只能访问新的类数据,其中y novel∈ {C B+1,…,C B+N}。
基类数据D base,其中不再可访问。和没有重叠的类,即。训练数据集有丰富的标注实例。相比之下,具有的极少标注实例,并且通常被描述为N-way K-shot训练集,其中有N个新类,每个新类具有K个标注对象实例。
Base Model Training
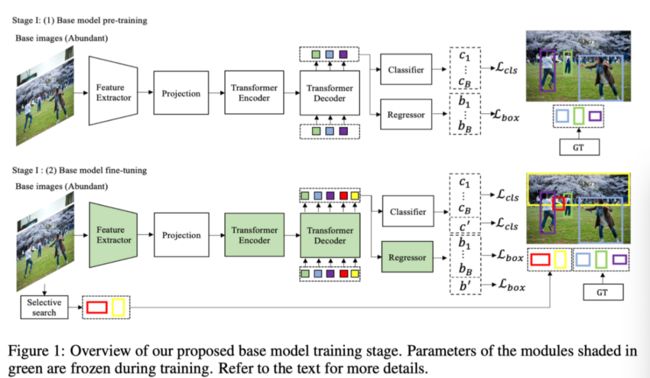
如上图所示,作者将增量DETR的第一阶段分为基础模型预训练和微调。在基本模型预训练中,作者只在基本类上训练整个模型,其损失函数与DETR中使用的损失函数相同。
作者将基类的M个预测集表示为
402 Payment Required
,将目标的ground truth集表示为 ,并填充∅ (无目标)。 对于ground truth集的每个元素i, 是目标类标签(可能是∅ ) , 是一个4-vector,用于定义ground truth边界框中心坐标及其相对于图像大小的高度和宽度。 作者在ground truth 和预测 之间采用成对匹配损失 来搜索b ipartite匹配: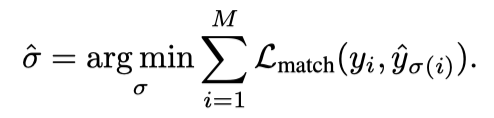
匹配损失同时考虑了类别预测,以及预测和ground truth的相似性。
具体定义如下:
![]()
鉴于上述定义,上一步匹配的所有配对的Hungarian损失定义为:
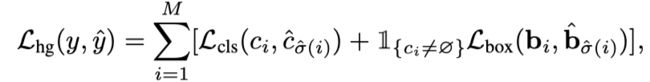
其中表示预测和目标之间的最佳分配。是sigmoid focal loss。是L 1损失和广义IoU损失的线性组合,具有与DETR相同的权重超参数。
为了使DETR的类特定组件的参数能够很好地推广到增量few-shot微调阶段中具有少数样本的新类,我们提粗以自监督的方式对类特定组件进行优化,同时将类不可知组件冻结在第一阶段的基本模型优化中,其中,模型的参数是从预训练的基础模型初始化的。基础模型微调依赖于对基础数据的其他潜在类不可知对象以及基础类的ground truth对象进行预测。
受R-CNN和Fast R-CNN的启发,作者使用选择性搜索算法为每个原始图像生成一组类别无关的object proposals。选择性搜索是一种成熟且非常有效的无监督object proposal生成算法,它使用颜色相似性、纹理相似性等因素来生成object proposal。
然而,object proposal的数量很大,排名也不准确。为了避免这个问题,作者使用选择性搜索算法中的对象排序来删除不精确的object proposal。具体而言,作者选择排名列表中与基类的ground truth对象不重叠的前O个对象作为伪ground truth object proposal。作者将伪ground truth object proposal表示为b′。
为了对这些选定object proposal进行预测,作者按照DETR的预测头那样,为所有选定object proposal引入一个新的类标签c′,作为伪ground truth标签以及基类标签。
设将所选object proposal的伪ground truth集表示为
402 Payment Required
,并填充∅ (无对象),P预测集表示为402 Payment Required
。作者还采用伪ground truth和预测之间的成对匹配损失 来进行二部匹配。最后,所有配对的Hungarian损失定义为:
其中表示预测和伪ground truth之间的最佳分配。是sigmoid focal loss。是L 1损失和广义IoU损失的线性组合,具有与DETR相同的权重超参数。
根据丰富的基础数据,总损失微调base模型的总损失如下所示:

其中是超参数。
Incremental Few-Shot Fine-Tuning
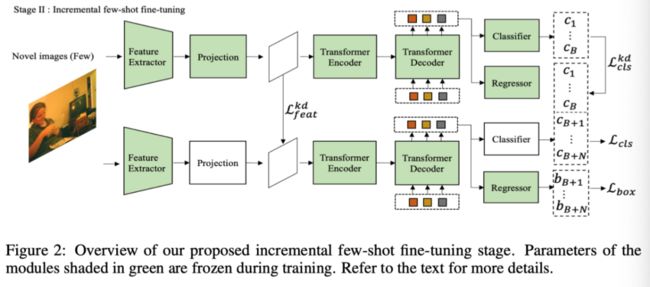
如上图所示,作者首先在第一阶段从微调的base模型初始化新模型的参数,然后使用一些新类的样本来微调类特定的投影层和分类头,同时保持类不可知组件不变。然而,投影层和分类头的不断更新,在新类学习过程中,学习会加剧对基类的灾难性遗忘。因此,作者提出使用知识提炼来缓解灾难性遗忘。
具体而言,base模型用于防止新模型的投影层输出特征与base模型的投影层输出特征偏差过大。然而,在全特征图上直接提取知识会导致冲突,从而影响性能。因此,作者使用新类的ground truth边界框作为二元掩码,以防止从基本模型的特征对新类学习产生负面影响。特征上带mask的蒸馏损失写为:

式中,
402 Payment Required
。 和 分别表示base模型和新模型的特征。w、 h和c是特征的宽度、高度和通道。对于DETR分类头上的知识提取,作者首先从base模型的M个预测输出中选择预测输出作为基本类的伪ground truth。具体而言,对于输入的新图像,当其类概率大于0.5且其边界框与新类的ground truth边界框没有重叠时,作者将base模型的预测输出视为基础类的伪基础ground truth。然后,作者采用成对匹配损失来确定伪ground truth与新模型预测之间的二分匹配。随后,在蒸馏损失函数中比较基本模型和新模型的分类输出,如下所示:
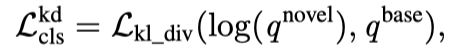
其中,q表示类别概率。
Hungarian损失也适用于ground truth集y和新数据的预测。总损失用于在新数据上训练新模型,如下所示:
![]()
其中和是平衡损失项的超参数。
04
实验

上表显示了一个新增类的增量学习设置的结果。这些结果支持本文的增量学习框架在保留基本类知识和学习新类知识方面的有效性。

表2显示了MS COCO的前40个类作为基类的结果,接下来的40个类作为新类的附加组。这些结果表明,当添加一组新类时,本文提出的方法是有效的。
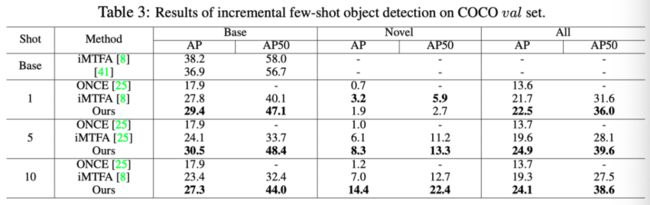
在这个实验中,作者展示了本文的方法在学习检测新类时的有效性,而不忘记只有少量新样本的基类。上表的前两行显示了在基类上训练的MTFA和Deformable DETR的结果,无需使用增量few-shot学习。
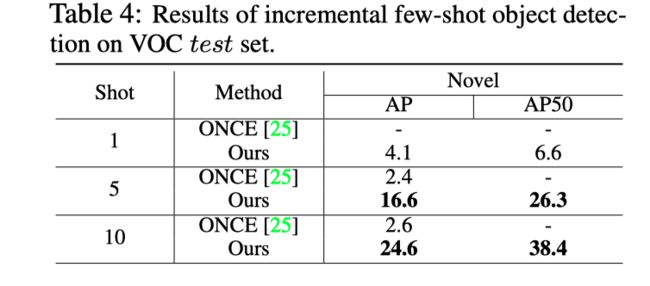
作者报告了在从COCO到VOC的跨数据集中增量few-shot目标检测的性能,以证明本文方法的域适应能力,其中新模型训练数据集的域不同于基础模型训练数据集,结果如上表所示。

上表显示了为了解框架中每个组件的有效性而进行的消融研究。消融组件包括:1)两阶段微调;2) 自监督学习;3) 知识蒸馏。这些结果进一步证明了方法中两阶段微调、自监督学习和知识提取策略的有效性。
05
总结
在本文中,作者提出了一种新的增量few-shot目标检测框架:针对更具挑战性和现实性的场景,在训练数据集中没有来自基类的样本,只有来自新类的少量样本。作者提出使用两阶段微调策略和自监督学习来保留基类的知识,并学习更好的泛化表示。然后,作者利用知识提取策略,使用新类中的少量样本,将知识从基础转移到新模型。在基准数据集上的大量实验结果表明了该方法的有效性。
参考资料
[1]https://arxiv.org/abs/2205.04042

END
欢迎加入「目标检测」交流群备注:OD
