深度学习之学习(3-3)YOLOV2
参见:【目标检测论文阅读】YOLOv2 - 知乎
二、更快更准:YOLOv2
2.1 简介
2017年,作者 Joseph Redmon 和 Ali Farhadi 在 YOLOv1 的基础上,进行了大量改进,提出了 YOLOv2 和 YOLO9000。重点解决YOLOv1召回率和定位精度方面的不足。
YOLOv2 是一个先进的目标检测算法,比其它的检测器检测速度更快。除此之外,该网络可以适应多种尺寸的图片输入,并且能在检测精度和速度之间进行很好的权衡。
相比于YOLOv1是利用全连接层直接预测Bounding Box的坐标,YOLOv2借鉴了Faster R-CNN的思想,引入Anchor机制。利用K-means聚类的方法在训练集中聚类计算出更好的Anchor模板,大大提高了算法的召回率。同时结合图像细粒度特征,将浅层特征与深层特征相连,有助于对小尺寸目标的检测。
YOLO9000 使用 WorldTree 来混合来自不同资源的训练数据,并使用联合优化技术同时在ImageNet和COCO数据集上进行训练,能够实时地检测超过9000种物体。由于 YOLO9000 的主要检测网络还是YOLOv2,所以这部分以讲解应用更为广泛的YOLOv2为主。
2.2 网络结构
YOLOv2 采用 Darknet-19 作为特征提取网络,其整体结构如下: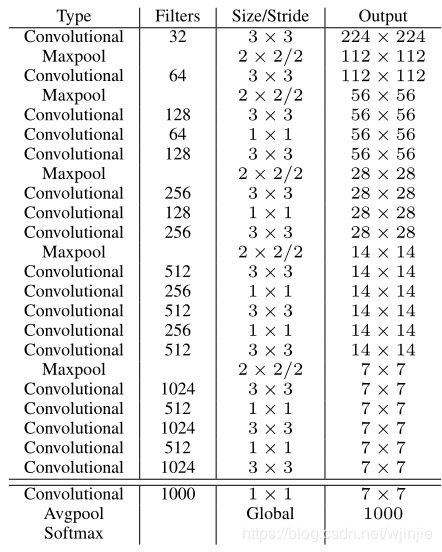
改进后的YOLOv2: Darknet-19,总结如下:
- 与VGG相似,使用了很多3×3卷积核;并且每一次池化后,下一层的卷积核的通道数 = 池化输出的通道 × 2。
- 在每一层卷积后,都增加了批量标准化(Batch Normalization)进行预处理。
- 采用了降维的思想,把1×1的卷积置于3×3之间,用来压缩特征。
- 在网络最后的输出增加了一个global average pooling层。
- 整体上采用了19个卷积层,5个池化层。
注:如果想了解降维的思想,可以戳戳:TF2.0深度学习实战(六):搭建GoogLeNet卷积神经网络,对文章中1×1卷积核降维部分细看。
为了更好的说明,这里我将 Darknet-19 与 YOLOv1、VGG16网络进行对比:
- VGG-16: 大多数检测网络框架都是以VGG-16作为基础特征提取器,它功能强大,准确率高,但是计算复杂度较大,所以速度会相对较慢。因此YOLOv2的网络结构将从这方面进行改进。
- YOLOv1: 基于GoogLeNet的自定义网络(具体看上周报告),比VGG-16的速度快,但是精度稍不如VGG-16。
- Darknet-19: 速度方面,处理一张图片仅需要55.8亿次运算,相比于VGG306.9亿次,速度快了近6倍。精度方面,在ImageNet上的测试精度为:top1准确率为72.9%,top5准确率为91.2%。
2.3 改进方法
(1)Batch Normalization
Batch Normalization 简称 BN ,意思是批量标准化。2015年由 Google 研究员在论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》中提出。
BN 对数据进行预处理(统一格式、均衡化、去噪等)能够大大提高训练速度,提升训练效果。基于此,YOLOv2 对每一层输入的数据都进行批量标准化,这样网络就不需要每层都去学数据的分布,收敛会变得更快。
BN算法实现:
在卷积或池化之后,激活函数之前,对每个数据输出进行标准化,实现方式如下图所示:

如上图所示,前三行是对Batch进行数据归一化(如果一个Batch中有训练集每个数据,那么同一Batch内数据近似代表了整体训练数据),第四行引入了附加参数 γ 和 β,这两个参数的具体取值可以参考上面提到的 Batch Normalization 这篇论文。
想更深入了解 Batch Normalization 的原理和应用,可以参见我的:深度学习理论专栏——Batch Normalization
(2)引入 Anchor Box 机制
在YOLOv1中,作者设计了端对端的网路,直接对边界框的位置(x, y, w, h)进行预测。这样做虽然简单,但是由于没有类似R-CNN系列的推荐区域,所以网络在前期训练时非常困难,很难收敛。于是,自YOLOv2开始,引入了 Anchors box 机制,希望通过提前筛选得到的具有代表性先验框Anchors,使得网络在训练时更容易收敛。
在 Faster R-CNN 算法中,是通过预测 bounding box(已经给定) 与 ground truth 的位置(标定位置)偏移值 ![]() ,间接得到bounding box的位置。其公式如下:
,间接得到bounding box的位置。其公式如下: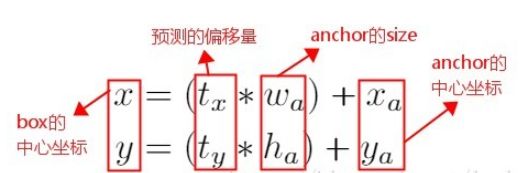
这个公式是无约束的,预测的边界框很容易向任何方向偏移。因此,每个位置预测的边界框可以落在图片任何位置,这会导致模型的不稳定性。
因此 YOLOv2 在此方法上进行了一点改变:预测边界框中心点相对于该网格左上角坐标 (![]() ) 的相对偏移量,同时为了将bounding box的中心点约束在当前网格中,使用 sigmoid 函数将
) 的相对偏移量,同时为了将bounding box的中心点约束在当前网格中,使用 sigmoid 函数将![]() 归一化处理,将值约束在0-1,这使得模型训练更稳定。
归一化处理,将值约束在0-1,这使得模型训练更稳定。
下图为 Anchor box 与 bounding box 转换示意图,其中蓝色的是要预测的bounding box,黑色虚线框是Anchor box。
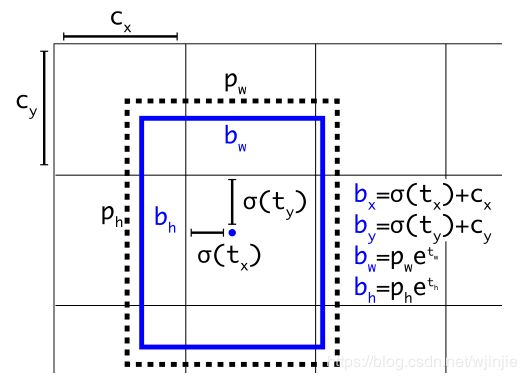
图 3
YOLOv2 在最后一个卷积层输出 13×13 的 feature map,意味着一张(特征)图片被分成了13×13个网格。每个网格有5个anchor box来预测5个bounding box,每个bounding box预测得到5个值:![]() 和
和  (类似YOLOv1的confidence)。引入Anchor Box 机制后,通过间接预测得到的 bounding box 的位置的计算公式为:
(类似YOLOv1的confidence)。引入Anchor Box 机制后,通过间接预测得到的 bounding box 的位置的计算公式为: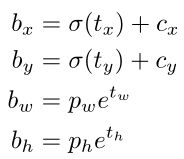
置信度的计算公式为:
其中,![]() 是bbox的中心和宽高,
是bbox的中心和宽高,![]() 是bbox的置信度,YOLOV1是直接预测置信度的值,这里对预测参数进行σ变换后作为置信度的值。(
是bbox的置信度,YOLOV1是直接预测置信度的值,这里对预测参数进行σ变换后作为置信度的值。(![]() )为对应cell的左上角坐标(每个cell归一化大小为1),如图3所示,由于σ(sigmoid)函数的处理,bbox的中心坐标会约束在当前cell内部防止偏移。
)为对应cell的左上角坐标(每个cell归一化大小为1),如图3所示,由于σ(sigmoid)函数的处理,bbox的中心坐标会约束在当前cell内部防止偏移。![]() 是anchor的宽和高(paper中其大小是相对于feature map的)。
是anchor的宽和高(paper中其大小是相对于feature map的)。![]() 和 是要学习的参数,分别用于预测边框的中心和宽高,以及置信度。
和 是要学习的参数,分别用于预测边框的中心和宽高,以及置信度。
在计算时每个cell的尺度为1,所以当前cell的左上角坐标为 (1,1) 。由于sigmoid函数的处理,边界框的中心位置会约束在当前cell内部,防止偏移过多。而 ![]() 是先验框的宽度与长度,前面说过它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。这里记特征图的大小为 (W,H) (在文中是(13,13) ),这样我们可以将边界框相对于整张图片的位置和大小计算出来(4个值均在0和1之间):
是先验框的宽度与长度,前面说过它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。这里记特征图的大小为 (W,H) (在文中是(13,13) ),这样我们可以将边界框相对于整张图片的位置和大小计算出来(4个值均在0和1之间):

如果再将上面的4个值分别乘以图片的宽度和长度(像素点值)就可以得到边界框的最终位置和大小了。这就是YOLOv2边界框的整个解码过程
(3)Convolution With Anchor Boxes

YOLOv1 有一个致命的缺陷就是:一张图片被分成7×7的网格,一个网格只能预测一个类,当一个网格中同时出现多个类时,就无法检测出所有类。针对这个问题,YOLOv2做出了相应的改进:
- 首先将YOLOv1网络的FC层和最后一个Pooling层去掉,使得最后的卷积层的输出可以有更高的分辨率特征。
- 然后缩减网络,用416×416大小的输入代替原来的448×448,使得网络输出的特征图有奇数大小的宽和高,进而使得每个特征图在划分单元格的时候只有一个中心单元格(Center Cell)。YOLOv2通过5个Pooling层进行下采样,得到的输出是13×13的像素特征。
- 借鉴Faster R-CNN,YOLOv2通过引入Anchor Boxes,预测Anchor Box的偏移值与置信度,而不是直接预测坐标值。
- 采用Faster R-CNN中的方式,每个Cell可预测出9个Anchor Box,共13×13×9=1521个(YOLOv2确定Anchor Boxes的方法见是维度聚类,每个Cell选择5个Anchor Box)。比YOLOv1预测的98个bounding box 要多很多,因此在定位精度方面有较好的改善。
(4)聚类方法选择Anchors
Faster R-CNN 中 Anchor Box 的大小和比例是按经验设定的,不具有很好的代表性。若一开始就选择了更好的、更有代表性的先验框Anchor Boxes,那么网络就更容易学到准确的预测位置了!
YOLOv2 使用 K-means 聚类方法得到 Anchor Box 的大小,选择具有代表性的尺寸的Anchor Box进行一开始的初始化。传统的K-means聚类方法使用标准的欧氏距离作为距离度量,这意味着大的box会比小的box产生更多的错误。因此这里使用其他的距离度量公式。聚类的目的是使 Anchor boxes 和临近的 ground truth boxes有更大的IOU值,因此自定义的距离度量公式为 :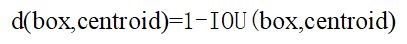
到聚类中心的距离越小越好,但IOU值是越大越好,所以使用 1 - IOU;这样就保证距离越小,IOU值越大。具体实现方法如下:
如下图所示,是论文中的聚类效果,其中紫色和灰色也是分别表示两个不同的数据集,可以看出其基本形状是类似的。
从下表可以看出,YOLOv2采用5种 Anchor 比 Faster R-CNN 采用9种 Anchor 得到的平均 IOU 还略高,并且当 YOLOv2 采用9种时,平均 IOU 有显著提高。说明 K-means 方法的生成的Anchor boxes 更具有代表性。为了权衡精确度和速度的开销,最终选择K=5。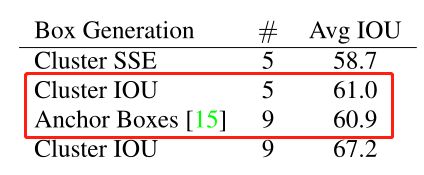
(5)Fine-Grained Features
细粒度特征,可理解为不同层之间的特征融合。YOLOv2通过添加一个Passthrough Layer,把高分辨率的浅层特征连接到低分辨率的深层特征(把特征堆积在不同Channel中)而后进行融合和检测。具体操作是:先获取前层的26×26的特征图,将其同最后输出的13×13的特征图进行连接,而后输入检测器进行检测(而在YOLOv1中网络的FC层起到了全局特征融合的作用),以此来提高对小目标的检测能力。
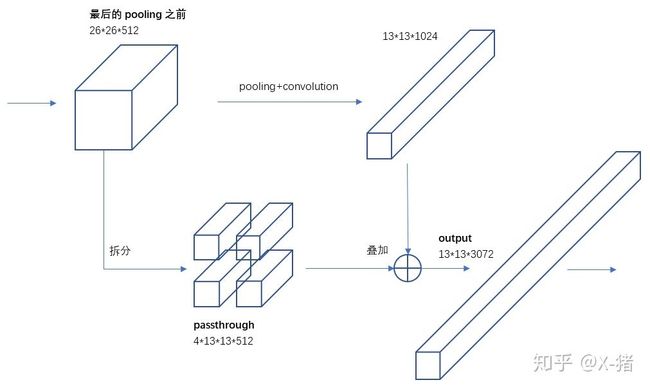
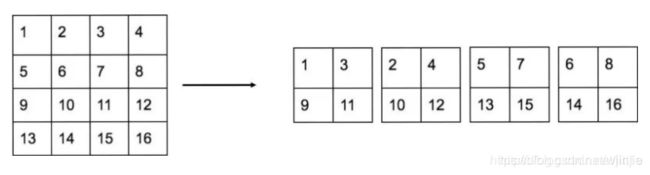
Passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上。前面的特征图维度是后面的特征图的2倍,passthrough层抽取前面层的每个2×2的局部区域,然后将其转化为channel维度,对于26×26×512的特征图,经Passthrough层处理之后就变成了13×13×2048的新特征图(特征图大小降低4倍,而channles增加4倍),这样就可以与后面的13×13×1024特征图连接在一起形成13×13×3072的特征图,然后在此特征图基础上卷积做预测。示意图如下:
(6)Multi-Scale Training
由于YOLOv2模型中只有卷积层和池化层,所以YOLOv2的输入可以不限于 416 X 416 大小的图片。为了增强模型的鲁棒性,YOLOv2采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的iterations之后改变模型的输入图片大小。由于YOLOv2的下采样总步长为32,输入图片大小选择一系列为32倍数的值: {320,352,...608} ,输入图片最小为 320X320 ,此时对应的特征图大小为10 X 10 (不是奇数了,确实有点尴尬),而输入图片最大为 608 X 608 ,对应的特征图大小为19 X 19 。在训练过程,每隔10个iterations随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。

图7:Multi-Scale Training
采用Multi-Scale Training策略,YOLOv2可以适应不同大小的图片,并且预测出很好的结果。在测试时,YOLOv2可以采用不同大小的图片作为输入,在VOC 2007数据集上的效果如下图所示。可以看到采用较小分辨率时,YOLOv2的mAP值略低,但是速度更快,而采用高分辨输入时,mAP值更高,但是速度略有下降,对于 544 X 544 ,mAP高达78.6%。注意,这只是测试时输入图片大小不同,而实际上用的是同一个模型(采用Multi-Scale Training训练)。

图8:YOLOv2在VOC 2007数据集上的性能对比
2.4 性能表现
在VOC2007数据集上进行测试,YOLOv2在速度为67fps时,精度可以达到76.8的mAP;在速度为40fps时,精度可以达到78.6
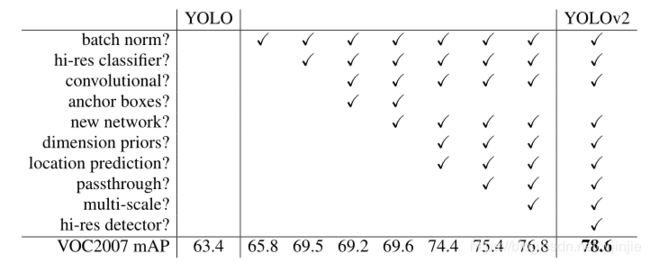
的mAP 。可以很好的在速度和精度之间进行权衡。下图是YOLOv1在加入各种改进方法后,检测性能的改变。可见在经过多种改进方法后,YOLOv2在原基础上检测精度具有很大的提升!
2.5 YOLOv2的训练
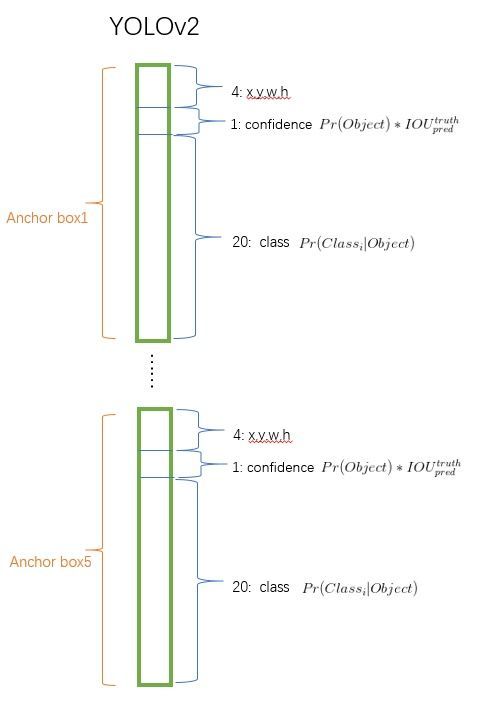
YOLOv2的训练主要包括三个阶段。第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为 224 X 224 ,共训练160个epochs。然后第二阶段将网络的输入调整为448 X 448 ,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。第三个阶段就是修改Darknet-19分类模型为检测模型,并在检测数据集上继续finetune网络。网络修改包括(网路结构可视化):移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个 3X3X2014卷积层,同时增加了一个passthrough层,最后使用1X1 卷积层输出预测结果,输出的channels数为: ![]() ,和训练采用的数据集有关系。由于anchors数为5,对于VOC数据集输出的channels数就是125,而对于COCO数据集则为425。这里以VOC数据集为例,最终的预测矩阵为 T (shape为 (batch_size,13,13,125) ),可以先将其reshape为 (batch_size,13,13,5,25) ,其中
,和训练采用的数据集有关系。由于anchors数为5,对于VOC数据集输出的channels数就是125,而对于COCO数据集则为425。这里以VOC数据集为例,最终的预测矩阵为 T (shape为 (batch_size,13,13,125) ),可以先将其reshape为 (batch_size,13,13,5,25) ,其中![]() 为边界框的位置和大小
为边界框的位置和大小 ![]() ,
, ![]() 为边界框的置信度,而
为边界框的置信度,而 ![]() 为类别预测值。
为类别预测值。

图9:YOLOv2训练的三个阶段

图10:YOLOv2结构示意图
YOLOv2的网络结构以及训练参数我们都知道了,但是貌似少了点东西。仔细一想,原来作者并没有给出YOLOv2的训练过程的两个最重要方面,即先验框匹配(样本选择)以及训练的损失函数,难怪Ng说YOLO论文很难懂,没有这两方面的说明我们确实不知道YOLOv2到底是怎么训练起来的。不过默认按照YOLOv1的处理方式也是可以处理,我看了YOLO在TensorFlow上的实现darkflow(见yolov2/train.py),发现它就是如此处理的:和YOLOv1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的5个先验框所对应的边界框负责预测它,具体是哪个边界框预测它,需要在训练中确定,即由那个与ground truth的IOU最大的边界框预测它,而剩余的4个边界框不与该ground truth匹配。YOLOv2同样需要假定每个cell至多含有一个grounth truth,而在实际上基本不会出现多于1个的情况。与ground truth匹配的先验框计算坐标误差、置信度误差(此时target为1)以及分类误差,而其它的边界框只计算置信度误差(此时target为0)。YOLOv2和YOLOv1的损失函数一样,为均方差函数。
但是我看了YOLOv2的源码(训练样本处理与loss计算都包含在文件region_layer.c中,YOLO源码没有任何注释,反正我看了是直摇头),并且参考国外的blog以及allanzelener/YAD2K(Ng深度学习教程所参考的那个Keras实现)上的实现,发现YOLOv2的处理比原来的v1版本更加复杂。先给出loss计算公式:

我们来一点点解释,首先 W,H 分别指的是特征图(13X13 )的宽与高,而 A指的是先验框数目(这里是5),各个 值是各个loss部分的权重系数。第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。第二项是计算先验框与预测宽的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状。第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。先说一下匹配原则,对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。在计算obj置信度时,target=1,但与YOLOv1一样而增加了一个控制参数rescore,当其为1时,target取预测框与ground truth的真实IOU值(cfg文件中默认采用这种方式)。对于那些没有与ground truth匹配的先验框(与预测框对应),除去那些Max_IOU低于阈值的,其它的就全部忽略,不计算任何误差。这点在YOLOv3论文中也有相关说明:YOLO中一个ground truth只会与一个先验框匹配(IOU值最好的),对于那些IOU值超过一定阈值的先验框,其预测结果就忽略了。这和SSD与RPN网络的处理方式有很大不同,因为它们可以将一个ground truth分配给多个先验框。尽管YOLOv2和YOLOv1计算loss处理上有不同,但都是采用均方差来计算loss。另外需要注意的一点是,在计算boxes的 和 误差时,YOLOv1中采用的是平方根以降低boxes的大小对误差的影响,而YOLOv2是直接计算,但是根据ground truth的大小对权重系数进行修正:l.coord_scale * (2 - truth.w*truth.h)(这里w和h都归一化到(0,1)),这样对于尺度较小的boxes其权重系数会更大一些,可以放大误差,起到和YOLOv1计算平方根相似的效果(参考YOLO v2 损失函数源码分析)。
值是各个loss部分的权重系数。第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。第二项是计算先验框与预测宽的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状。第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。先说一下匹配原则,对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。在计算obj置信度时,target=1,但与YOLOv1一样而增加了一个控制参数rescore,当其为1时,target取预测框与ground truth的真实IOU值(cfg文件中默认采用这种方式)。对于那些没有与ground truth匹配的先验框(与预测框对应),除去那些Max_IOU低于阈值的,其它的就全部忽略,不计算任何误差。这点在YOLOv3论文中也有相关说明:YOLO中一个ground truth只会与一个先验框匹配(IOU值最好的),对于那些IOU值超过一定阈值的先验框,其预测结果就忽略了。这和SSD与RPN网络的处理方式有很大不同,因为它们可以将一个ground truth分配给多个先验框。尽管YOLOv2和YOLOv1计算loss处理上有不同,但都是采用均方差来计算loss。另外需要注意的一点是,在计算boxes的 和 误差时,YOLOv1中采用的是平方根以降低boxes的大小对误差的影响,而YOLOv2是直接计算,但是根据ground truth的大小对权重系数进行修正:l.coord_scale * (2 - truth.w*truth.h)(这里w和h都归一化到(0,1)),这样对于尺度较小的boxes其权重系数会更大一些,可以放大误差,起到和YOLOv1计算平方根相似的效果(参考YOLO v2 损失函数源码分析)。
// box误差函数,计算梯度
float delta_region_box(box truth, float *x, float *biases, int n, int index, int i, int j, int w, int h, float *delta, float scale, int stride)
{
box pred = get_region_box(x, biases, n, index, i, j, w, h, stride);
float iou = box_iou(pred, truth);
// 计算ground truth的offsets值
float tx = (truth.x*w - i);
float ty = (truth.y*h - j);
float tw = log(truth.w*w / biases[2*n]);
float th = log(truth.h*h / biases[2*n + 1]);
delta[index + 0*stride] = scale * (tx - x[index + 0*stride]);
delta[index + 1*stride] = scale * (ty - x[index + 1*stride]);
delta[index + 2*stride] = scale * (tw - x[index + 2*stride]);
delta[index + 3*stride] = scale * (th - x[index + 3*stride]);
return iou;
}最终的YOLOv2模型在速度上比YOLOv1还快(采用了计算量更少的Darknet-19模型),而且模型的准确度比YOLOv1有显著提升,详情见paper。
YOLOv2在TensorFlow上实现
这里参考YOLOv2在Keras上的复现(见yhcc/yolo2),使用TensorFlow实现YOLOv2在COCO数据集上的test过程。首先是定义YOLOv2的主体网络结构Darknet-19:
def darknet(images, n_last_channels=425):
"""Darknet19 for YOLOv2"""
net = conv2d(images, 32, 3, 1, name="conv1")
net = maxpool(net, name="pool1")
net = conv2d(net, 64, 3, 1, name="conv2")
net = maxpool(net, name="pool2")
net = conv2d(net, 128, 3, 1, name="conv3_1")
net = conv2d(net, 64, 1, name="conv3_2")
net = conv2d(net, 128, 3, 1, name="conv3_3")
net = maxpool(net, name="pool3")
net = conv2d(net, 256, 3, 1, name="conv4_1")
net = conv2d(net, 128, 1, name="conv4_2")
net = conv2d(net, 256, 3, 1, name="conv4_3")
net = maxpool(net, name="pool4")
net = conv2d(net, 512, 3, 1, name="conv5_1")
net = conv2d(net, 256, 1, name="conv5_2")
net = conv2d(net, 512, 3, 1, name="conv5_3")
net = conv2d(net, 256, 1, name="conv5_4")
net = conv2d(net, 512, 3, 1, name="conv5_5")
shortcut = net
net = maxpool(net, name="pool5")
net = conv2d(net, 1024, 3, 1, name="conv6_1")
net = conv2d(net, 512, 1, name="conv6_2")
net = conv2d(net, 1024, 3, 1, name="conv6_3")
net = conv2d(net, 512, 1, name="conv6_4")
net = conv2d(net, 1024, 3, 1, name="conv6_5")
# ---------
net = conv2d(net, 1024, 3, 1, name="conv7_1")
net = conv2d(net, 1024, 3, 1, name="conv7_2")
# shortcut
shortcut = conv2d(shortcut, 64, 1, name="conv_shortcut")
shortcut = reorg(shortcut, 2)
net = tf.concat([shortcut, net], axis=-1)
net = conv2d(net, 1024, 3, 1, name="conv8")
# detection layer
net = conv2d(net, n_last_channels, 1, batch_normalize=0,
activation=None, use_bias=True, name="conv_dec")
return net然后实现对Darknet-19模型输出的解码:
def decode(detection_feat, feat_sizes=(13, 13), num_classes=80,
anchors=None):
"""decode from the detection feature"""
H, W = feat_sizes
num_anchors = len(anchors)
detetion_results = tf.reshape(detection_feat, [-1, H * W, num_anchors,
num_classes + 5])
bbox_xy = tf.nn.sigmoid(detetion_results[:, :, :, 0:2])
bbox_wh = tf.exp(detetion_results[:, :, :, 2:4])
obj_probs = tf.nn.sigmoid(detetion_results[:, :, :, 4])
class_probs = tf.nn.softmax(detetion_results[:, :, :, 5:])
anchors = tf.constant(anchors, dtype=tf.float32)
height_ind = tf.range(H, dtype=tf.float32)
width_ind = tf.range(W, dtype=tf.float32)
x_offset, y_offset = tf.meshgrid(height_ind, width_ind)
x_offset = tf.reshape(x_offset, [1, -1, 1])
y_offset = tf.reshape(y_offset, [1, -1, 1])
# decode
bbox_x = (bbox_xy[:, :, :, 0] + x_offset) / W
bbox_y = (bbox_xy[:, :, :, 1] + y_offset) / H
bbox_w = bbox_wh[:, :, :, 0] * anchors[:, 0] / W * 0.5
bbox_h = bbox_wh[:, :, :, 1] * anchors[:, 1] / H * 0.5
bboxes = tf.stack([bbox_x - bbox_w, bbox_y - bbox_h,
bbox_x + bbox_w, bbox_y + bbox_h], axis=3)
return bboxes, obj_probs, class_probs我将YOLOv2的官方训练权重文件转换了TensorFlow的checkpoint文件(下载链接),具体的测试demo都放在我的GitHub上了,感兴趣的可以去下载测试一下,至于train的实现就自己折腾吧,相对会棘手点。

图11:YOLOv2在自然图片上的测试
2.Training for detection
为了把分类网络改成检测网络,去掉原网络最后一个卷积层,增加了三个 3 * 3 (1024 filters)的卷积层,并且在每一个卷积层后面跟一个1 * 1的卷积层,输出维度是检测所需数量。也添加了passthrough layer,从最后3 * 3 * 512的卷积层连到倒数第二层,使模型有了细粒度特征。
对于VOC数据集,预测5种boxes,每个box包含5个坐标值和20个类别,所以总共是5 * (5+20)= 125个输出维度。
学习策略是:先以 的初始学习率训练了160次,在第60次和第90次的时候学习率减为原来的十分之一。weight decay为0.0005,momentum为0.9,以及类似于Faster-RCNN和SSD的数据扩充(data augmentation)策略: random crops, color shifting, etc。使用相同的策略在 COCO 和VOC上训练。
的初始学习率训练了160次,在第60次和第90次的时候学习率减为原来的十分之一。weight decay为0.0005,momentum为0.9,以及类似于Faster-RCNN和SSD的数据扩充(data augmentation)策略: random crops, color shifting, etc。使用相同的策略在 COCO 和VOC上训练。
【优化策略:Stronger】
文中提出了一种训练方法:jointly training(联合训练),就是将分类的数据集和检测的数据集放一起训练。检测数据集可以用来训练网络的检测和定位能力,分类数据集则用来扩大网络识别物体的范围和能力,就是可以将物体进行更细的分类,也可以分更多的类。但是由于检测数据集包含的是一些常见的目标和标签(如,狗、船等),但是分类数据集的标签往往更广和更深,比如狗还分为哈士奇、萨摩耶犬等等。所以要进行联合训练,就需要合并这些标签。
目前常用的分类方法都是采用softmax输出所有类别的概率。但是使用softmax的前提是类别之间都是相互独立的(相互不重叠不包含的)。显然将检测和分类数据集简单的合并并不能满足这个要求,所以文中就提出了一个多标签的模型来合并数据集,使得类别之间相互独立。
1.WordTree
ImageNet的数据标签来源于WordNet,所以YOLOv2构建了ImageNet和COCO合并起来的WordTree(如下图所示),WordNet以physical object为根结点,然后再将各个标签按照关联关系来构建树的节点,节点之间的连接表示了标签之间的关系(上位/下位关系)。

WordNet中蓝色的节点表示COCO数据集中的标签,红色的节点表示ImageNet中的标签,树中各个父节点和子节点之间有一种包含关系:physical object包括animal等,animal包括cat、dog等,cat包括tabby、persian等。但是每个子节点和其兄弟节点之间是互斥关系,即每个节点的所有子节点之间是互斥的,因此每个节点下的所有子节点都可以进行softmax操作,如下图:

2. 构建WordTree
构建ImageNet和COCO的WordTree的步骤如下:
(1)对于ImageNet和COCO数据集中的每一个样本,都在WordTree中找到对应的节点,如果从根结点到该节点的路径只有一条,那么就将改路径添加到WordTree中。
(2) 经过第一步操作后,剩下的就是存在多条路径的样本,对于这些样本,那就对比每条路径的长度,选择最短的路径加入到WordTree中。
对于所有的样本都按照上述过程构建WordTree,最终树中共有9418个节点,包括ImageNet数据中的9000个标签,COCO数据集中的标签,还有为了构建树额外添加的一些中间标签。
3. 类别表示方式
之前,我们表示一个物体的类别时都是用一个n维向量,其中物体所属类别的那一维值接近于1,其余接近0。使用这种方式的前提是这些类标签之间是互斥的,但是在WordTree中假如一个样本是狗的图片,那么dog节点的概率应该为1,但是dog属于animal,那么animal节点的概率也应该是1,依此类推,根结点physical object的概率也应该是1,所有在WordTree中应该是对应节点到根结点上每一个节点的概率都应该是1,而其余的节点的概率应该为0。
4. 计算概率
类别表示方式不同,那么概率计算的方式肯定也要不同。在文中,计算WordTree中节点的概率时用的是条件概率:P(Norfolk terrier) = P(Norfolk terrier|terrier) * P(terrier|hunting dog) * P(hunting dog|dog) *......* P(animal|physical object) * P(physical object)
其中,P(physical object) = 1。但是在实际中,为了减少计算量,不需要计算出每个节点的概率,在预测物体所属的类别时,我们从根结点开始往下遍历,对于每一个节点,选择其子节点中概率最大的节点往下遍历,直到到达叶节点或节点的概率小于设定的阈值,那么就停止遍历,那停止遍历的这个节点对应的标签就是物体所属的类别。
5. 联合训练
样本:由于ImageNet样本量比COCO大,所以为了平衡,就需要对COCO的样本多进行一些采样(oversampling),然后使得样本数量的比例为4:1。
网络:YOLO9000的网络结构和YOLOv2相同,都是使用Darknet-19,只是在输出上稍作了改进。首先为了减少计算量,将anchor的个数减少为3个,因此输出也变成为13*13*3*(5+9418)
loss:对于检测样本,loss的计算还是依旧,对于ImageNet中的分类样本,YOLO9000会输出只计算分类误差。