大数据---Azkaban快速入门
Azkaban快速入门
- 一、Azkaban的概论
-
- 1.1、Azkaban的定义
- 1.2、为什么需要工作流调度系统
- 1.3、常见的工作流调度系统
- 1.4、Azkaban 与 Oozie 对比
- 1.5、Crontab的基本使用
- 二、Azkaban的入门
-
- 2.1、集群模式安装(版本为-3.84.4)
-
- 2.1.1、上传jar包
- 2.1.2、配置 MySQL
- 2.1.3、 配置 Executor Server(在/opt/module/azkaban/azkaban-exec/下执行)
- 2.1.4、配置 Web Server
- 2.2、Work Flow 案例实操
-
- 2.2.1、web端
- 2.2.2、HelloWorld 案例
- 2.2.3、作业依赖案例
- 2.2.4、自动失败重试案例
- 2.2.5、手动失败重试案例
- 三、Azkaban的进阶
-
- 3.1、JavaProcess 作业类型
- 3.2、条件工作流
-
- 3.2.1、运行时参数
- 3.2.2、 预定义宏
- 3.3、定时执行
- 3.4、Azkaban 多 Executor 模式注意事项
- 四、azkaban官网
- 五、总结
一、Azkaban的概论
1.1、Azkaban的定义
Azkaban 是一个分布式工作流管理程序,解决Hadoop工作依赖性问题。
Azkaban is a distributed Workflow Manager, implemented at LinkedIn to solve the problem of Hadoop job dependencies.
We had jobs that needed to run in order, from ETL jobs to data analytics products.
1.2、为什么需要工作流调度系统
1. 一个完整的数据分析系统通常都是由大量任务单元组成:Shell 脚本程序,Java 程序,MapReduce 程序、Hive 脚本等
2. 各任务单元之间存在时间先后及前后依赖关系
3. 为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行
1.3、常见的工作流调度系统
1. 简单的任务调度:直接使用 Linux 的 Crontab 来定义;
2. 复杂的任务调度:开发调度平台或使用现成的开源调度系统,比如 Ooize、Azkaban、Airflow、DolphinScheduler 等。
1.4、Azkaban 与 Oozie 对比
总体来说,Ooize 相比 Azkaban 是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。
如果可以不在意某些功能的缺失,轻量级调度器 Azkaban 是很不错的候选对象。
1.5、Crontab的基本使用
Linux crontab是用来定期执行程序的命令。
crontab [ -u user ] file
#或
crontab [ -u user ] { -l | -r | -e }
1. -u user 是指设定指定 user 的时程表,这个前提是你必须要有其权限(比如说是 root)才能够指定他人的时程表。
如果不使用 -u user 的话,就是表示设定自己的时程表。
2. -e : 执行文字编辑器来设定时程表,内定的文字编辑器是 VI,如果你想用别的文字编辑器,
则请先设定 VISUAL 环境变数来指定使用那个文字编辑器(比如说 setenv VISUAL joe)
3. -r : 删除目前的时程表
4. -l : 列出目前的时程表
时间格式:
f1 f2 f3 f4 f5 program
-f1:表示分钟(0-59)
f1 为 * 时表示每分钟都要执行 program
f1 为 a-b 时表示从第 a 分钟到第 b 分钟这段时间内要执行
f1 为 */n 时表示每 n 分钟个时间间隔执行一次
f1 为 a, b, c,... 时表示第 a, b, c,... 分钟要执行
-f2:表示小时(0-23)
-f3:表示一个月份中的第几日(1-31)
-f4:表示月份(1-12)
-f5:表示一个星期中的第几天(0-6)
-program:表示要执行的程序
二、Azkaban的入门
2.1、集群模式安装(版本为-3.84.4)
2.1.1、上传jar包
- 将 azkaban-db-3.84.4.tar.gz,azkaban-exec-server-3.84.4.tar.gz,azkaban-web-server-3.84.4.tar.gz 上传到集群的某一个节点(本人上传到了hadoop101的/opt/software)
- 新建/opt/module/azkaban 目录,并将所有 tar 包解压到这个目录下
mkdir /opt/module/azkaban
- 解压 azkaban-db-3.84.4.tar.gz、 azkaban-exec-server-3.84.4.tar.gz 和 azkaban-web-server-3.84.4.tar.gz 到/opt/module/azkaban 目录下(在/opt/software目录下执行这三条命令)
tar -zxvf azkaban-db-3.84.4.tar.gz -C /opt/module/azkaban/
tar -zxvf azkaban-exec-server-3.84.4.tar.gz -C /opt/module/azkaban/
tar -zxvf azkaban-web-server-3.84.4.tar.gz -C /opt/module/azkaban/
- 进入到/opt/module/azkaban 目录,依次修改名称(在/opt/module/azkaban目录下执行这三条命令)
mv azkaban-exec-server-3.84.4/ azkaban-exec
mv azkaban-web-server-3.84.4/ azkaban-web
2.1.2、配置 MySQL
- 登陆 MySQL,创建 Azkaban 数据库(在MySQL中执行)
create database azkaban;
- 创建 azkaban 用户并赋予权限(在MySQL中执行)
#设置密码有效长度 4 位及以上
set global validate_password_length=4;
#设置密码策略最低级别
set global validate_password_policy=0;
#创建 Azkaban 用户,任何主机都可以访问 Azkaban,密码是 123456
CREATE USER 'azkaban'@'%' IDENTIFIED BY '123456';
#赋予 Azkaban 用户增删改查权限
GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' WITH GRANT OPTION;
- 创建 Azkaban 表,完成后退出 MySQL(在MySQL中执行)
use azkaban;
source /opt/module/azkaban/azkaban-db-3.84.4/create-all-sql-3.84.4.sql;
quit;
- 更改 MySQL 包大小;防止 Azkaban 连接 MySQL 阻塞
sudo vim /etc/my.cnf
在[mysqld]下面加一行 max_allowed_packet=1024M
[mysqld]
max_allowed_packet=1024M
- 重启 MySQL
sudo systemctl restart mysqld
2.1.3、 配置 Executor Server(在/opt/module/azkaban/azkaban-exec/下执行)
- 编辑 azkaban.properties
vim /opt/module/azkaban/azkaban-exec/conf/azkaban.properties
修改如下的属性
#时区
default.timezone.id=Asia/Shanghai
#azkaban的服务器地址(此处为hadoop101)
azkaban.webserver.url=http://hadoop101:8081
#结点之间通信的端口
executor.port=12321
#MySQL的服务器结点
mysql.host=hadoop101
#元数据在MySQL中的数据库
mysql.database=azkaban
#元数据在MySQL中的管理者
mysql.user=azkaban
#访问MySQL中azkaban数据库的密码
mysql.password=123456
- 同步 azkaban-exec 到所有节点(xsync.sh为自己写的同步脚步命令)
xsync.sh /opt/module/azkaban/azkaban-exec
- 启动 executor (必须进入到/opt/module/azkaban/azkaban-exec 路径,分别在三台机器上)
server
bin/start-exec.sh
#如果在/opt/module/azkaban/azkaban-exec 目录下出现 executor.port 文件,说明启动成功
- 激活 executor (必须进入到/opt/module/azkaban/azkaban-exec 路径,分别在三台机器上)
curl -G "hadoop101:12321/executor?action=activate" && echo
curl -G "hadoop102:12321/executor?action=activate" && echo
curl -G "hadoop103:12321/executor?action=activate" && echo
#如果三台机器都出现{"status":"success"},则表示激活成功
2.1.4、配置 Web Server
Azkaban Web Server 处理项目管理,身份验证,计划和执行触发。
- 编辑 azkaban.properties
vim /opt/module/azkaban/azkabanweb/conf/azkaban.properties
修改如下属性
#默认时区
default.timezone.id=Asia/Shanghai
#azkaban的web服务器所在结点,此处为hadoop101
mysql.host=hadoop101
#元数据在MySQL中的数据库
mysql.database=azkaban
#元数据在MySQL中的管理者
mysql.user=azkaban
#访问MySQL中azkaban数据库的密码
mysql.password=123456
mysql.numconnections=100
...
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
- 修改 azkaban-users.xml 文件,添加 hadoop 用户
vim /opt/module/azkaban/azkabanweb/conf/azkaban-users.xml
-users>
"azkaban" password="azkaban" roles="admin" username="azkaban"/>
"metrics" roles="metrics" username="metrics"/>
#在原来基础加这一行,表示增加一个hadoop用户,角色为admin
"123456" roles="admin" username="hadoop"/>
"admin" permissions="ADMIN"/>
"metrics" permissions="METRICS"/>
</azkaban-users>
- 启动 web server(必须进入到 hadoop101 的/opt/module/azkaban/azkaban-web 路径)
bin/start-web.sh
- 访问 http://hadoop101:8081,并用 hadoop 用户登陆
2.2、Work Flow 案例实操
2.2.1、web端

2.2.2、HelloWorld 案例
-
新建 azkaban.project 文件(以.project为后缀的文件名)
作用:
表示采用新的 Flow-API 方式解析 flow 文件
内容:
azkaban-flow-version: 2.0 -
新建 basic.flow 文件(以.flow为后缀的文件名)
作用:
表示作业调度过程
内容:
yaml语法的编写
nodes:
- name: jobA(job 名称)
type: command(job 类型。command 表示你要执行作业的方式为命令)
config:(job 配置)
command: echo “Hello World” -
将 azkaban.project、basic.flow 文件压缩到一个 zip 文件,文件名称必须是英文
-
在 WebServer 新建项目:http://hadoop101:8081/index
-
给项目名称命名和添加项目描述

-
把压缩的文件进行上传

-
执行任务流



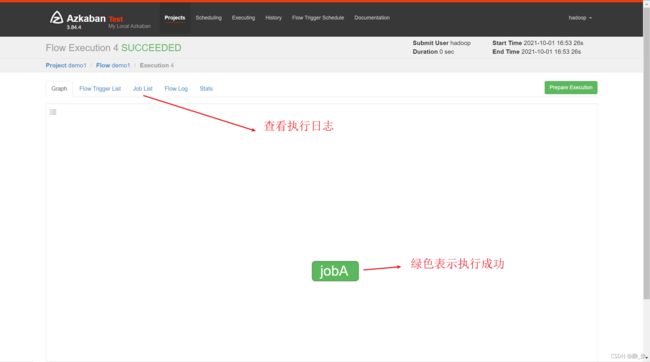
2.2.3、作业依赖案例
需求:JobA 和 JobB 执行完了,才能执行 JobC
-
步骤与上相同
-
修改 basic.flow 为如下内容
nodes:
- name: jobC
type: command
# jobC 依赖 JobA 和 JobB
dependsOn:
- jobA
- jobB
config:
command: echo "I’m JobC"
- name: jobA
type: command
config:
command: echo "I’m JobA"
- name: jobB
type: command
config:
command: echo "I’m JobB"
2.2.4、自动失败重试案例
需求:如果执行任务失败,需要重试 3 次,重试的时间间隔 10000ms
-
步骤与上相同
-
修改 basic.flow 为如下内容
nodes:
- name: JobA
type: command
config:
command: sh /not_exists.sh(执行脚本)
retries: 3(重试次数)
retry.backoff: 10000(重试间隔时间)
- 也可以在 Flow 全局配置中添加任务失败重试配置,此时重试配置会应用到所有 Job。
config:
retries: 3
retry.backoff: 10000
nodes:
- name: JobA
type: command
config:
command: sh /not_exists.sh
2.2.5、手动失败重试案例
需求:JobA=》JobB(依赖于 A)=》JobC=》JobD=》JobE=》JobF。生产环境,任何 Job 都
有可能挂掉,可以根据需求执行想要执行的 Job。

此处右击,可选择是执行某个过程
Enable 和 Disable 下面都分别有如下参数:
Parents:该作业的上一个任务
Ancestors:该作业前的所有任务
Children:该作业后的一个任务
Descendents:该作业后的所有任务
Enable All:所有的任务
三、Azkaban的进阶
3.1、JavaProcess 作业类型
JavaProcess 类型可以运行一个自定义主类方法,type 类型为 javaprocess,可用的配置为:
Xms:最小堆
Xmx:最大堆
classpath:类路径
java.class:要运行的 Java 对象,其中必须包含 Main 方法
main.args:main 方法的参数
flow文件内容:
nodes:
- name: test_java
type: javaprocess
config:
Xms: 96M
Xmx: 200M
java.class: com.atguigu.AzTest
3.2、条件工作流
条件工作流功能允许用户自定义执行条件来决定是否运行某些Job。条件可以由当前Job的父 Job 输出的运行时参数构成,也可以使用预定义宏。在这些条件下,用户可以在确定 Job执行逻辑时获得更大的灵活性,例如,只要父 Job 之一成功,就可以运行当前 Job。
3.2.1、运行时参数
- 基本原理
父 Job 将参数写入 JOB_OUTPUT_PROP_FILE 环境变量所指向的文件
子 Job 使用 ${jobName:param}来获取父 Job 输出的参数并定义执行条件
- 支持的条件运算符
(1)== 等于
(2)!= 不等于
(3)> 大于
(4)>= 大于等于
(5)< 小于
(6)<= 小于等于
(7)&& 与
(8)|| 或
(9)! 非
3.2.2、 预定义宏
Azkaban 中预置了几个特殊的判断条件,称为预定义宏。
预定义宏会根据所有父 Job 的完成情况进行判断,再决定是否执行。
可用的预定义宏如下:
all_success: 表示父 Job 全部成功才执行(默认)
all_done:表示父 Job 全部完成才执行
all_failed:表示父 Job 全部失败才执行
one_success:表示父 Job 至少一个成功才执行
one_failed:表示父 Job 至少一个失败才执行
3.3、定时执行
- Azkaban 可以定时执行工作流。在执行工作流时候,选择左下角 Schedule。
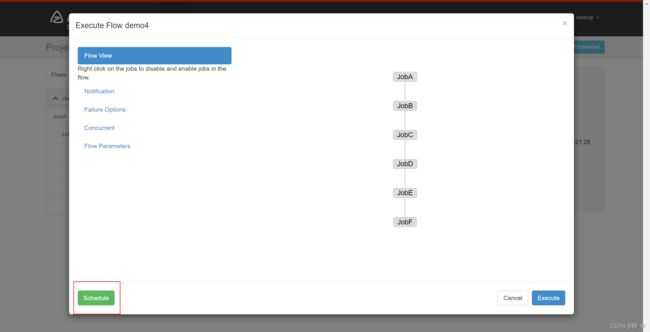
- 填写的方法和 crontab 配置定时任务规则一致。
3.4、Azkaban 多 Executor 模式注意事项
Azkaban 多 Executor 模式是指,在集群中多个节点部署 Executor。
在这种模式下,Azkaban web Server 会根据策略,选取其中一个 Executor 去执行任务。
为确保所选的 Executor 能够准确的执行任务,我们须在以下两种方案任选其一,推荐使用方案二。
方案一:指定特定的 Executor(hadoop101)去执行任务。
1. 在 MySQL 中 azkaban 数据库 executors 表中,查询 hadoop101 上的 Executor 的 id
2. 在执行工作流程时加入 useExecutor 属性
方案二:在 Executor 所在所有节点部署任务所需脚本和应用。
四、azkaban官网
官网文档
五、总结
此文档为学习完尚硅谷的视频之后总结。