基于自注意力的生成对抗归因网络的交通流缺失数据修复
![]()
文章信息
![]()
《Missing Data Repairs for Traffic Flow With Self-Attention Generative Adversarial Imputation Net》是2022年7月发表在期刊IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTA TION SYSTEMS上的一篇文章。
![]()
摘要
![]()
随着传感器技术的快速发展,由多个空间分布的传感器采集的时间序列数据被广泛应用于不同的研究领域。这种数据的例子包括由温度传感器收集的地理标记温度数据、空气污染物监测数据和由道路交通传感器收集的交通数据。由于传感器故障、通信错误和存储丢失等原因。传感器收集的数据不可避免地包含缺失数据。然而,通常用于分析这种大规模数据的模型通常依赖于完整的数据集。文章提出了一种交通流缺失数据填补模型,该模型将自我注意力机制、自动编码器和生成对抗网络结合成一个自我注意力生成对抗填补网络(SA-GAIN)。自我注意机制的引入可以帮助所提出的模型有效地捕捉不同时间点上空间分布的传感器之间的相关性。通过称为生成器和判别器的两个神经网络的对抗性训练,允许所提出的模型生成接近真实数据的估算数据。与不同的插补模型相比,所提出的模型在插补缺失数据方面表现出最佳的性能。
![]()
介绍
![]()
本文的主要贡献如下:
1)提出了一种基于自我注意力的交通数据填补方法。考虑到不同传感器之间的相互依赖性存在差异,该模型利用自我注意机制以潜在的方式学习交通数据的时空相关性,以提高修复效果。
2)引入GAN网络结构以区分估算的交通数据和真实数据,允许生成器估算更接近真实分布的数据。
![]()
方法
![]()
在这一部分中,提出了一种基于自我注意力的自动编码器的新的生成对抗网络模型来估计丢失的流量数据。首先给出了问题的定义和前提。其次,介绍了自我注意机制和GAN的基本原理。第三,介绍了模型的构建。最后,将该模型应用于交通数据的插补。
A. 问题定义
一个d维数据空间定义为χ = {χ 1,χ2,χ3,…,χd}。然后从χ中取一个随机多维时间序列为X = {x1,x2,x3,…,xd},X的联合概率分布是P(X)。假设掩码变量M = (m1,m2,…,md) 从{0,1}d中取值,其分布可表示为P (M)。对于i ∈ {1,…,d},有缺失值的新空间{*}可以定义为χi ∪ {·}。那么来自新变量空间的具有缺失值的随机采样数据变量可以表示为X =(x1,x2,…,xd),其分布可以表示为P(X)。一对掩码变量Mi和数据变量 之间的关系可以表示为等式(1):
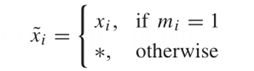
B. 自我注意力机制
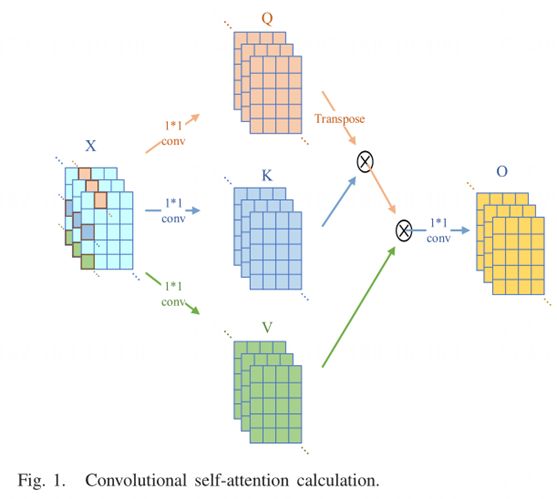
一个注意函数描述了三元函数注意(Q,K,V)。这三个变量称为“查询”、“键”和“值”。注意力函数将一个“查询”和一组“键”-“值”对映射到输出,其中“查询”、“键”、“值”和输出都是向量。输出是“值”的加权和,其中分配给每个值的权重由“查询”和相应的“键”计算。
来自前一层的特征x ∈ RC×N通过两个特征映射函数Q = Wq*x和K = Wk*x被变换到两个特征空间“查询”和“关键”来计算关注度权重,

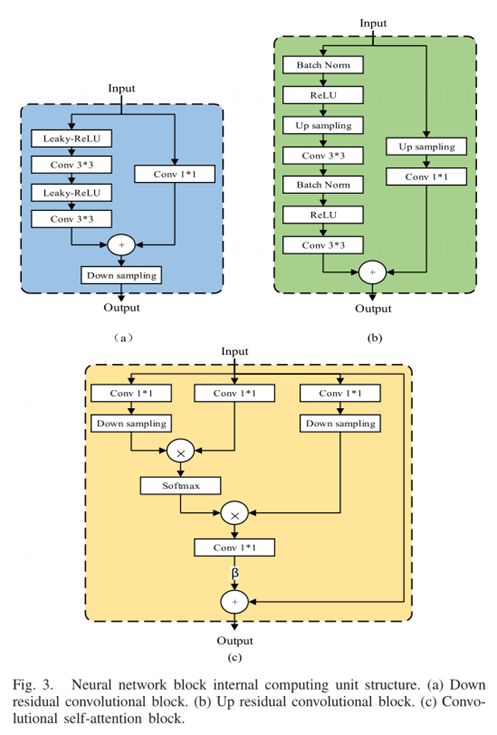
这里,βj,i表示当合成第i个区域时,模型关注第i个位置的程度。c是通道的数量,N是先前隐藏层中的特征的数量。卷积自注意力计算如图1所示。
注意力函数的输出可以公式化为o = (o1, . . . , o j , . . . , oN)∈ RC×N,
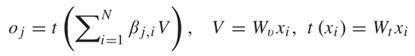
在上式中,Wk ∈ R C×C,Wq ∈ R C×C,Wv ∈ R C×C,Wt ∈ RC× C是1 × 1卷积运算中可训练的卷积核。在之前的研究中发现,映射后减少通道数量不会导致显著的性能损失。在该文章中中,缩放因子k = 8 w用于缩放中间通道的数量C = C/k,用于注意力计算。
请注意,图层的输出乘以可训练比例参数,然后添加到输入要素地图。因此,最终输出是
![]()
其中,γ控制关注度计算结果在最终输出中的比例,该比例初始化为0。γ越大,注意层对全球位置数据的输出感知越大。
C. 生成对抗网络
GAN由一个生成器(G)和一个判别器(D)组成。G学习映射G (z),它试图将随机噪声向量z映射到真实数据。D试图找到一个映射D(.)来辨别输入数据的真实概率。最初的GAN生成器和判别器由神经网络组成。判别器和生成器交替训练,相互竞争。生成器是将先验分布从潜在空间Z映射到数据空间X的连续、可微的变换函数,其目的是欺骗判别器。判别器区分其输入是否来自真实的数据分布。通过这种方法,生成器可以学习创建类似于真实数据分布的解决方案,因此很难通过d进行分类。这种对立的过程使GAN比其他生成模型具有显著的优势。训练的停止条件是判别器无法判断数据是否来自真实样本,生成器无法生成进一步的假样本,从而迷惑判别器。
生成器G和判别器D作为两个竞争对手,用值函数V (D,G)同时进行极小极大训练。形式上,用Pz (z)作为输入先验分布,Pdata (x)作为训练数据分布,GAN的极小最大目标定义为

其中x代表实际数据,Pdata(x)代表实际数据的分布,z是生成器网络的输入,通常取自假设的先验数据分布Pz(z)。D(x)和D(G(x))分别是向判别器网络输入实际数据x和产生数据G(x)时的输出。
D. 自我注意力生成对抗归因网络
在原始的GANs模型算法中,生成器的输入是一个随机变量。值得注意的是,缺失数据插补问题的输入由不完全样本组成。考虑到这一点,在文章提出的模型建立过程中,使用自动编码器作为生成器,并通过判别器损失和重构损失将生成的样本约束为与相应的输入样本相似。在这里,介绍了多维缺失数据填补的SA-GAIN建议。提出的模型如图2所示。
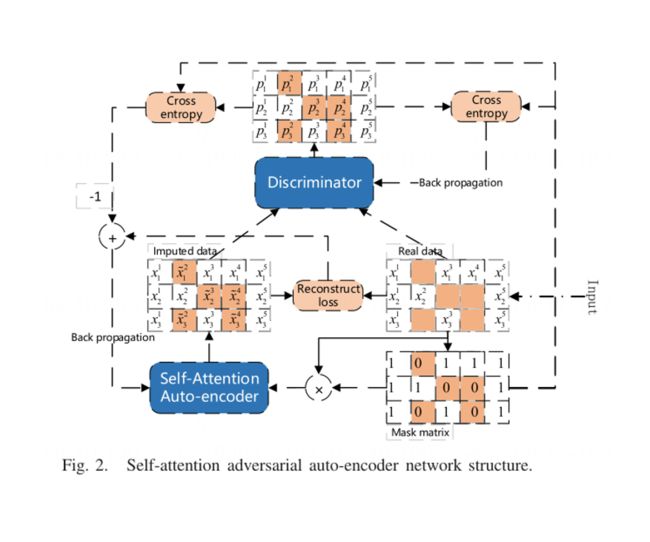
GAN与传统监督学习的区别在于,GAN的判别器网络隐式地学习输入数据的多样性相似性度量,以区分“真实数据”和“构造数据”。因此,该模型在训练生成器的过程中加入了判别器学习到的相似性度量损失,以帮助生成器提高插补性能。将判别器学习到的误差加入到先验假设的重构损失中,最终得到一种结合了GAN的高质量生成模型和最小化重构损失优点的方法,能够准确修复缺失数据,修复后数据的分布更加符合真实数据的分布。
受SAGAN的启发,在模型中加入了位置编码和卷积自注意机制,以捕捉交通数据中的时空相关性。通过这种结构,模型可以学习不同环路检测器和时间戳之间的数据相关性,这种结构提高了插补精度和效果。卷积自注意结构如图3 (c)所示,位置编码结构在第III.C节中介绍。
下面详细介绍图2中网络结构的各个部分。
1)生成器:在所提出的框架中,生成器由基于自注意机制的自动编码器神经网络组成,其作用是尽可能地估算缺失数据。生成器的插补过程可以用公式表示为:
![]()
其中表示逐元素乘法。m表示观察到x的哪些分量。x表示不完整的数据,而 表示估算的数据。上述公式描述了使用生成数据和观测数据获得估算数据的过程。为了提高模型的泛化能力,文章借鉴了DAE(深度去噪自动编码器)模型的基本概念,并将噪声z添加到输入中。通过最小化等式中所示的目标函数,
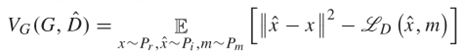
![]()
在模型中应用判别器损失的动机是约束生成数据和真实数据的相似性,并迫使生成器学习观察到的数据分布。生成器的网络结构如图4 (a)所示,构成网络的块结构如图3所示。图3中的块结构类似于Res-Net的用于特征融合的捷径连接。

2)判别器:在GAN训练框架中,需要引入一个判别器D,它将作为训练G的对手,在标准的GAN中,生成器的输出要么是完全真的,要么是完全假的,而在数据插补问题中,输出的是共存的观测值和生成值。判别器试图区分哪部分输入是真实的(观察到的),哪部分输入是生成器生成的(估算的)。判别器的网络结构如图4(b)所示,其输出与输入维数相同,表征了输入数据的真实性。生成器输出值越大,网络将该位置的输入视为观测值的可能性就越大。
3)位置编码:由于模型不包括作为计算一部分的输入时间戳信息,并且整个过程的计算是并行进行的,这可能意味着不考虑交通流数据中的时间序列信息。为了使模型利用序列中包含的时间戳和周期性信息,需要人工生成一些关于序列中标记的相对或绝对位置的信息,并将其合并到输入数据中。变压器模型是一种避免重复出现的模型架构,而是完全依赖于注意机制来绘制输入和输出之间的全局依赖性。受变压器模型的位置编码的启发,在构建模型输入数据时,通过向输入数据添加位置编码来添加数据序列信息。位置编码信息的维度与每个时间点的输入数据的特征维度相同,并且连接的数据和编码的位置被用作模型的输入。在所提出的模型中,等式中所示的位置编码方法被使用,

其中t是输入数据一天中的时间戳,i表示维度,F表示数据的采样频率。换句话说,编码位置的每个维度对应于一个正弦信号。选择此函数是因为它允许模型通过相对位置轻松地学习参与计算。对于任何固定的偏移量k,P E(t+k,I)可以表示为P E(t,I)的函数。在交通数据插补中,不同的位置编码应用于一天中不同的采集时间戳,因此生成器可以使用这些信息来构建缺失的数据。
E.稳定GAN训练的技巧
已知GANs的训练是不稳定的,并且对超参数的选择敏感。一些试图稳定GAN训练过程的工作已经取得了极好的结果。例如,[44]-[46]通过设计新的网络架构提高了样本多样性。[47]-[50]修改了学习目标和动态以实现趋同。有研究表明,加入正则化方法[51]、[52]和引入启发式技巧[53]、[55]可以提高收敛速度或达到更好的收敛效果。因此,采用了谱归一化[52]和两种时间尺度更新规则[56]的方法来提高收敛速度和模型稳定性。以下是对这两种方法的介绍。
1)频谱归一化:Miyato等人提出了一种频谱归一化技术,以确定在整个训练过程中判别器网络中每层的可训练权重是否满足Lipschitz限制条件。一项研究发现,对发生器和判别器使用频谱归一化可以稳定整个对抗训练过程。鉴于此,在所提出的模型的发生器和判别器中都使用了光谱归一化。公式(10)和 (11)说明如何将频谱归一化应用于可训练权重。
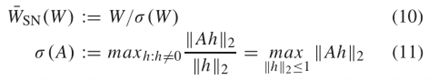
其中W表示可训练权重,σ (A)表示权重矩阵的模,其谱半径等于矩阵的最大特征值。
2)双时标更新规则:在模型训练过程中,判别器和生成器使用相同的学习速率进行参数优化往往是不合适的。在训练过程中,Heusel等人提出,对生成器和判别器采用单独学习率(TTUR)的模型训练可以提高网络的训练效率,并在相同的迭代轮次中获得更好的模型性能。在文章的模型训练部分,Adam优化器用于自关注自动编码器网络和判别器网络。判别器训练过程的参数设置为β1 = 0,β2 = 0.9,学习率为0.0004,生成器训练过程的参数设置为β1 = 0,β2 = 0.9,学习率为0.0001。
算法3.1是文章提出的算法的训练过程的伪代码。在模型的训练阶段,采用Adam梯度下降算法进行参数优化和学习率调整;使用Xavier统一初始化所有权重;输入数据批量大小(小批量)设置为32;输入数据被归一化为[0,1]。在发生器和判别器中的可训练权重上施加频谱归一化(SN)。30个epoch被用作模型训练的停止条件。

![]()
实验
![]()
在本节中,文章在真实数据集上对提出的方法进行了评估。对实验结果进行了详细分析,并与其他基线模型进行了比较。
A. 数据集
实验部分使用的数据集是从美国华盛顿州交通局(WSDOT)部署在美国西雅图I-5高速公路路面上的感应环检测器收集的。铺设在道路上的多个探测器被连接起来,以每半英里部署一个探测器站。在每个站点收集的数据根据方向进行分组,并根据站点汇总成交通数据。该聚合数据和质量控制数据集包含交通速度、流量和占用率信息。该研究仅使用交通量数据。实验中的交通量数据采集自2015年11月1日至2016年12月31日全天的80个选定检测器站,共计427天。数据采集时间步长为5分钟,每天产生288个样本。图5示出了数据收集位置和训练数据结构。

图5 (b)示出了数据构建过程,其通过时间仓的滑动窗口选择来生成实验训练数据集和测试数据集。这样,每个样本的输入大小被设置为(80,80),其代表由80个检测器站以五分钟间隔检测的80个交通流量记录。随机选择80%的数据集作为训练数据,其余20%的数据用作测试数据。
在实验中,基于交通流数据丢失的标准特征,设计了三种交通流丢失场景,并假设数据丢失过程是随机的。图6示出了三种缺失的数据模式。

图6(a)表示来自连续检测线圈的数据的连续丢失,这可能是由从路侧控制处理单元传输到监控子中心的数据的丢失引起的。图6 (b)示出了可能由于线圈损坏而没有收集到一些线圈数据的情况。图6 (c)表示在某些时刻没有收集到数据的情况,这可能是由通信或系统故障引起的。
![]()
Attention
![]()
如果你和我一样是轨道交通、道路交通、城市规划相关领域的,可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!