WenLan-10亿参数!别只玩GPT,来看看人大&中科院联手打造第一个大规模多模态中文预训练模型BriVL...
关注公众号,发现CV技术之美
▊ 写在前面
近年来,多模态预训练模型在视觉和语言之间架起了桥梁。然而,大多数研究都是通过假设文本和图像对之间存在很强的语义关联来对图像-文本对之间的跨模态交互进行显式建模。由于这种强假设在现实场景中往往无效,因此,作者选择隐式建模大规模多模态预训练的跨模态相关性。
具体地说,基于图文对的弱相关性假设,作者在跨模态对比学习框架中提出了一种称为BriVL的双塔预训练模型 。与OpenAI CLIP采用简单的对比学习方法不同,作者设计了一种更先进的算法,将最新的MoCo方法应用到跨模态场景中。通过构建一个大的基于队列的字典,BriVL可以在有限的GPU资源上增加了更多的负样本。
此外,作者还提出了一个大型的中文多源图文数据集RUC-CAS-WenLan ,用于对BriVL模型进行预训练。大量实验表明,预训练的BriVL模型在各种下游任务上都优于UNITER和OpenAI CLIP。
▊ 1. 论文和代码地址

WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
论文:https://arxiv.org/abs/2103.06561
代码:https://github.com/BAAI-WuDao/BriVl
▊ 2. Motivation
近年来,预训练模型已成为自然语言处理(NLP)领域的热门话题。一系列预训练模型,比如BERT、GPT,在下游的NLP任务中取得了很大的提升。随着GPT-3的发布,预训练语言模型现在已经引起了NLP社区的巨大关注。
与单模态场景下的文本理解相比,多模态理解更具吸引力,应用场景更广。事实上,随着NLP的预训练模式的成功,它们最近已经扩展到了同时理解文本和图像的任务中。在过去的两年里,人们不断地探索了多模态预训练模式,以架起视觉和语言之间的桥梁。
在2021年1月,OpenAI发布了多模态版本的GPT-3,名为DALL·E,展示了卓越的图文生成能力。这展示了多模态预训练的威力,也鼓励了研究者在“视觉+语言”的领域发掘大规模多模态预训练的潜力。

然而,目前在大规模的多模态预训练中仍然存在三个挑战:
1)无效的强假设 :现有的大多数模型都是通过假设输入图文对之间存在强语义相关性(见上图所示)来设计的,但这种强相关性假设在实际应用中往往是无效的。
2)预训练效率低下 :预训练过程往往非常昂贵,并行预训练需要大量的GPU。
3)模型部署困难 :预训练模型通常太大,无法在现实应用场景中部署,这对于那些单塔模型(例如UNITER)来说尤其困难。
在本文中,为了克服上述三个挑战,作者在跨模态对比学习框架(如OpenAI CLIP)之上,提出了一种更易于部署的双塔预训练模型BriVL。但是,与OpenAI CLIP不同的是,作者基于最新的MoCo设计了更先进的跨模态对比学习算法,使得BriVL可以在有限的GPU资源中包含更多负样本。
大多数现有的多模态预训练模型,特别是单塔结构的模型,都假设输入图文对之间存在较强的语义相关性。在这个强相关性假设下,图文对之间的相互作用可以用跨模态Transformer来建模。然而,在实际应用场景中,强相关性假设通常是无效的。图像-文本对之间通常只存在弱相关性。
此外,作者还进行了大量的实验,发现在含有噪声的图文数据上,双塔模型的性能明显优于单塔模型。因此,在本项目中,作者选择了双塔架构来设计大规模多模态预训练模型。
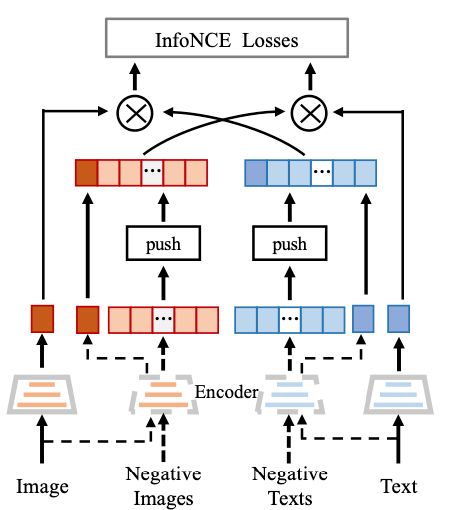
然而,双塔模型结构过于简单(没有UNITER那样的细粒度跨模态交互),因此多模态预训练必须增强其表示能力。由于自监督学习的进展,对比学习能显著提高深度神经网络的表示能力。基于这一思想,作者将对比学习引入到本文的双塔结构中。
此外,与OpenAI CLIP采用要求大Batch Size的对比学习方法不同,作者设计了一种更先进的跨模态对比学习算法。如上图所示,在给定图文对的情况下,可以使用图像模态或文本模态来构造图文对的缺失样本,并基于最新的MoCo框架扩展负样本的数量以提高神经网络的表示能力。
通过构建一个大型的基于队列的字典,本文的模型可以在有限的GPU资源中容纳更多的负样本,从而在图文检索中获得更好的结果。
由于使用了双塔结构以及基于对比学习的预训练策略,本文提出的BriVL模型具有很高的灵活性,可以很容易地部署到现实世界的应用场景中。它主要有三个优点:
1)在双塔架构下,文本编码器和图像编码器可以很容易地替换为最新的更大的单模态预训练模型,进一步增强了BriVL模型的表示能力。
2)一旦BriVL模型经过预训练,它就可以提供图像和文本特征embedding或者匹配分数的API,从而非常方便部署在各种下游任务中。
3)将其他预训练任务(例如,图像到文本生成)添加到BriVL模型中也非常方便。
▊ 3. 方法
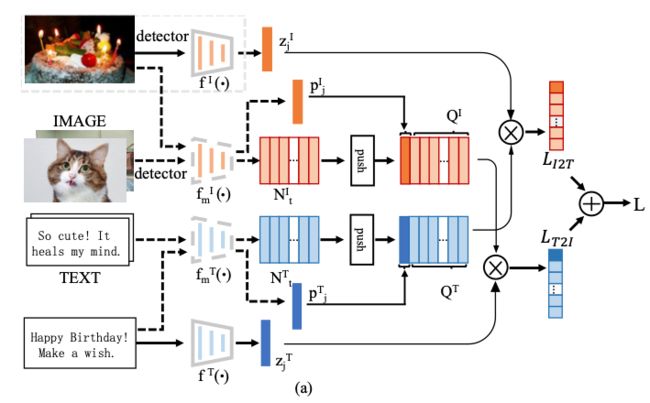
本文的跨模态预训练模型是基于图文检索任务定义的。因此,主要目标是学习两个编码器,它们可以将图像和文本样本嵌入到同一空间中,以实现有效的图文检索。为了加强这种跨模式嵌入学习,作者将具有InfoNCE损失的对比学习引入到BriVL模型中,如上图所示。
具体地说,对于给定的文本嵌入,模型的学习目标是从一个batch的图像嵌入中找到最佳的图像嵌入。类似地,对于给定的图像嵌入,模型的学习目标是从一个batch的文本嵌入中找到最佳的文本嵌入。
总之,本文的预训练模型通过联合训练图像和文本编码器来学习跨模态嵌入空间,以最大化Batch中每个匹配样本对的图像和文本嵌入的余弦相似度,同时最小化其他错误对的嵌入的余弦相似度,这就很自然的引入了用于预训练BriVL模型的图像-文本对的InfoNCE Loss。
与OpenAI CLIP相比,本文的模型可以在有限的GPU资源上获得更多的负样本,从而在图文检索中获得更好的结果。
形式上,对于图文检索任务,将训练集表示为,,,,其中,是来自RUC-CAS-WenLan数据集的匹配图文对,N是D的大小。
模型的训练流程如上图所示。图像编码器(或文本编码器)对每个图像(或每个文本)进行编码,以获得其一维嵌入(或)。
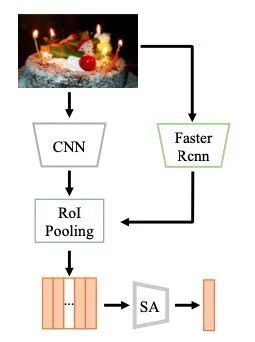
图像编码器如上图所示,包含一个CNN主干网络和Self-Attention模块。文本编码器由几个Self-Attention块堆叠而成,以及具有RELU激活函数的MLP,用于将特征映射到跨模态表示空间。和的参数分别表示为θ和θ。
MoCo提供了一种为对比学习构建动态字典的机制,该机制可用于各种预训练代理任务。在这项工作中,作者采用了一个简单的实例判别任务:如果图像对应于文本,则图像查询与增强文本的关键字匹配 ,反之亦然。
此外,队列的引入将字典大小与mini-batch size解耦。因此,字典大小可以比典型的mini-batch size大得多。给定动量参数m,分别为图像和文本模态保留两个动量更新编码器(具有参数θ)和(具有参数θ)。更新规则如下:
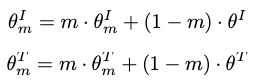
与MoCo类似,BriVL维护两个队列和,分别包含K个图像负样本和K个文本负样本。每次迭代之后,(为Batch Size)个图像和文本负样本分别会加入到这两个队列中。
这样,队列中的样本在每次迭代中都会更新。每个数据批次的损失函数构造如下:对于每个图像查询,作者定义了其图像嵌入与队列中所有正/负文本样本之间的对比损失,从而得到InfoNCE损失:
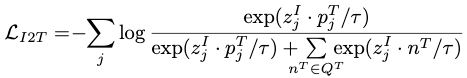
其中,表示每个图像查询的负文本匹配对,而超参数τ表示temperature。在这里,相似度是用点积来衡量的。同样,对于每个文本查询,InfoNCE损失表示为:
BriVL的总损失函数定义为:
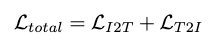
在测试阶段,查询图像(或文本)通过在预训练的编码器的输出上定义的点积来检索。由于其高度的灵活性,BriVL模型可以部署在广泛的应用场景中。首先,通过共享相同的文本或图像编码器,可以将其他预训练任务(例如,图像到文本的生成)添加到BriVL模型中。其次,预训练的文本和图像编码器可以直接应用于许多下游多模态任务。
▊ 4. 实验
4.1. Results on AIC-ICC
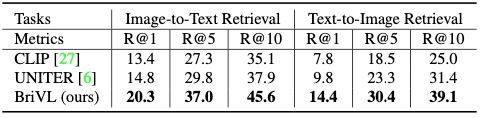
上表显示了在AIC-ICC数据集上进行图文检索任务时,本文方法和CLIP、UNITER模型的结果对比,可以看出,在性能方面,本文的方法全面碾压它们。

上表显示了在AIC-ICC数据集上进行Image Captioning任务时,本文方法和CLIP、UNITER模型的结果对比。
4.2. Results on RUC-CAS-WenLan
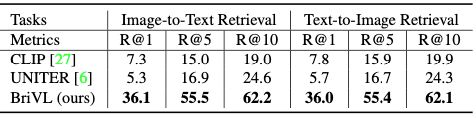
上表显示了在RUC-CAS-WenLan数据集上进行图文检索任务时,本文方法和CLIP、UNITER模型的结果对比。
4.3. User Study Results
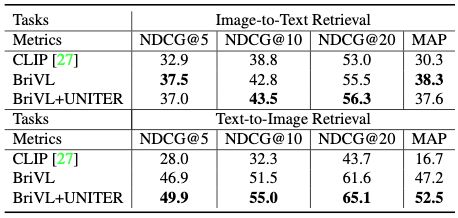
上表显示了本文方法和CLIP、UNITER模型进行User Study的实验结果。
4.4. Visual Results

上图显示了本文方法在进行image captioning任务上时的定性实验结果。

上图显示了本文方法在进行image tagging任务上时的定性实验结果。
▊ 5. 总结
本文提出了第一个大规模中文多模态预训练模型BriVL。BriVL模型的第一个版本有10亿个参数,它是在RUC-CAS-WenLan数据集上预训练的,有3000万个图文对。此外,作者还提出了RUC-CAS-WenLan,这是一个用于多模态预训练的大型多源中文图文数据集。
在性能上,BriVL模型在RUC-CAS-WenLan测试集和AIC-ICC验证集上都明显优于UNITER和OpenAI CLIP。利用预训练的BriVL模型,作者还开发了两个Web应用程序:MatchSoul和Soul-Music。此外,作者还准备将BriVL模型将扩大到100亿个参数,并将使用5亿个图文对进行预训练。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「视觉语言」交流群备注:VL
