【云计算与大数据计算】分布式处理CPU多核、MPI并行计算、Hadoop、Spark的简介(超详细)
一、CPU多核和POISX Thread
为了提高任务的计算处理能力,下面分别从硬件和软件层面研究新的计算处理能力
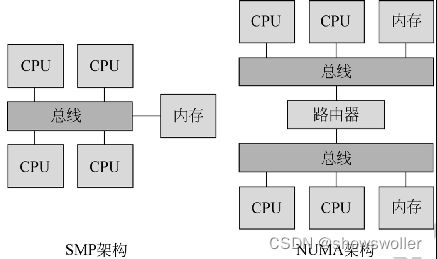
在硬件设备上,CPU 技术不断发展,出现了SMP(对称多处理器)和 NUMA(非一致 性内存访问)两种高速处理的 CPU 结构
在软件层面出现了多进程和多线程编程。进程是内存资源管理单元,线程是任务调度单元
总的来说,线程所占用的资源更少,运行一个线程所需要的资源包括寄存器,栈,程序计数器,早期不同厂商提供了不同的多线程编写库,以充分利用多个不同的线程库,组成POSIX Thread的API分成以下四个大类
1:线程管理 线程管理主要负责线程的create detach join等等 也包括线程属性的查询和设置
2:mutexes 处理同步的例程称为mutex,mutex提供了create destroy lock和unlock等函数
3:条件变量 条件变量主要用于多个线程之间的通信和协调
4:同步 同步用于管理读写锁,以及barriers
POSIX Thread 多线程编程标准

二、MPI并行计算框架
MPI (Message Passing Interface 消息传递窗口 )是一个标准且可移植的消息传递系统,服务于大规模的并行计算
广泛采用的实现有 MPICH
MPICH 包括 ADI3、CH3 Device、CH3Interface、Nemesis、Nemesis Net ModInterface
MPICH架构如下

三、Hadoop MapReduce
Hadoop是一个由 Apache基金会开发的分布式系统基础架构
Hadoop框架最核心的设计就是 HDFS和 MapReduce
HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上,而且它提供高吞吐量来访问应用程序的数据,适合有着超大数据集的应用程序,HDFS放宽了POSIX的要求,可以用流的形式访问文件系统中的数据
MapReduce为海量的数据提供了计算
指 定 一 个 Map 函数 ,用来把一组键值对映射成一组新的键值对, 指定并发的 Reduce函数,用来保证所有映射的键值对中的每一个共享相同的键组
四、Spark
Spark 是 UC Berkeley AMPLab所开源的类 Hadoop MapReduce的通用的并行计算框架
Spark 基于 map-reduce 算法实现的分布式计算,拥有 Hadoop MapReduce 所具有的优点
不同于 MapReduce的是中间输出和结果可以保存在内存中
Spark 最主要的结构是RDD (Resilient Distributed Datasets),它表示已被分区 、不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的 RDD 实现
因此Spark很适合迭代运算比较常见的机器学习算法、交互式数据挖掘等等。
五、数据处理技术的发展
数据处理从早期的共享分时单 CPU 操作系统处理到多核并发处理
早期 Google公司的分布式计算框 架 MapReduce采用的思想就是连接多台廉价的计算设备,以此来提供进行大规模计算任务的能力
为了满足实时计算任务需求,设计实现了流计算框架,比如Spark Streaming、Storm 、Flink 等实时计算框架
目前处理技术在往大规模、低延迟方向发展
创作不易 觉得有帮助请点赞关注收藏~~~