大数据技术之Hadoop
目录
第一章 大数据概述
1.大数据概念
1.2、大数据特点
1、Volume(大量)
2、Velocity(高速)
3、Variety(多样)
4、Value(低价值密度)
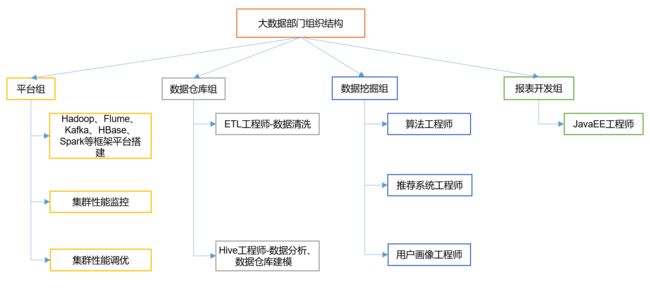
1.3 大数据部门组织结构
第二章 Hadoop框架
2.1 Hadoop是什么
2.2 Hadoop的优势
2.3 Hadoop2.0的组成
(1)HDFS架构
(2)YARN架构概述
(3)MapReduce架构概述
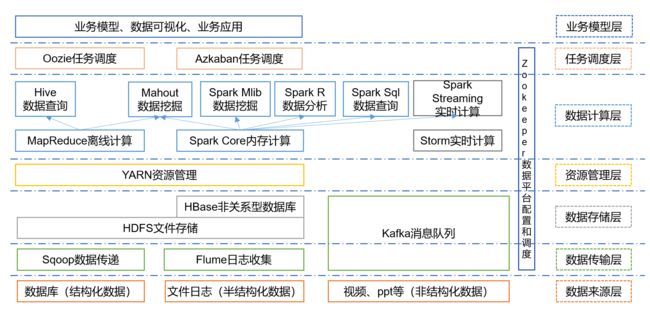
2.4 大数据技术生态体系
第三章 Hadoop运行环境搭建(完全分布式)
3.1 准备三台虚拟机
(1)创建虚拟机(在VMware中单击:文件->新建虚拟机)
(2)登录linux修改ip和用户名配置映射
(3)使用yum安装,需要虚拟机可以正常上网
(4)安装epel-release
(5)安装net-tool工具包集合里面包含ifconfig等命令
(6)测试ifconfig
(7)关闭防火墙,关闭防火墙开机自启
(8)在/opt目录下创建module、software文件夹
(9)重启虚拟机
3.2 克隆虚拟机
(1)右击master->管理->克隆
(2)修改克隆机IP,以slave1举例
(3)修改克隆机主机名,以slave1举例
(4)重启虚拟机slave1(reboot)
3.3 在master安装JDK
(1)用FinalShell传输工具将JDK和Hadoop导入到opt目录下的software文件夹下面
(2)解压JDK到/opt/module目录下
(3)查看JDK
(4)配置JDK环境变量
3.4 在master安装Hadoop
(1)将/opt/software目录下的hadoop-2.7.7解压到/opt/module
(2)查看是否解压成功
(3)添加Hadoop的环境变量
(4)让修改后的文件生效
(5)测试是否安装成功
3.5 完全分布式运行模式
(1)配置ssh免密登录
(2)编写集群分发脚本xsync(同步)
(3)配置集群
第一章 大数据概述
1.大数据概念
大数据(Big Data) :指无去在一定时间范围内用常规软件工具进行捕捉、管理和处理的数居集合,是需要新处理模式才能具有更强的央策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
主要解决,海量数据的存储和海量数据的分析问题。
1.2、大数据特点
1、Volume(大量)
截至目前,人类生产的所有印刷材半料的教据量是200 PB,而历史上全人类总共说过的话的数据量大约是5EB。当前,典型个人计算机硬盘的容量为TB量级,而-些大企业的数居量已经接近B量级.
2、Velocity(高速)
这是大数据区分于专统澎对居挖掘的最显著特征.根据IDC的“数字宇宙”的报告,预十到2020年,全球数据使用量将达到35.2ZB.在如此海量的数据面前,处理数据日的交效率就是企业的生命.
3、Variety(多样)
这种类型的多样性也让数据被分为结构化数据和非结构化教据。相对于以往便于存储的以数据库/文本为主的结构化数据,非结构化数据越来越多,包括网络日志音频、视频烦、图片、地理位置信息等,这些多类型的据对数据的处理能力提出了更高要求。
4、Value(低价值密度)
价值密度的高低与教居总量的大小成反比。比如,在一天监控视烦中,我们只关心宋宋老师晚上在床上健身那—分钟,女何快速对有价值教据“提纯”成为目前大数居背景下待解央的难是题。 价值密度的高低与教居总量的大小成反比.比如,在一天监控视烦中,我们只关心宋宋老师晚上在床上健身那-分钟,女何快速对有价值教据“提纯”成为目前大数居背景下待解央的难是题.
1.3 大数据部门组织结构
大数据部门组织结构,适用于大中型企业
第二章 Hadoop框架
2.1 Hadoop是什么
(1) Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
(2)主要解决,海量教据的存情和海量教据的分析计算问题。
(3)广义上来说,Hadoop通常是指一个更广泛的概念———Hadoop生态圈。
2.2 Hadoop的优势
(1)高可靠性: Hadoop底层维户多个数据副本,所以即使Hadoop某个计算元素或存储山现故障,也不会导致数据的丢失。
(2)高扩展性:在集群间分配任务数据,可方便的扩广展以千计的节点。
(3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
(4)高容错性:能够自动将失败的任务重新分配。
2.3 Hadoop2.0的组成
(1)HDFS架构
NameNode (rm):存情文件的元数据,如文件名,文件目录结构,文件国性〈生成时间、倒本数.文件权限),以及每个文件的块列去和块所在的DataNode等。
DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
Seccnday NameNode(2nm):用来监控HDFS状志的辅助后合程序,每隔一段时间获取HDFS元数据的快照。
(2)YARN架构概述

(3)MapReduce架构概述
MapReduce将计算过程分为两个阶段: Map和Reduce
Map阶段并行处理输入数据
Reduce阶段对Map结果进行汇总
2.4 大数据技术生态体系
第三章 Hadoop运行环境搭建(完全分布式)
3.1 准备三台虚拟机
(1)创建虚拟机(在VMware中单击:文件->新建虚拟机)


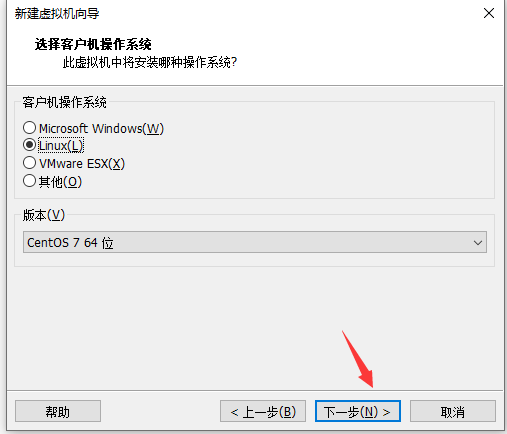
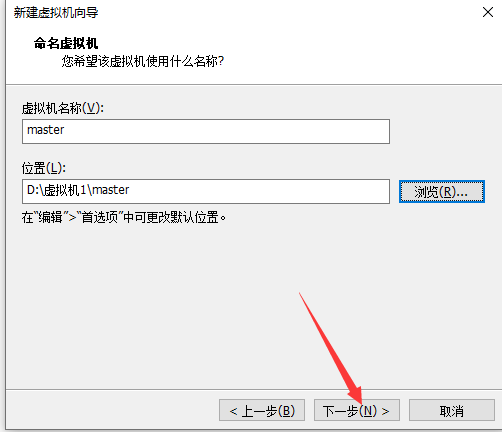





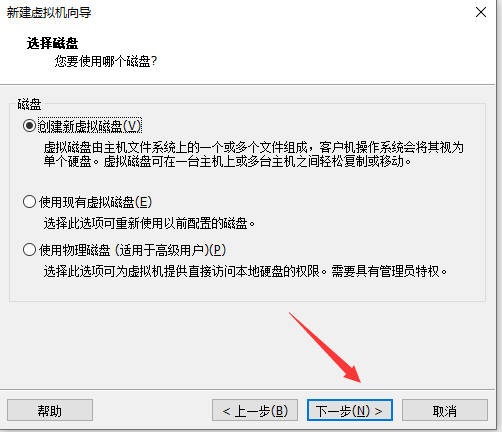



单击编辑虚拟机设置(选择centos镜像)然后开启虚拟机
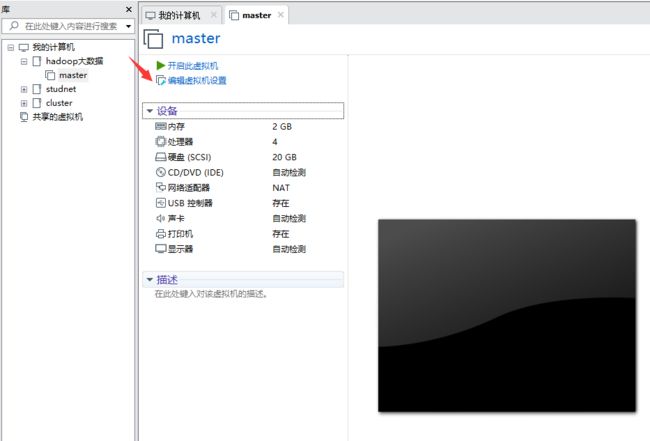
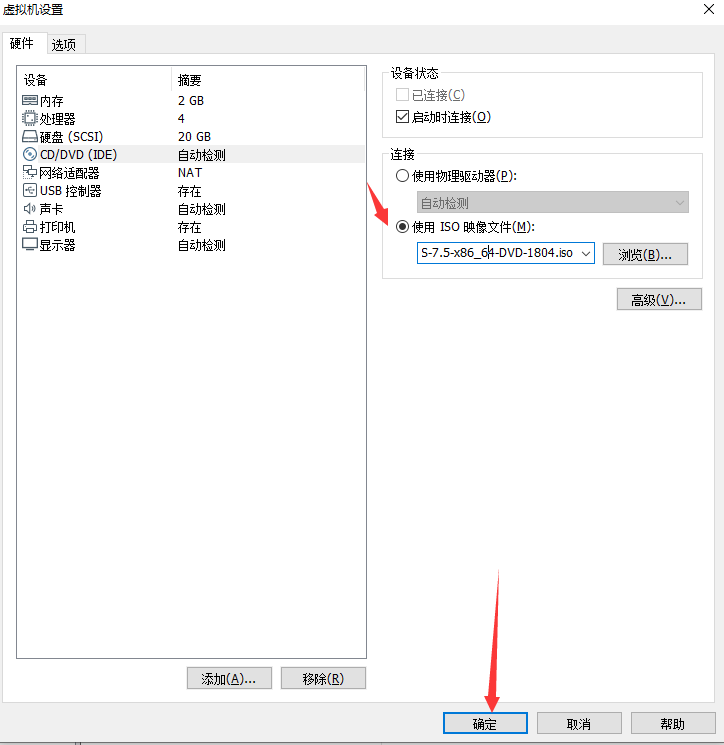

单击软件选择
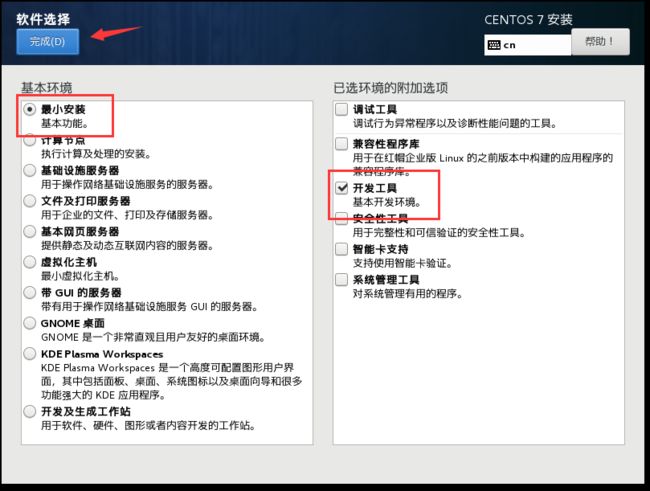
单击安装位置选择完成(默认即可)
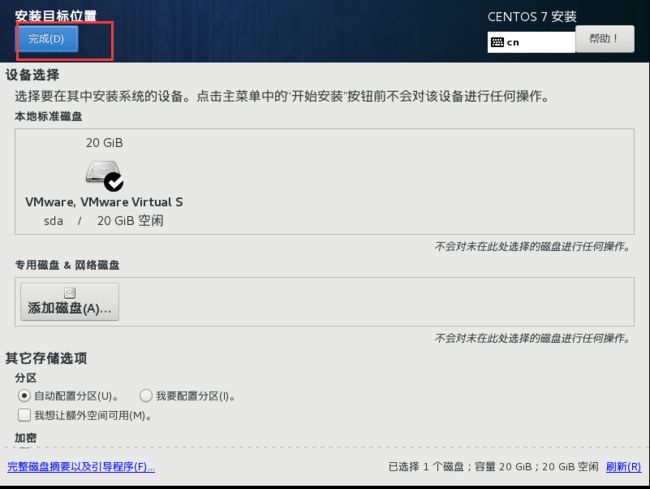
点击开始安装(设置root密码)
 安装完后会让我们重启一下
安装完后会让我们重启一下

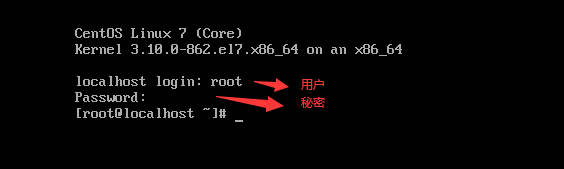
(2)登录linux修改ip和用户名配置映射
修改BOOTPROTO=static
修改ONBOOT=yes
增加ip :192.168.10.20
增加网关:192.168.10.2
增加DNS1:192.168.10.2


保存退出
:wq
修改用户名

增加映射(vi /etc/hosts)

reboot(重启虚拟机)
(3)使用yum安装,需要虚拟机可以正常上网(如果不能正常上网的话看下一节克隆虚拟机)
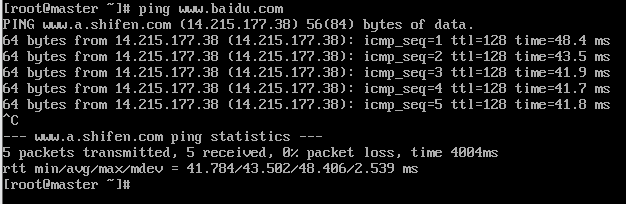
(4)安装epel-release

(5)安装net-tool工具包集合里面包含ifconfig等命令
![]()
(6)测试ifconfig
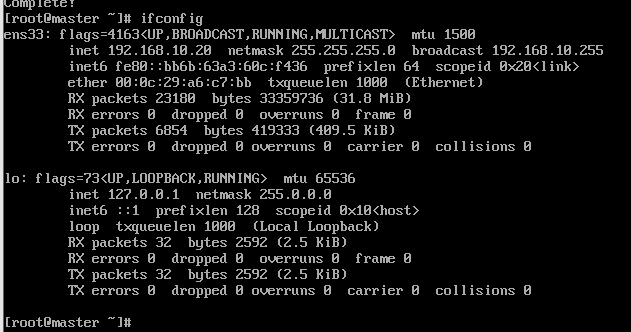
(7)关闭防火墙,关闭防火墙开机自启
 ()
()
(8)在/opt目录下创建module、software文件夹
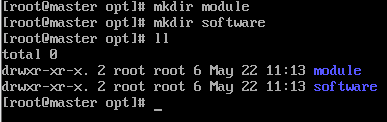
(9)重启虚拟机
![]()
3.2 克隆虚拟机
注意:克隆时要关闭虚拟机
(1)右击master->管理->克隆
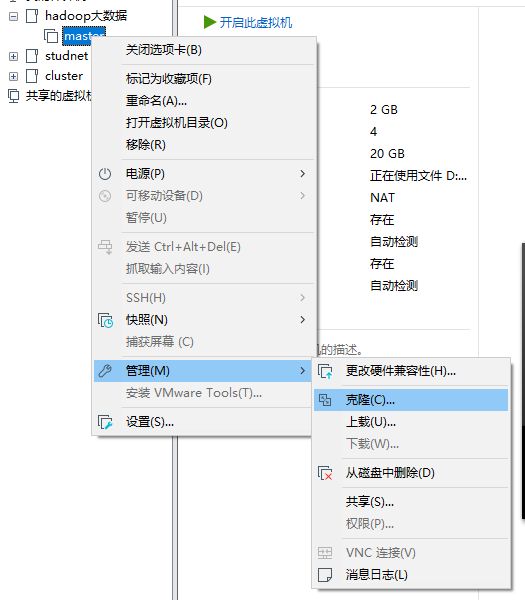

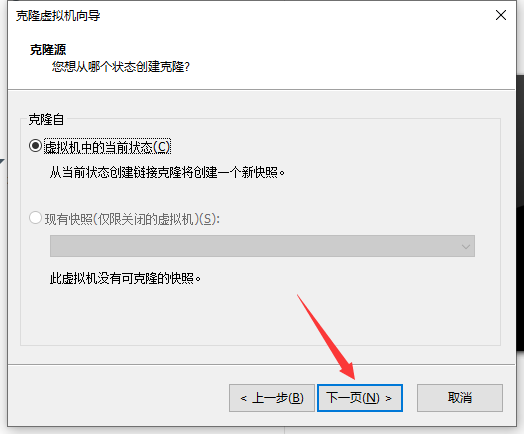

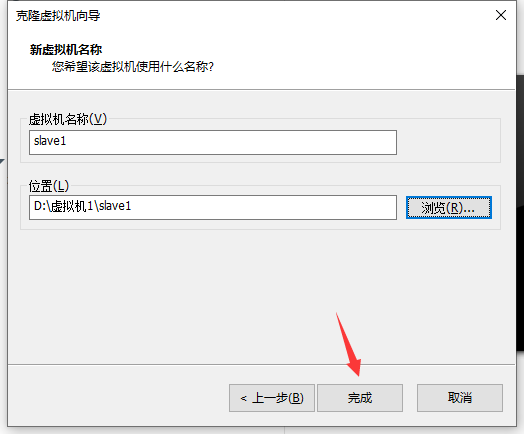
(2)修改克隆机IP,以slave1举例
(2.1)修改克隆虚拟机的静态IP
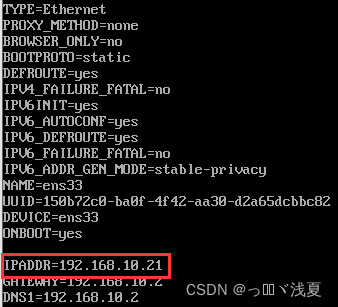
(2.2)查看Linux虚拟机的虚拟网络编辑器,编辑->虚拟网络编辑器->VMnet8


(2.3)查看Windows系统适配器VMwareNetworkAdapter VMnet8的IP地址
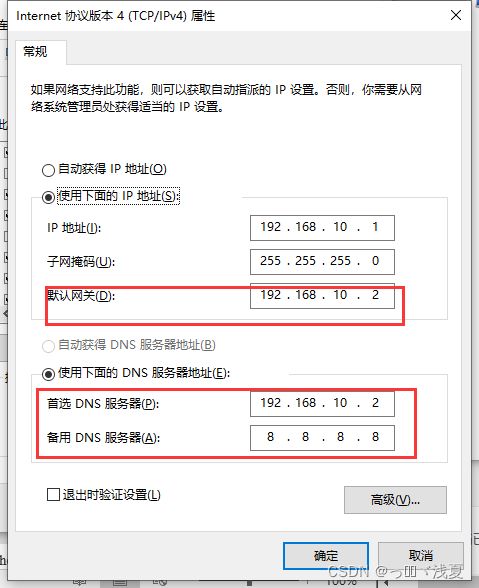
(2.4)保证Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和windows系统VM8网络IP地址相同。
(3)修改克隆机主机名,以slave1举例
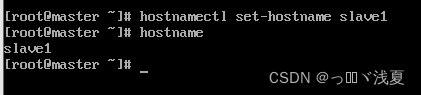
(4)重启虚拟机slave1(reboot)
![]()
3.3 在master安装JDK
(1)用FinalShell传输工具将JDK和Hadoop导入到opt目录下的software文件夹下面
https://www.onlinedown.net/iopdfbhjl/10009193?module=download&t=website
使用rz从本地上传到/opt/software目录下

(2)解压JDK到/opt/module目录下
![]()
(3)查看JDK

(4)配置JDK环境变量
(4.1)新建/etc/profile.d/my_env.sh文件
![]()
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_162
export PATH=$PATH:$JAVA_HOME/bin
(2)source 一下/etc/profile文件,让新的环境变量PATH生效
[root@master jdk1.8.0_162]# source /etc/profile
(3) 测试JDK是否安装成功

3.4 在master安装Hadoop
Hadoop下载:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/
(1)将/opt/software目录下的hadoop-2.7.7解压到/opt/module
[root@master software]# tar -zxvf hadoop-2.7.7.tar.gz -C /opt/module/
(2)查看是否解压成功

(3)添加Hadoop的环境变量
在/etc/profile.d/my_env.sh文件下添加:
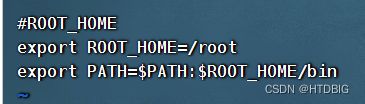
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存并退出::wq
(4)让修改后的文件生效
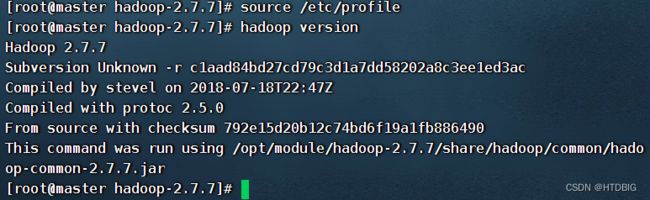
[root@master hadoop-2.7.7]# source /etc/profile
(5)测试是否安装成功
3.5 完全分布式运行模式
(1)配置ssh免密登录
- 生成公钥和私钥
[root@master ~]# ssh-keygen -t rsa
然后敲三个回车,就会生成两个文件id_rsa (私钥)、id_rsa.pub(公钥)

2、将公钥拷贝到免密登录的机器上
[root@master ~]# ssh-copy-id master
[root@master ~]# ssh-copy-id slave1[root@master ~]# ssh-copy-id slave2
注意:还需要在slave1无密配置登录到master、slave1、slave2
还需要在slave2无密配置登录到master、slave1、slave2
(2)编写集群分发脚本xsync(同步)
[root@master ~]# yum -y install rsync
在家目录创建bin文件
echo $PATH查看roo/bin;配置环境变量没

如果没有扑·这个/root/bin(以下方法)
[root@master bin]# vi /etc/profile.d/my_env.sh
在此文件里加入下面的环境变量
在bin里创建vi xsync
[root@master bin]# vi xsync
在此文件里面加入
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi#2. 遍历集群所有机器
for host in master slave1 slave2
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
给该脚本赋予执行权限
[root@master bin]# chmod 777 xsync

测试脚本
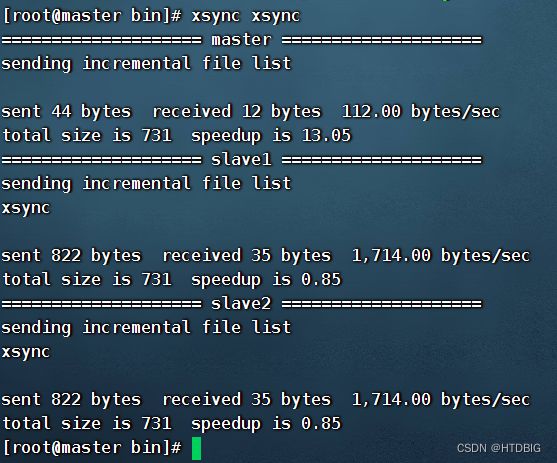
查看是否同步成功

(3)配置集群

1、核心配置文件
配置core-site.xml
[root@master hadoop]# vi core-site.xml
在该文件中编写如下配置
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.7/data/tmp
2.HDFS配置文件
配置hadoop-env.sh
在该文件下添加
[root@master hadoop]# vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_162
配置hdfs-site.xml
[root@master hadoop]# vi hdfs-site.xml
在该文件中编写如下配置
dfs.replication
3
dfs.namenode.secondary.http-address
master:50090
3、YARN配置文件
配置yarn-env.sh
[root@master hadoop]# vi yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_162
配置yarn-site.xml
[root@master hadoop]# vi yarn-site.xml
再改文件中增加如下配置
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
master
4、MapReduce配置文件
配置mapred-site.xml
[root@master hadoop]# vi mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_162
配置mapred-site.xml
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
在该文件下增加如下配置
mapreduce.framework.name
yarn
(5)配置slaves
[root@master hadoop]# vi slaves

:wq
(6)在集群上分发hadoop配置文件和分发环境变量
[root@master opt]# xsync module/
[root@master opt]# xsync /etc/profile.d/my_env.sh

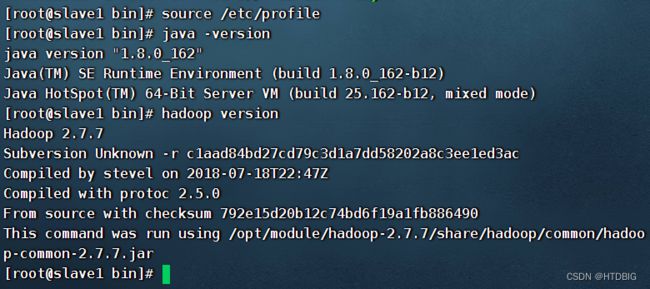
source一下slave1、slave2的环境变量,让其生效(以slave1为例)
(7)格式化NameNode
[root@master hadoop-2.7.7]# hdfs namenode -format
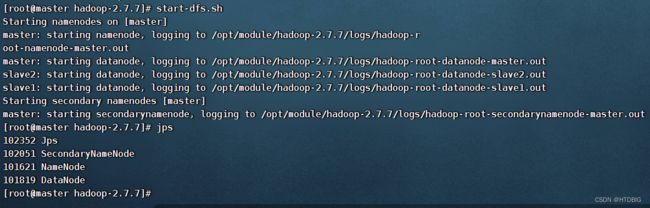
(8)启动HDFS
[root@master hadoop-2.7.7]# start-dfs.sh
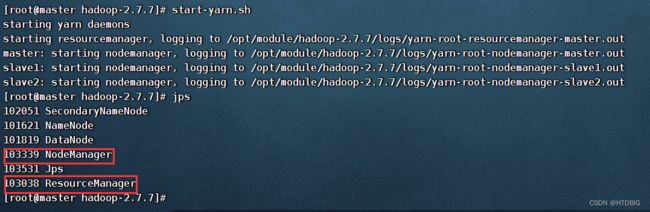
(9)启动yarn
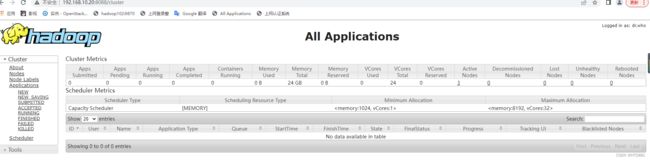
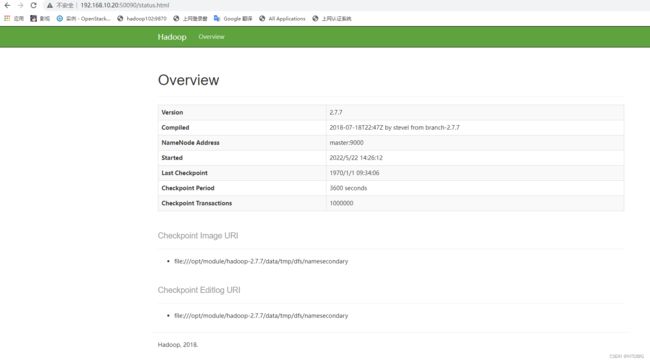
 (10)在web端查看(http://master:50090)
(10)在web端查看(http://master:50090)
(http://master:8088)(还不出来的话用虚拟机IP)