深度学习时代的多源域适应 : 系统的 Survey
Multi-source Domain Adaptation in the Deep Learning Era: A Systematic Survey

[paper]
目录
Multi-source Domain Adaptation in the Deep Learning Era: A Systematic Survey
Abstract
Background and Motivation
Problem Definition
MDA 的分类学方法:
Datasets
Deep Multi-source Domain Adaptation
Latent Space Transformation
Intermediate Domain Generation
Abstract
In many practical applications, it is often difficult and expensive to obtain enough large-scale labeled data to train deep neural networks to their full capability. Therefore, transferring the learned knowledge from a separate, labeled source domain to an unlabeled or sparsely labeled target domain becomes an appealing alternative. However, direct transfer often results in significant performance decay due to domain shift. Domain adaptation (DA) addresses this problem by minimizing the impact of domain shift between the source and target domains. Multi-source domain adaptation (MDA) is a powerful extension in which the labeled data may be collected from multiple sources with different distributions. Due to the success of DA methods and the prevalence of multi-source data, MDA has attracted increasing attention in both academia and industry. In this survey, we define various MDA strategies and summarize available datasets for evaluation. We also compare modern MDA methods in the deep learning era, including latent space transformation and intermediate domain generation. Finally, we discuss future research directions for MDA.
MDA 概念的介绍:
在许多实际应用中,获取足够的大规模标记数据来训练深度神经网络,使其充分发挥其功能往往是困难和昂贵的。因此,将学到的知识从一个单独的、标记的源领域转移到一个未标记或标记稀疏的目标领域成为一个有吸引力的替代方案。然而,直接传输常常会由于域转移而导致显著的性能下降。领域自适应 (DA) 通过最小化源领域和目标领域之间的领域转移的影响来解决这个问题。多源领域适应 (MDA) 是一个强大的扩展,它可以从不同分布的多个源收集标记数据。由于DA方法的成功和多源数据的流行,MDA 越来越受到学术界和业界的关注。
本文的工作内容:
在本调查中,本文归纳了各种 MDA 策略,并总结了可用的数据集以进行评估。本文还比较了深度学习的 MDA 方法,包括潜变量空间变换和中间域生成。最后,对 MDA 今后的研究方向进行了展望。
Background and Motivation
The availability of large-scale labeled training data, such as ImageNet, has enabled deep neural networks (DNNs) to achieve remarkable success in many learning tasks, ranging from computer vision to natural language processing. For example, the classification error of the “Classification + localization with provided training data” task in the Large Scale Visual Recognition Challenge has reduced from 0.28 in 2010 to 0.0225 in 2017 , outperforming even human classification. However, in many practical applications, obtaining labeled training data is often expensive, time-consuming, or even impossible. For example, in fine-grained recognition, only the experts can provide reliable labels [Gebru et al., 2017]; in semantic segmentation, it takes about 90 minutes to label each Cityscapes image [Cordts et al., 2016]; in autonomous driving, it is difficult to label point-wise 3D LiDAR point clouds [Wu et al., 2019].
领域自适应要解决的实际应用问题:实际应用中,数据标记是非常复杂和困难的。列举了 细粒度识别(标签需要专家级别的工作人员)、Cityspaces(90分钟标记一张语义分割)和 3D LiDAR(像素级点云标记太困难了)。
One potential solution is to transfer a model trained on a separate, labeled source domain to the desired unlabeled or sparsely labeled target domain. But as Figure 1 demonstrates, the direct transfer of models across domains leads to poor performance. Figure 1(a) shows that even for the simple task of digit recognition, training on the MNIST source domain [LeCun et al., 1998] for digit classification in the MNIST-M target domain [Ganin and Lempitsky, 2015] leads to a digit classification accuracy decrease from 96.0% to 52.3% when training a LeNet-5 model [LeCun et al., 1998]. Figure 1(b) shows a more realistic example of training a semantic segmentation model on a synthetic source dataset GTA [Richter et al., 2016] and conducting pixel-wise segmentation on a real target dataset Cityscapes [Cordts et al., 2016] using the FCN model [Long et al., 2015a]. If we train on the real data, we obtain a mean intersection-over-union (mIoU) of 62.6%; but if we train on synthetic data, the mIoU drops significantly to 21.7%.
Figure 1: An example of domain shift in the single-source scenario. The models trained on the labeled source domain do not perform well when directly transferring to the target domain.
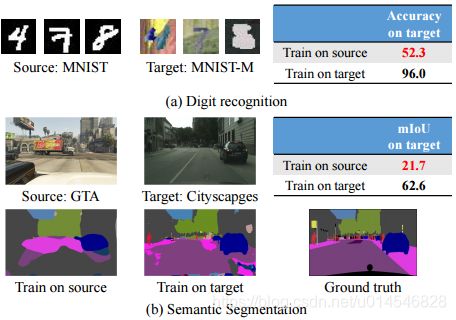
领域自适应要面临的实际算法问题:为了解决标记难的问题,能想到的方法就是,在有标签的域(数据集)上训练,然后在目标域(另一个数据集)上测试,这种方法可以看做是直接的目标迁移方式。但是直接迁移会导致性能下降。如图 1 所示(a),在 MNIST 域上训练的模型,在 MNIST-M 上测试的准确度为 52.3,远低于在 MNIST-M 训练的模型在该域的准确度 96.0。在图 1 (b)中的语义分割中,亦是如此。
The poor performance from directly transferring models across domains stems from a phenomenon known as domain shift [Torralba and Efros, 2011; Zhao et al., 2018b]: whereby the joint probability distributions of observed data and labels are different in the two domains. Domain shift exists in many forms, such as from dataset to dataset, from simulation to real-world, from RGB images to depth, and from CAD models to real images.、
解释图 1 问题的原因:
跨域直接传输模型的糟糕性能源于一种称为域迁移的现象 [Torralba和Efros, 2011;Zhao et al.,2018b]:据此观测数据和标签在两个域的联合概率分布不同。领域迁移存在多种形式,如从数据集到数据集,从仿真到真实世界,从 RGB 图像到 深度,从 CAD 模型到真实图像。
The phenomenon of domain shift motivates the research on domain adaptation (DA), which aims to learn a model from a labeled source domain that can generalize well to a different, but related, target domain. Existing DA methods mainly focus on the single-source scenario. In the deep learning era, recent single-source DA (SDA) methods usually employ a conjoined architecture with two approaches to respectively represent the models for the source and target domains. One approach aims to learn a task model based on the labeled source data using corresponding task losses, such as cross-entropy loss for classification. The other approach aims to deal with the domain shift by aligning the target and source domains. Based on the alignment strategies, deep SDA methods can be classified into four categories:
1. Discrepancy-based methods try to align the features by explicitly measuring the discrepancy on corresponding activation layers, such as maximum mean discrepancy (MMD) [Long et al., 2015b], correlation alignment [Sun et al., 2017], and contrastive domain discrepancy [Kang et al., 2019].
2. Adversarial generative methods generate fake data to align the source and target domains at pixel-level based on Generative Adversarial Network (GAN) [Goodfellow et al., 2014] and its variants, such as CycleGAN [Zhu et al., 2017; Zhao et al., 2019b].
3. Adversarial discriminative methods employ an adversarial objective with a domain discriminator to align the features [Tzeng et al., 2017; Tsai et al., 2018].
4. Reconstruction based methods aim to reconstruct the target input from the extracted features using the source task model [Ghifary et al., 2016].
单一源域领域自适应介绍和分类:
1. Discrepancy-based methods:基于离散的方法试图通过显式测量相应激活层上的差异来对齐特征,例如最大平均差异 (MMD) [Long et al., 2015b]、相关对齐 [Sun et al., 2017] 和对比域差异 [Kang et al., 2019]。
2. Adversarial generative methods:对抗生成方法基于生成对抗网络 (GAN) [Goodfellow et al., 2014] 及其变体,如 CycleGAN [Zhu et al., 2017; Zhao et al.,2019b]。
3. Adversarial discriminative methods:对抗判别方法利用一个对抗目标和一个域判别器来对齐特征 [Tzeng et al.,2017; Cai et al.,2018]。
4. Reconstruction based methods:基于重构的方法旨在利用源任务模型从提取的特征中重构目标输入 [Ghifary et al.,2016]。
In practice, the labeled data may be collected from multiple sources with different distributions [Sun et al., 2015; Bhatt et al., 2016]. In such cases, the aforementioned SDA methods could be trivially applied by combining the sources into a single source: an approach we refer to as sourcecombined DA. However, source-combined DA oftentimes results in a poorer performance than simply using one of the sources and discarding the others. As illustrated in Figure 2, the accuracy on the best single source digit recognition adaptation using DANN [Ganin et al., 2016] is 71.3%, while the source-combined accuracy drops to 70.8%. For segmentation adaptation using CyCADA [Hoffman et al., 2018b], the mIoU of source-combined DA (37.3%) is also lower than that of SDA from GTA (38.7%). Because the domain shift not only exists between each source and target, but also exists among different sources, the source-combined data from different sources may interfere with each other during the learning process [Riemer et al., 2019]. Therefore, multi-source domain adaptation (MDA) is needed in order to leverage all of the available data.
Figure 2: An example of domain shift in the multi-source scenario. Combining multiple sources into one source and directly performing single-source domain adaptation on the entire dataset does not guarantee better performance compared to just using the best individual source domain.

实际中,被标签的数据集(源域)可能不止一个哦,这就诞生了 多源域领域自适应,MDA。
多源域,是不是就简单地混合训练多个域(将多种数据集混合在一起,作为训练数据集)训练模型,就可以了呢?直觉地,混合域下训练的模型具备更泛化的能力,但实验结果并非如此。
以数字识别图 2(a)为例,分别在四个有标签的源域上分别训练出 4 个模型,然后分别在 MNIST-M 目标域上进行测试,最好的一个获得 71.3 的准确性;当把这四个源域混合起来,训练出一个新的模型,直觉地,这个混合训练出来的模型泛化能力应该更强,然而其在目标域上的测试,反不如单源训练最好的一组。这就说明,想通过简单混合数据集的方法,并不可行。
语义分割的例子也说明了这点。
因此,可以看出,域迁移是一个非常重要的研究领域。
The early MDA methods mainly focus on shallow models [Sun et al., 2015], either learning a latent feature space for different domains [Sun et al., 2011; Duan et al., 2012] or combining pre-learned source classifiers [Schweikert et al., 2009]. Recently, the emphasis on MDA has shifted to deep learning architectures. In this paper, we systematically survey recent progress on deep learning based MDA, summarize and compare similarities and differences in the approaches, and discuss potential future research directions.
早期的 MDA 方法主要针对浅层模型 [Sun et al., 2015],要么学习不同域的潜特征空间 [Sun et al., 2011;Duan et al,2012 ] 或 结合预先学习的源分类器 [Schweikert et al.,2009]。最近,MDA 的重点已经转移到深度学习架构上。本文系统地综述了基于 MDA 的深度学习研究的最新进展,总结比较了各种方法的异同,并对未来可能的研究方向进行了探讨。
Problem Definition
在一个经典的 MDA 中,定义如下几个符号:
多源域:multiple source domains ![]() ,M 表示源域的总个数;
,M 表示源域的总个数;
源域中的样本为:![]() ,X 是数据,Y 是标签(GT);i 表示第 i 个域;N 表示 该域中样本个数;j 表示该域中的第 j 个样本;
,X 是数据,Y 是标签(GT);i 表示第 i 个域;N 表示 该域中样本个数;j 表示该域中的第 j 个样本;
目标域中的样本:![]() 和
和 ![]() ;N 表示 该域中样本个数。
;N 表示 该域中样本个数。
MDA 的分类学方法:
1. 估计目标域中,被标记样本的个数,可分为 无监督,监督和半监督:
Suppose the number of labeled target samples is ![]() , the MDA problem can be classified into different categories:
, the MDA problem can be classified into different categories:
• unsupervised MDA, when ![]() = 0;
= 0;
• fully supervised MDA, when ![]() = NT ;
= NT ;
• semi-supervised MDA, otherwise.
2. 根据源域是否来自相同域,可分为 同构和异构 MDA:
Suppose ![]() are an observation in source Si and target T, we can classify MDA into:
are an observation in source Si and target T, we can classify MDA into:
• homogeneous MDA, when d1 = · · · = dM = dT ;
• heterogeneous MDA, otherwise.
3. 根据 源域中标签 是否在 目标域 中出现,可分为 closed set,open set,partial 和 universal MDA 四类:
Suppose Ci and CT are the label set for source Si and target T, we can define different MDA strategies:
• closed set MDA, when C1 = · · · = CM = CT ;
• open set MDA, for at least one Ci , Ci ∩ CT ⊂ CT ;
• partial MDA, for at least one Ci , CT ⊂ Ci ;
• universal MDA, when no prior knowledge of the label sets is available;
where ∩ and ⊂ indicate the intersection set and proper subset between two sets
4. 根据源域中样本与标记样本个数是否相同,可分为 强监督和弱监督 MDA:
Suppose the number of labeled source samples is ![]() for source Si , the MDA problem can be classified into:
for source Si , the MDA problem can be classified into:
• strongly supervised MDA, when ![]() for i = 1 · · · M;
for i = 1 · · · M;
• weakly supervised MDA, otherwise
When adapting to multiple target domains simultaneously, the task becomes multi-target MDA. When the target data is unavailable during training [Yue et al., 2019], the task is often called multi-source domain generalization or zero-shot MDA.
当同时适应多个目标域时,任务就变成了多目标MDA。当训练期间目标数据不可用时 [Yue et al., 2019],该任务通常被称为多源域泛化或 zero-shot MDA。
Datasets
这部分先略过不讲了,一方面这节内容易懂,没啥可讲;另外,根据自己研究相关领域查看即可,没必要通读。可参考原文:https://arxiv.org/pdf/2002.12169.pdf
直接跳到算法介绍章节吧。
Deep Multi-source Domain Adaptation
Existing methods on deep MDA primarily focus on the unsupervised, homogeneous, closed set, strongly supervised, one target, and target data available settings. That is, there is one target domain, the target data is unlabeled but available during the training process, the source data is fully labeled, the source and target data are observed in the same data space, and the label sets of all sources and the target are the same. In this paper, we focus on MDA methods under these settings.
现有的深层 MDA 方法主要集中于无监督、同构、封闭集、强监督、单目标和目标数据有标签。即存在一个目标域,在训练过程中,目标数据未标记但可用,源数据被完全标记,源数据和目标数据在同一数据空间中观察,所有源数据和目标的标签集相同。本文只涉及上述几种 MDA 方法。
There are some theoretical analysis to support existing MDA algorithms. Most theories are based on the seminal theoretical model [Blitzer et al., 2008; Ben-David et al., 2010]. Mansour et al. [2009] assumed that the target distribution can be approximated by a mixture of the M source distributions. Therefore, weighted combination of source classifiers has been widely employed for MDA. Moreover, tighter cross domain generalization bound and more accurate measurements on domain discrepancy can provide intuitions to derive effective MDA algorithms. Hoffman et al. [2018a] derived a novel bound using DC-programming and calculated more accurate combination weights. Zhao et al. [2018a] extended the generalization bound of seminal theoretical model to multiple sources under both classification and regression settings. Besides the domain discrepancy between the target and each source [Hoffman et al., 2018a; Zhao et al., 2018a], Li et al. [2018] also considered the relationship between pairwise sources and derived a tighter bound on weighted multi-source discrepancy. Based on this bound, more relevant source domains can be picked out.
本文对现有的 MDA 算法进行了理论分析。大多数理论都是基于开创性的理论模型 [Blitzer et al., 2008;Ben-David et al.,2010]。Mansour et al.[2009] 假设目标分布可以通过混合的 M 源分布来近似。因此,加权的源分类器组合已被广泛应用于 MDA 分类。此外,更紧密的跨域泛化界和更精确的域差异度量可以为推导有效的 MDA 算法提供直观的依据。Hoffman et al.[2018a] 使用 DC-programming 推导出一个新的界,并计算出更精确的组合权值。Zhao et al.[2018a] 将开创性理论模型的泛化范围扩展到分类和回归设置下的多个来源。除了目标和每个源之间的域差异之外 [Hoffman et al.,2018a;Zhao et al.,2018a], Li et al.[2018] 也考虑了两两源之间的关系,推导了加权多源差异的更紧界。基于这个边界,可以挑选出更多相关的源域。
Typically, some task models (e.g. classifiers) are learned based on the labeled source data with corresponding task loss, such as cross-entropy loss for classification. Meanwhile, specific alignments among the source and target domains are conducted to bridge the domain shift so that the learned task models can be better transferred to the target domain. Based on the different alignment strategies, we can classify MDA into different categories. Latent space transformation tries to align the latent space (e.g. features) of different domains based on optimizing the discrepancy loss or adversarial loss. Intermediate domain generation explicitly generates an intermediate adapted domain for each source that is indistinguishable from the target domain. The task models are then trained on the adapted domain. Figure 3 summarizes the common overall framework of existing MDA methods.
Figure 3: Illustration of widely employed framework for MDA. The solid arrows and dashed dot arrows indicate the training of latent space transformation and intermediate domain generation, respectively. The dashed arrows represent the reference process. Most existing MDA methods can be obtained by employing different component details, enforcing some constraints, or slightly changing the architecture. Best viewed in color.
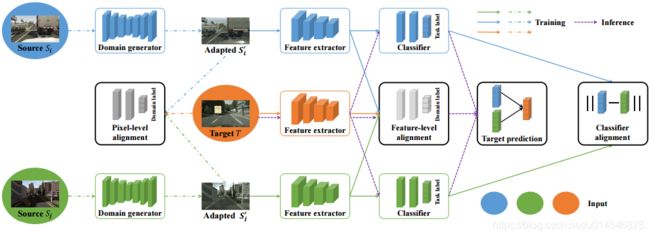
通常,一些任务模型 (如分类器) 是基于标记好的源数据进行学习的,这些数据具有相应的任务损失,如交叉熵损失用于分类。同时,对源领域和目标领域进行具体的对齐,以桥接领域迁移,使学习到的任务模型能够更好地转移到目标领域。根据不同的对齐策略,可以将 MDA 划分为不同的类别。隐含层空间变换 试图通过优化差异损失或对抗损失来对齐不同域的潜空间(如特征)。中间域生成 显式地为每个与目标域不可区分的源生成一个中间适应域。然后,任务模型在适应的领域上进行训练。图 3 总结了现有 MDA 方法的通用总体框架。
Latent Space Transformation
The two common methods for aligning the latent spaces of different domains are discrepancy-based methods and adversarial methods. We discuss these two methods below, and Table 2 summarizes key examples of each method.
对齐不同域隐含在空间的两种常用方法是基于离散的方法和对抗的方法。下面我讨论这两种方法,表 2 总结了每种方法的关键示例。
Discrepancy-based methods explicitly measure the discrepancy of the latent spaces (typically features) from different domains by optimizing some specific discrepancy losses, such as maximum mean discrepancy (MMD) [Guo et al., 2018; Zhu et al., 2019], Renyi-divergence ´ [Hoffman et al., 2018a], L2 distance [Rakshit et al., 2019], and moment distance [Peng et al., 2019]. Guo et al. [2020] claimed that different discrepancies or distances can only provide specific estimates of domain similarities and that each distance has its pathological cases. Therefore, they consider the mixture of several distances [Guo et al., 2020], including L2 distance, Cosine distance, MMD, Fisher linear discriminant, and Correlation alignment. Minimizing the discrepancy to align the features among the source and target domains does not introduce any new parameters that must be learned.
基于离散的方法通过优化一些特定的差异损失,显式地测量来自不同域的隐含空间 (典型特征) 的差异,如最大平均差异(MMD) [Guo et al., 2018;Renyi-divergence [Hoffman et al., 2018a], L2 距离[Rakshit et al., 2019], moment distance [Peng et al., 2019]。Guo et al.[2020] 认为不同的差异或距离只能提供域相似性的具体估计,每个距离都有其病态情况。因此,他们考虑了几种距离的混合[Guo et al., 2020],包括 L2 距离、余弦距离、MMD、Fisher 线性判别和相关对齐。最小化差异以对齐源和目标域之间的特性不会引入任何必须学习的新参数。
Adversarial methods try to align the features by making them indistinguishable to a discriminator. Some representative optimized objectives include GAN loss [Xu et al., 2018], H-divergence [Zhao et al., 2018a], Wasserstein distance [Li et al., 2018; Wang et al., 2019; Zhao et al., 2020]. These methods aim to confuse the discriminator’s ability to distinguishing whether the features from multiple sources were drawn from the same distribution. Compared with GAN loss and H-divergence, Wasserstein distance can provide more stable gradients even when the target and source distributions do not overlap [Zhao et al., 2020]. The discriminator is often implemented as a network, which leads to new parameters that must be learned.
There are many modular implementation details for both types of methods, such as how to align the target and multiple sources, whether the feature extractors are shared, how to select the more relevant sources, and how to combine the multiple predictions from different classifiers.
对抗方法试图通过使特征与判别器无法区分来对齐特征。一些有代表性的优化目标包括 GAN loss [Xu et al.,2018]、H-divergence [Zhao et al.,2018a]、Wasserstein distance [Li et al.,2018;Wang et al.,2019;Zhao et al.,2020]。这些方法的目的是混淆判别器区分来自多个源的特征是否来自同一分布的能力。与 GAN 损失和 H 散度相比,即使目标和源分布不重叠,Wasserstein 距离也能提供更稳定的梯度 [Zhao et al., 2020]。判别器通常被实现为一个网络,这导致了必须学习的新参数。
Alignment domains. There are different ways to align the target and multiple sources. The most common method is to pairwise align the target with each source [Xu et al., 2018; Guo et al., 2018; Zhao et al., 2018a; Hoffman et al., 2018a; Zhu et al., 2019; Zhao et al., 2020; Guo et al., 2020]. Since domain shift also exists among different sources, several methods enforce pairwise alignment between every domain in both the source and target domains [Li et al., 2018; Rakshit et al., 2019; Peng et al., 2019; Wang et al., 2019].
对齐域。有不同的方法来对齐目标和多个源。最常见的方法是将目标与每个源成对对齐 [Xu et al.,2018;Guo et al.,2018;Zhao et al.,2018a;霍夫曼 et al.,2018a;Zhu et al.,2019;Zhao et al.,2020;Guo et al.,2020]。由于不同源之间也存在域移动,有几种方法强制源和目标域中每个域之间的成对对齐 [Li et al.,2018;Rakshit et al.,2019年;Peng et al., 2019;Wang et al.,2019]。
Weight sharing of feature extractor. Most methods employ shared feature extractors to learn domain-invariant features. However, domain invariance may be detrimental to discriminative power. On the contrary, Rakshit et al. [2019] adopted one feature extractor for each source and target pair with unshared weights, while Zhao et al. [2020] first pretrained one feature extractor for each source and then mapped the target into the feature space of each source. Correspondingly, there are M and 2M feature extractors. Although unshared feature extractors can better align the target and sources in the latent space, this substantially increases the number of parameters in the model.
特征提取器的权重共享。大多数方法采用共享特征提取器来学习域不变特征。然而,域不变性可能不利于区分能力的发挥。相反,Rakshit et al. [2019]对每个源和目标对采用一个权值不共享的特征提取器,而 Zhao et al. [2020]首先为每个源预先训练一个特征提取器,然后将目标映射到每个源的特征空间。对应的特征提取器有 M 个和 2M 个。尽管非共享特征提取器可以更好地在潜在空间中对齐目标和源,但这大大增加了模型中的参数数量。
Classifier alignment. Intuitively, the classifiers trained on different sources may result in misaligned predictions for the target samples that are close to the domain boundary. By minimizing specific classifier discrepancy, such as L1 loss [Zhu et al., 2019; Peng et al., 2019], the classifiers are better aligned, which can learn a generalized classification boundary for target samples mentioned above. Instead of explicitly training one classifier for each source, many methods focus on training a compound classifier based on specific combined task loss, such as normalized activations [Mancini et al., 2018] and bandit controller [Guo et al., 2020].
分类器对齐。直观上,训练于不同来源的分类器可能会导致对接近领域边界的目标样本的预测不一致。通过最小化特定分类器差异,如 L1 丢失 [Zhu et al., 2019;Peng et al., 2019],分类器更好地对齐,可以学习上述目标样本的广义分类边界。许多方法不是为每个源明确训练一个分类器,而是基于特定的组合任务丢失训练一个复合分类器,如规范化激活 [Mancini et al., 2018] 和 bandit 控制器 [Guo et al., 2020]。
Target prediction. After aligning the features of target and source domains in the latent space, the classifiers trained based on the labeled source samples can be used to predict the labels of a target sample. Since there are multiple sources, it is possible that they will yield different target predictions. One way to reconcile these different predictions is to uniformly average the predictions from different source classi- fiers [Zhu et al., 2019]. However, different sources may have different relationships with the target, e.g. one source might better align with the target, so a non-uniform, weighted averaging of the predictions leads to better results. Weighting strategies, known as a source selection process, include uniform weight [Zhu et al., 2019], perplexity score based on adversarial loss [Xu et al., 2018], point-to-set (PoS) metric using Mahalanobis distance [Guo et al., 2018], relative error based on source-only accuracy [Peng et al., 2019], and Wasserstein distance based weights [Zhao et al., 2020].
目标预测。将潜在空间中目标域和源域的特征对齐后,基于标记源样本训练的分类器可以用来预测目标样本的标签。由于有多个来源,它们可能会产生不同的目标预测。调和这些不同预测的一种方法是统一平均来自不同来源分类器的预测 [Zhu et al., 2019]。然而,不同的来源可能与目标有不同的关系,例如,一个来源可能更好地与目标保持一致,因此对预测进行不一致的加权平均可以得到更好的结果。权重策略,称为源选择过程,包括统一的体重 (Zhu et al ., 2019),困惑得分基于对抗的损失(徐et al ., 2018), point-to-set (PoS) 度量使用 Mahalanobis 距离 (Guo et al ., 2018),基于单一的相对误差精度 (Peng et al ., 2019) 和瓦瑟斯坦距离权重 (Zhao et al ., 2020)。
Besides the source importance, Zhao et al. [2020] also considered the sample importance, i.e. different samples from the same source may still have different similarities from the target samples. The source samples that are closer to the target are distilled (based on a manually selected Wasserstein distance threshold) to fine-tune the source classifiers. Automatically and adaptively selecting the most relevant training samples for each source remains an open research problem.
除了源的重要性,Zhao et al.[2020] 还考虑了样本的重要性,即来自同一源的不同样本与目标样本的相似度可能仍然不同。接近目标的源样本被蒸馏(基于一个手动选择的 Wasserstein 距离阈值)来微调源分类器。自动地、自适应地为每个源选择最相关的训练样本仍然是一个开放的研究问题。
Intermediate Domain Generation
Feature-level alignment only aligns high-level information, which is insufficient for fine-grained predictions, such as pixel-wise semantic segmentation [Zhao et al., 2019a]. Generating an intermediate adapted domain with pixel-level alignment, typically via GANs [Goodfellow et al., 2014], can help address this problem.
特征级对齐只对高层次信息进行对齐,这对于细粒度预测是不够的,比如像素级语义分割 [Zhao et al.,2019a]。生成像素级对齐的中间自适应域,通常是通过GANs [Goodfellow et al.,2014],可以帮助解决这个问题。
Domain generator. Since the original GAN is highly under-constrained, some improved versions are employed, such as Coupled GAN (CoGAN) in [Russo et al., 2019] and CycleGAN in MADAN [Zhao et al., 2019a]. Instead of directly taking the original source data as input to the generator [Russo et al., 2019; Zhao et al., 2019a], Lin et al. [2020] used a variational autoencoder to map all source and target domains to a latent space and then generated an adapted domain from the latent space. Russo et al. [2019] then tried to align the target and each adapted domain, while Lin et al. [2020] aligned the target and combined adapted domain from the latent space. Zhao et al. [2019a] proposed to aggregate different adapted domains using a sub-domain aggregation discriminator and cross-domain cycle discriminator, where the pixel-level alignment is then conducted between the aggregated and target domains. Zhao et al. [2019a] and Lin et al. [2020] showed that the semantics might change in the intermediate representation, and that enforcing a semantic consistency before and after generation can help preserve the labels.
域生成器。由于原始GAN高度受限,采用了一些改进版本,如 Russo et al.,2019年的耦合 GAN (CoGAN) 和 MADAN 的 CycleGAN [Zhao et al.,2019a]。而不是直接将原始源数据作为生成器的输入[Russo et al.,2019;Zhao et al.,2019a], Lin et al.[2020]使用变分自编码器将所有源和目标域映射到一个潜在空间,然后从潜在空间生成一个自适应域。Russo et al.[2019] 试图将目标与每个自适应域对齐,而 Lin et al.[2020] 则将目标对齐并从潜在空间合并自适应域。Zhao et al.[2019a] 提出使用子域聚合判别器和跨域周期判别器聚合不同的适应域,然后在聚合域和目标域之间进行像素级对齐。Zhao et al.[2019a] 和 Lin et al.[2020]表明,中间表示的语义可能会发生变化,在生成前后加强语义一致性有助于保留标签。
Feature alignment and target prediction. Feature-level alignment is often jointly considered with pixel-level alignment. Both alignments are usually achieved by minimizing the GAN loss with a discriminator. One classifier is trained on each adapted domain [Russo et al., 2019] and the multiple predictions for a given target sample are averaged. Only one classifier is trained on the aggregated domain [Zhao et al., 2020] or on the combined adapted domain [Lin et al., 2020] which is obtained by a unique generator from the latent space for all source domains. The comparison of these methods are summarized in Table 3.
特征对齐与目标预测。特征级对齐通常与像素级对齐一起考虑。这两种校准通常都是通过利用判别器使GAN损耗最小化来实现的。在每个适应域上训练一个分类器 [Russo et al.,2019],并对给定目标样本的多个预测进行平均。在聚集域 [Zhao et al., 2020] 或组合适应域 [Lin et al., 2020] 上只训练一个分类器。组合适应域是由一个唯一的发生器从所有源域的潜在空间中获得的。表3总结了这些方法的比较结果。