DETR训练自己的数据集
DETR训练自己的数据集实验笔记
DETR是一个利用transformer实现端到端目标检测的模型。本文记录利用官方提供的代码来训练验证自己的数据集的过程以及一些注意事项。
一.数据集的准备与处理
此次项目用到的数据集为自己制造的自动驾驶领域的路况数据集,该数据集一共包含57个类别:names = [ "i2", "i4", "i5", "il100", "il60", "il80", "io", "ip", "p10", "p11", "p12", "p19", "p23", "p26", "p27", "p3", "p5", "p6", "pg", "ph4", "ph4d5", "ph5", "pl100", "pl120", "pl20", "pl30", "pl40", "pl5", "pl50", "pl60", "pl70", "pl80", "pm20", "pm30", "pm55", "pn", "pne", "po", "pr40", "w13", "w32", "w55", "w57", "w59", "wo", 'crosswalk', 'left', 'right', 'straight', 'straightl', 'straightr', 'diamond', 'noparking', 'person', 'car', 'truck', 'bus' ]
DETR需要的数据集格式为coco格式,其原始图片与标签分为训练集和验证集,其保存目录为
其中annotations文件夹下保存训练集和验证集的标注信息,注:训练集标签json文件命名为instances_train2017.json .验证集标签json文件命名为instance_val2017.json
该数据集原始的标签保存格式为yolo类型的txt文件,下面提供的代码能够实现数据集标签从txt文件到coco json格式的转化.
生成instances_xxx.json文件
#将yolo格式标注的txt文件转化为coco数据集标注格式的json文件类型#yolo格式为(xc,yc,w,h)相对坐标 coco标注格式为(xmin,ymin,w,h),绝对坐标 voc标注xml格式为(xmin,ymin,xmax,ymax)
import argparse
import os
import sys
import json
import shutil
import cv2
from datetime import datetime
coco=dict()
coco['images']=[]
coco['type']='instances'
coco['annotations']=[]
coco['categories']=[]
category_set=dict()images_set=set()
image_id=000000
annotation_id=0
def addCatItem(categroy_dict): #保存所有的类别信息
for k,v in categroy_dict.items():
category_item=dict()
category_item['supercategory']='none'
category_item['id']=int(k)
category_item['name']=v
coco['categories'].append(category_item)
def addImgItem(file_name,size):
global image_id
image_id +=1
image_item=dict()
image_item['id']=image_id
image_item['file_name']=file_name
image_item['width']=size[1]
image_item['height']=size[0]
image_item['license']=None
image_item['flickr_url']=None
image_item['coco_url']=None
image_item['data_captured']=str(datetime.today())
coco['images'].append(image_item)
images_set.add(file_name)
return image_id
def addAnnoItem(object_name,image_id,category_id,bbox):
global annotation_id
annotation_item=dict()
annotation_item['segmentation']=[]
seg=[]
#bbox is x,y,w,h seg.append(bbox[0]) seg.append(bbox[1])
seg.append(bbox[0])
seg.append(bbox[1]+bbox[3])
seg.append(bbox[0]+bbox[2])
seg.append(bbox[1]+bbox[3])
seg.append(bbox[0]+bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area']=bbox[2]*bbox[3] #w*h
annotation_item['iscrowd']=0
annotation_item['ignore']=0
annotation_item['image_id']=image_id
annotation_item['bbox']=bbox
annotation_item['category_id']=category_id
annotation_id +=1
annotation_item['id']=annotation_id
coco['annotations'].append(annotation_item)
def xywhn2xywh(bbox,size): #从yolo标注到coco标注
bbox=list(map(float,bbox))
size=list(map(float,size)) #h,w
xmin=(bbox[0]-bbox[2]/2)*size[1]
ymin=(bbox[1]-bbox[3]/2)*size[0]
w=bbox[2]*size[1]
h=bbox[3]*size[0]
bbox=(xmin,ymin,w,h)
return list(map(int,bbox))
def parseXmlFilse(image_path, anno_path, save_path, json_name):
assert os.path.exists(image_path), "ERROR {} dose not exists".format(image_path)
assert os.path.exists(anno_path), "ERROR {} dose not exists".format(anno_path)
if os.path.exists(save_path):
shutil.rmtree(save_path)
os.makedirs(save_path)
json_path = os.path.join(save_path, json_name)
category_set = []
with open(anno_path + '/classes.txt', 'r') as f:
for i in f.readlines():
category_set.append(i.strip())
category_id = dict((k, v) for k, v in enumerate(category_set))
addCatItem(category_id)
images = [os.path.join(image_path, i) for i in os.listdir(image_path)]
files = [os.path.join(anno_path, i) for i in os.listdir(anno_path)]
images_index = dict((v.split(os.sep)[-1][:-4], k) for k, v in enumerate(images))
for file in files:
if os.path.splitext(file)[-1] != '.txt' or 'classes' in file.split(os.sep)[-1]:
continue
if file.split(os.sep)[-1][:-4] in images_index:
index = images_index[file.split(os.sep)[-1][:-4]]
img = cv2.imread(images[index])
shape = img.shape
filename = images[index].split(os.sep)[-1]
current_image_id = addImgItem(filename, shape)
else:
continue
with open(file, 'r') as fid:
for i in fid.readlines():
i = i.strip().split()
category = int(i[0])
category_name = category_id[category]
bbox = xywhn2xywh((i[1], i[2], i[3], i[4]), shape)
addAnnoItem(category_name, current_image_id, category, bbox)
json.dump(coco,open(json_path,'w'))
print("class nums:{}".format(len(coco['categories'])))
print("image nums:{}".format(len(coco['images'])))
print("bbox nums:{}".format(len(coco['annotations'])))
if __name__=='__main__':
'''参数说明:
anno_path:标注txt文件存储地址
save_path:json文件输出文件夹
image_path:图片路径
json_name:保存json文件名称'''
parser = argparse.ArgumentParser()
parser.add_argument('-ap', '--anno-path', type=str, default='/home/nianliu/wangxx/train_data_v5_format/labels', help='yolo txt path')
parser.add_argument('-s', '--save-path', type=str, default='/home/nianliu/wangxx/train_data_v5_format/anno_json', help='json save path')
parser.add_argument('--image-path', default='/home/nianliu/wangxx/train_data_v5_format/images/train')
parser.add_argument('--json-name', default='train.json')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
parseXmlFilse(**vars(opt))
else:
anno_path = '/home/nianliu/wangxx/train_data_v5_format/labels/train'
save_path = '/home/nianliu/wangxx/train_data_v5_format/annotations'
image_path = '/home/nianliu/wangxx/train_data_v5``_format/images/train'
json_name = 'instance_train2017.json'
parseXmlFilse(image_path, anno_path, save_path, json_name) '''
其中修改anno_path为原始txt类型标签文件地址,save_path为保存json文件的地址,image_path为数据集图像地址,json_name按照detr要求的修改
注:在train,val保存txt文件的地址中添加一个classes.txt文件,其内容按行写入数据集的类别名称
二.训练
首先通过DETR项目下载项目文件
1.修改预训练模型权重
DETR模型训练十分缓慢,因此需要下载其提供好的预训练模型
根基自己的数据集修改预训练文件,新建changepre.py,修改num_classes为自己数据集的类别数加一,运行该文件得到detr_r50_58.pth文件
import torch
pretrained_weights=torch.load('/home/nianliu/wangxx/detr/detr-r50-e632da11.pth')
num_classes=57+1
pretrained_weights["model"]["class_embed.weight"].resize_(num_classes+1,256)
pretrained_weights["model"]["class_embed.bias"].resize_(num_classes+1)
torch.save(pretrained_weights,"detr_r50_%d.path"%num_classes)2.训练模型
修改models/detr.py中313行num_classes为自己数据集的类别数。
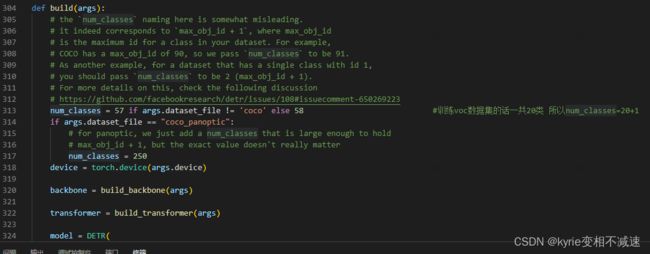
利用main.py进行模型训练,注意以下几个参数
coco-path为数据集保存地址。

output_dir为保存训练得到的模型权重的地址。
![]()
resume为预训练模型权重文件。
![]()
终端执行即可进行模型的训练。
![]()
三.验证模型
训练过程中会每隔一段时间打印出验证结果。该部分为利用训练得到的模型权重进行检测验证。新建一个infer_demo.py进行模型验证
import glob
import math
import argparse
import numpy as np
from models.detr import DETR
from models.backbone
import Backbone,build_backbonefrom models.transformer
import build_transformer
from PIL import Image
import cv2
import requests
import matplotlib.pyplot as plt
import torch
from torch import nn
from torchvision.models import resnet50
import torchvision.transforms as T
import torchvision.models as models
torch.set_grad_enabled(False)
import os
def get_args_parser():
parser = argparse.ArgumentParser('Set transformer detector', add_help=False)
parser.add_argument('--lr', default=1e-4, type=float)
parser.add_argument('--lr_backbone', default=1e-5, type=float)
parser.add_argument('--batch_size', default=2, type=int)
parser.add_argument('--weight_decay', default=1e-4, type=float)
parser.add_argument('--epochs', default=300, type=int)
parser.add_argument('--lr_drop', default=200, type=int)
parser.add_argument('--clip_max_norm', default=0.1, type=float, help='gradient clipping max norm')
# Model parameters
parser.add_argument('--frozen_weights', type=str, default=None, help="Path to the pretrained model. If set, only the mask head will be trained") # * Backbone
parser.add_argument('--backbone', default='resnet50', type=str, help="Name of the convolutional backbone to use")
parser.add_argument('--dilation', action='store_true', help="If true, we replace stride with dilation in the last convolutional block (DC5)")
parser.add_argument('--position_embedding', default='sine', type=str, choices=('sine', 'learned'), help="Type of positional embedding to use on top of the image features")
# * Transformer
parser.add_argument('--enc_layers', default=6, type=int, help="Number of encoding layers in the transformer")
parser.add_argument('--dec_layers', default=6, type=int, help="Number of decoding layers in the transformer")
parser.add_argument('--dim_feedforward', default=2048, type=int, help="Intermediate size of the feedforward layers in the transformer blocks")
parser.add_argument('--hidden_dim', default=256, type=int, help="Size of the embeddings (dimension of the transformer)")
parser.add_argument('--dropout', default=0.1, type=float, help="Dropout applied in the transformer")
parser.add_argument('--nheads', default=8, type=int, help="Number of attention heads inside the transformer's attentions")
parser.add_argument('--num_queries', default=100, type=int, help="Number of query slots")
parser.add_argument('--pre_norm', action='store_true')
# * Segmentation
parser.add_argument('--masks', action='store_true', help="Train segmentation head if the flag is provided")
# Loss
parser.add_argument('--no_aux_loss', dest='aux_loss', action='store_false', help="Disables auxiliary decoding losses (loss at each layer)") # * Matcher
parser.add_argument('--set_cost_class', default=1, type=float, help="Class coefficient in the matching cost")
parser.add_argument('--set_cost_bbox', default=5, type=float, help="L1 box coefficient in the matching cost")
parser.add_argument('--set_cost_giou', default=2, type=float, help="giou box coefficient in the matching cost") # * Loss coefficients
parser.add_argument('--mask_loss_coef', default=1, type=float)
parser.add_argument('--dice_loss_coef', default=1, type=float)
parser.add_argument('--bbox_loss_coef', default=5, type=float)
parser.add_argument('--giou_loss_coef', default=2, type=float)
parser.add_argument('--eos_coef', default=0.1, type=float, help="Relative classification weight of the no-object class")
# dataset parameters
parser.add_argument('--dataset_file', default='coco')
parser.add_argument('--coco_path', type=str)
parser.add_argument('--coco_panoptic_path', type=str)
parser.add_argument('--remove_difficult', action='store_true')
parser.add_argument('--output_dir', default='', help='path where to save, empty for no saving')
parser.add_argument('--device', default='cuda', help='device to use for training / testing')
parser.add_argument('--seed', default=42, type=int)
parser.add_argument('--resume', default='', help='resume from checkpoint')
parser.add_argument('--start_epoch', default=0, type=int, metavar='N', help='start epoch')
parser.add_argument('--eval', action='store_true')
parser.add_argument('--num_workers', default=2, type=int)
# distributed training parameters
parser.add_argument('--world_size', default=1, type=int, help='number of distributed processes')
parser.add_argument('--dist_url', default='env://', help='url used to set up distributed training')
return parser
CLASSES = [ "i2", "i4", "i5", "il100", "il60",
"il80", "io", "ip", "p10", "p11",
"p12", "p19", "p23", "p26", "p27",
"p3", "p5", "p6", "pg", "ph4",
"ph4d5", "ph5", "pl100", "pl120", "pl20",
"pl30", "pl40", "pl5", "pl50", "pl60",
"pl70", "pl80", "pm20", "pm30", "pm55",
"pn", "pne", "po", "pr40", "w13",
"w32", "w55", "w57", "w59", "wo",
'crosswalk', 'left', 'right', 'straight', 'straightl', 'straightr', 'diamond', 'noparking',
'person', 'car', 'truck', 'bus' ]
COLORS = [[0.000, 0.447, 0.741], [0.850, 0.325, 0.098], [0.929, 0.694, 0.125], [0.494, 0.184, 0.556], [0.466, 0.674, 0.188], [0.301, 0.745, 0.933]]
transform_input = T.Compose([ T.Resize(800),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
def box_cxcywh_to_xyxy(x):
x_c, y_c, w, h = x.unbind(1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32)
return b
def plot_results(pil_img, prob, boxes, save_path):
lw= max(round(sum(pil_img.shape) / 2 * 0.003), 2)
tf = max(lw - 1, 1)
colors = COLORS * 100
for p, (xmin, ymin, xmax, ymax), c in zip(prob, boxes.tolist(), colors):
c1=p.argmax()
text=f'{CLASSES[c1]}:{p[c1]:0.2f}'
cv2.rectangle(pil_img, (int(xmin),int(ymin)), (int(xmax),int(ymax)), (255,0,0), thickness=lw,lineType=cv2.LINE_AA)
cv2.putText(pil_img, text, (int(xmin), int(ymin) - 2), 0, lw / 3, (255,255,255), thickness=tf, lineType=cv2.LINE_AA)
Image.fromarray(ori_img).save(save_path)
parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
args = parser.parse_args()
backbone=build_backbone(args)
transform=build_transformer(args)
model=DETR(backbone=backbone,transformer=transform,num_classes=58,num_queries=100)
model_path='/home/nianliu/wangxx/detr/cdnet_weights/checkpoint0179.pth' #保存的预训练好的模型pth文件,用于验证
model_data=torch.load(model_path)['model']
model=torch.load(model_path)model.load_state_dict(model_data)
model.eval();
paths = os.listdir('/home/nianliu/wangxx/detr/images') #待验证的图片路径
for path in paths: # 问题1:无法读取png图像
if os.path.splitext(path)[1] == ".png": # 问题1解1:用imread读取png
im = cv2.imread(path)
im = Image.fromarray(cv2.cvtColor(im,cv2.COLOR_BGR2RGB))
else:
im = Image.open('/home/nianliu/wangxx/detr/images'+'/'+path)
# mean-std normalize the input image (batch-size: 1)
img = transform_input(im).unsqueeze(0)
# propagate through the model
outputs = model(img)
# keep only predictions with 0.9+ confidence
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > 0.9
# convert boxes from [0; 1] to image scales
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)
#保存验证结果地址
img_save_path = '/home/nianliu/wangxx/detr/infer_results/' + os.path.splitext(os.path.split(path)[1])[0] + '.jpg'
ori_img=np.array(im)
plot_results(ori_img, probas[keep], bboxes_scaled, img_save_path)在detr工程文件下的images文件夹存放所有待验证的图片,infer_results存放所有的验证结果。
得到的预测结果如下所示: