降维方法PCA、Isomap、LLE、Autoencoder方法与python实现
文章目录
- 所用的数据
- PCA( 主成分分析)
-
- 方法介绍
- 实验结果分析
- Isomap( 等度量映射)
-
- 方法介绍
- 实验结果分析
- LLE
-
- 方法介绍
- 实验结果分析
- Autoencoder
-
- 方法介绍
- 实验结果分析
- 源代码
-
- PCA( 主成分分析)
- Isomap( 等度量映射)
- LLE
- Autoencoder
所用的数据
选用 MNIST 手写数字数据集 ( http://yann.lecun.com/exdb/mnist/ )。
该数据集包括 55000 个训练集样本和 10000 个测试集样本。

PCA( 主成分分析)
方法介绍
主成分分析是最常用的一种降维方法。
目标:找到数据本质低维子空间的正交基.( 也就是说使用一个超平面对所有样本进行恰当的表达)
故而其超平面应具有以下两个性质:
- 最大可分性:样本在这个超平面上的投影尽可能分开。
- 最近重构性:样本点到这个超平面的距离都足够近。
首先对于最大可分性,若所有点尽可能分开,也就是说投影后样本点的方差最大化。
故而 PCA 的数学定义是:一个正交化线性变换,把数据变换到一个新的坐标系统中,使得这一数据的任何投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。
首先假设数据进行了中心化,即 ∑ i x i = 0 \sum_i x_i=0 ∑ixi=0,投影变换后的新坐标为 W = { ω 1 , ω 2 , ⋯ , ω d } W=\{\omega_1,\omega_2,\cdots,\omega_d\} W={ω1,ω2,⋯,ωd},其中 ω i \omega_i ωi 是标准正交基向量(即 ∥ ω i ∥ 2 = 1 \|\omega_i\|_2=1 ∥ωi∥2=1, ω i T ω j = 0 ( i ≠ j ) \omega_i^T\omega_j=0(i\neq j) ωiTωj=0(i̸=j) )。
样本点 x i x_i xi 在新空间超平面上的投影是 W T x i W^Tx_i WTxi,投影后样本点的方差是 ∑ i W T x i x i T W \sum_i W^Tx_i x_i^TW ∑iWTxixiTW,于是优化目标可以写为:
max W t r { W T X X T W } \max \limits_{W}tr\{W^TX X^TW\} Wmaxtr{WTXXTW}
对上式使用拉格朗日乘数法可得:
X X T W = λ W XX^TW=\lambda W XXTW=λW
所以,这个式子中 λ \lambda λ 是特征值, X X T XX^T XXT 是特征向量。只需要对协方差矩阵 X X T XX^T XXT 进行特征值分解,将求得的特征值排序: λ 1 ≥ λ 2 ≥ ⋯ ≥ λ d \lambda_1\geq\lambda_2\geq\cdots\geq\lambda_d λ1≥λ2≥⋯≥λd,再取前 d ′ d' d′ 个特征值对应的特征向量构成 W = { ω 1 , ω 2 , ⋯ , ω d ′ } W=\{\omega_1,\omega_2,\cdots,\omega_{d'}\} W={ω1,ω2,⋯,ωd′} ,这就是 PCA 的解(实践中通常通过对 X 进行奇异值分解代替协方差矩阵特征值分解)。
实验结果分析
这里设置降维的维数为 2 ,速度很快。所得结果为:

在二维空间中,对于 0 和 2 有分离效果,其他的效果并不十分明显。
Isomap( 等度量映射)
方法介绍
流形学习是一类借鉴了拓扑流概念的降维方法,
Isomap 的基本出发点是认为低维流形嵌入到高维空间之后,在高位空间计算直线距离具有误导性,因为其在低维流形中是不可达的。
故而利用流形在局部与欧式空间同胚,对每个点基于欧式空间找出近邻点,建立近邻连接图,近邻点存在连接,非近邻点不存在连接,计算两点之间流形图测地线的问题,就变为近邻连接图最短路径问题.
Isomap 需要指定近邻点的个数或者距离阈值,若指定范围较大,则可能出现流形之间“短路”问题,若范围过小,则图中有些区域可能与其他区域不存在连接,出现“断路”问题。两者都会给后面的最短路计算造成误导。
实验结果分析
这里设置降维的维数为 2,设置相邻点数为 5 ,使用 MNIST 数据 10000 条。
Isomap 所消耗的时间比较长。
所得结果为:

在二维空间中有一定的分离效果,但是分离效果并不明显。
LLE
方法介绍
LLE 的全称为局部线型嵌入,其核心为:流形的局部 ( 一个小的邻域空间)为近似线性。故而 LLE 算法认为每一个数据点都可以由其近邻点的线性加权组合构造得到。即认为该数据与其近邻点的线性加权组合构造得到的数据的误差最小。加权组合即为: ∑ j = 1 k w i j x j \sum \limits_{j=1}^k w_{ij}x_j j=1∑kwijxj,其中 w w w 为加权系数。
定义误差函数为;
J ( w ) = ∑ i = 1 m ∥ x i − ∑ j ∈ Q ( i ) w i j x j ∥ 2 J(w)=\sum_{i=1}^m \| x_i-\sum \limits_{j\in Q(i)} w_{ij}x_j\|^2 J(w)=i=1∑m∥xi−j∈Q(i)∑wijxj∥2
其中, Q ( i ) Q(i) Q(i) 表示 i i i 的 k 个近邻样本集合。我们希望将误差函数最小化。
对于加权系数,至少有两个要求:
- 其中若 x i x_i xi 与 x j x_j xj 不为邻域,则强制 w i j = 0 w_{ij}=0 wij=0 。
- 对于加权值要归一化,即 ∑ j W i j = 1 \sum \limits_{j}{\mathbf {W} _{ij}}=1 j∑Wij=1 。
因为加权值归一化,故 ∑ j ∈ Q ( i ) w i j x i = x i \sum \limits_{j\in Q(i)}w_{ij}x_i=x_i j∈Q(i)∑wijxi=xi.
如何最小化矩阵。
J ( w ) = ∑ i = 1 m ∥ x i − ∑ j ∈ Q ( i ) w i j x j ∥ 2 = ∑ i = 1 m ∥ ∑ j ∈ Q ( i ) w i j x i − ∑ j ∈ Q ( i ) w i j x j ∥ 2 = ∑ i = 1 m ∥ ∑ j ∈ Q ( i ) w i j ( x i − x j ) ∥ 2 = ∑ i = 1 m W i T ( x i − x j ) ( x i − x j ) T W i J(w)=\sum \limits_{i=1}^m \| x_i-\sum \limits_{j\in Q(i)} w_{ij}x_j\|^2 \\ =\sum \limits_{i=1}^m \| \sum \limits_{j\in Q(i)}w_{ij}x_i-\sum \limits_{j\in Q(i)} w_{ij}x_j\|^2 \\ =\sum \limits_{i=1}^m \| \sum \limits_{j\in Q(i)}w_{ij}(x_i-x_j)\|^2 \\ =\sum \limits_{i=1}^m W_i^T (x_i-x_j)(x_i-x_j)^T W_i J(w)=i=1∑m∥xi−j∈Q(i)∑wijxj∥2=i=1∑m∥j∈Q(i)∑wijxi−j∈Q(i)∑wijxj∥2=i=1∑m∥j∈Q(i)∑wij(xi−xj)∥2=i=1∑mWiT(xi−xj)(xi−xj)TWi
其中, W i = ( w i 1 , w i 2 , ⋯ , w i 1 ) W_i=(w_{i1},w_{i2},\cdots,w_{i1}) Wi=(wi1,wi2,⋯,wi1)
若原始数据点在 D 维空间中,算法的目标是将维度减小到 d,使得 d ≪ D d\ll D d≪D ,低维数据点用 y 表示,低维数据点的最小化误差函数也应有相同的形式,即为:
L ( w ) = ∑ i = 1 m ∥ y i − ∑ j ∈ Q ( i ) w i j y j ∥ 2 L(w)=\sum_{i=1}^m \| y_i-\sum \limits_{j\in Q(i)} w_{ij}y_j\|^2 L(w)=i=1∑m∥yi−j∈Q(i)∑wijyj∥2
在高维中高维数据已知,目标是求加权系数矩阵,我们希望这些加权系数对应的线型关系在降维后的低维一样得到保持。我们在低维是加权系数 W 已知,求对应的低维系数。
算法的主要步骤分为:
- 寻找每个样本点的 k 个近邻点;
- 由每个样本点的近邻点计算出该样本点的局部重建权值矩阵;
- 由该样本点的局部重建权值矩阵和其近邻点计算出该样本点的输出值。
实验结果分析
对比来看,图中二维的形状与其他的方法得到的情况不同,对一些数字的分离效果比较好,比如 7 和 0 ,但是对其他数字的效果一般。

Autoencoder
方法介绍
autoencoder 使用人工神经网络,以无监督学习的方式对高维数据进行编码成为低维数据,然后可以将低维数据进行解码称为高维数据的过程。前一个过程称为编码器( encoder ),后一个过程的网络称为解码器( decoder ),后一个过程也叫做重建的过程。
如果 decoder 为 ϕ {\displaystyle \phi } ϕ,encoder 为 ψ {\displaystyle \psi} ψ,那么:
ϕ : X → F {\displaystyle \phi :{\mathcal {X}}\rightarrow {\mathcal {F}}} ϕ:X→F
ψ : F → X {\displaystyle \psi :{\mathcal {F}}\rightarrow {\mathcal {X}}} ψ:F→X
ϕ , ψ = arg min ϕ , ψ ∥ X − ( ψ ∘ ϕ ) X ∥ 2 {\displaystyle \phi ,\psi ={\underset {\phi ,\psi }{\operatorname {arg\,min} }}\,\|X-(\psi \circ \phi )X\|^{2}} ϕ,ψ=ϕ,ψargmin∥X−(ψ∘ϕ)X∥2
最简单的情况下,如果只有一个隐层,自编码的编码过程采用输入 $ {\displaystyle \mathbf {x} \in \mathbb {R} ^{d}={\mathcal {X}}}$ 并将其映射到 z ∈ R p = F {\displaystyle \mathbf {z} \in \mathbb {R} ^{p}={\mathcal {F}}} z∈Rp=F
z = σ ( W x + b ) {\displaystyle \mathbf {z} =\sigma (\mathbf {Wx} +\mathbf {b} )} z=σ(Wx+b)
这里, σ \sigma σ 是元素激活函数。 W { \mathbf {W}} W 是权重矩阵, b { \mathbf {b}} b 是偏置向量。之后,自动编码器的解码器阶段将 z { \mathbf {z}} z 映射到与 x { \mathbf {x}} x 形状相同的重建 x ′ { \mathbf {x'}} x′ :
x ′ = σ ′ ( W ′ z + b ′ ) {\displaystyle \mathbf {x'} =\sigma '(\mathbf {W'z} +\mathbf {b'} )} x′=σ′(W′z+b′)
这里 $ \mathbf {\sigma ‘} ,\mathbf {W’}$ 和 $\mathbf {b’} $ 与 $ \mathbf {\sigma } ,\mathbf {W}$ 和 $\mathbf {b} $ 相对应。编码器和解码器都经过训练,可以最大程度上减小重建错误。
L ( x , x ′ ) = ∥ x − x ′ ∥ 2 = ∥ x − σ ′ ( W ′ ( σ ( W x + b ) ) + b ′ ) ∥ 2 {\displaystyle {\mathcal {L}}(\mathbf {x} ,\mathbf {x'} )=\|\mathbf {x} -\mathbf {x'} \|^{2}=\|\mathbf {x} -\sigma '(\mathbf {W'} (\sigma (\mathbf {Wx} +\mathbf {b} ))+\mathbf {b'} )\|^{2}} L(x,x′)=∥x−x′∥2=∥x−σ′(W′(σ(Wx+b))+b′)∥2
实验结果分析
代码使用 MNIST 一共 55000 条数据,编码器和解码器分别建立了四层神经网络。神经网络很依赖于计算能力,下面是一组对比,分别是训练了一千次与一万次的结果。
可以看到,在讨论的四种方法中, Autoencoder 的分离效果最好。还原也是比较准确的。


 一千次训练之后的结果
一千次训练之后的结果
 一万次训练之后的结果
一万次训练之后的结果
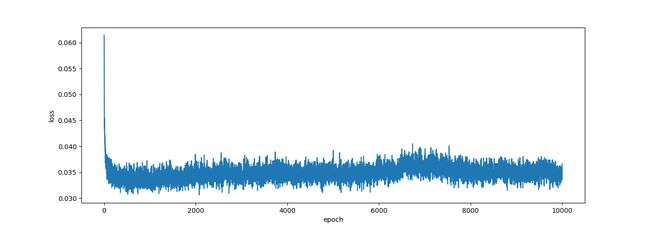
下图是误差与训练次数之间的关系,可以看到随着训练次数的增加,误差减小,但是随着训练次数增加,到达一定程度,误差也不会有明显下降,可能需要加深神经网络层数和修改压缩维度。
源代码
PCA( 主成分分析)
from __future__ import division, print_function, absolute_import
import pandas as pd
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=False)
print(mnist.train.images.shape, mnist.train.labels.shape)
estimator = PCA(n_components=2)
x_pca = estimator.fit_transform(mnist.train.images)
label=mnist.train.labels
# 显示图形,前两个参数为降维结果的两维,第三个是手写数字的标签
plt.scatter(x_pca[:, 0], x_pca[:, 1], c=mnist.train.labels)
# 以颜色显示三维图像的第三个维度
plt.colorbar()
plt.show()
Isomap( 等度量映射)
from __future__ import division, print_function, absolute_import
import time
import pandas as pd
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=False)
print(mnist.train.images.shape, mnist.train.labels.shape)
from sklearn import manifold
start = time.clock()
# print(mnist.train.images[:10])
trans_data = manifold.Isomap(n_neighbors=5,n_components=2).fit_transform(mnist.train.images[:10000])
elapsed = (time.clock() - start)
print("Time used:",elapsed)
label=mnist.train.labels
# print(label)
# 显示图形,前两个参数为降维结果的两维,第三个是手写数字的标签
plt.scatter(trans_data[:, 0], trans_data[:, 1], c=mnist.train.labels[:10000])
# 以颜色显示三维图像的第三个维度
plt.colorbar()
plt.show()
LLE
from __future__ import division, print_function, absolute_import
import time
import pandas as pd
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=False)
# batch_size = 256
# n_input = 784 # MNIST data input (img shape: 28*28)
# total_batch = int(mnist.train.num_examples/batch_size)
print(mnist.train.images.shape, mnist.train.labels.shape)
# x_digits=minist.train.images
# estimator = PCA(n_components=2)
# x_pca = estimator.fit_transform(mnist.train.images)
from sklearn import manifold
start = time.clock()
# print(mnist.train.images[:10])
trans_data, err = manifold.locally_linear_embedding(X=mnist.train.images[:10000],n_neighbors=5,n_components=2)
elapsed = (time.clock() - start)
print("Time used:",elapsed)
# print(x_pca)
# print(x_pca[:,0])
# print(x_pca[:,1])
label=mnist.train.labels
# print(label)
# 显示图形,前两个参数为降维结果的两维,第三个是手写数字的标签
plt.scatter(trans_data[:, 0], trans_data[:, 1], c=mnist.train.labels[:10000])
# 以颜色显示三维图像的第三个维度
plt.colorbar()
plt.show()
Autoencoder
from __future__ import division, print_function, absolute_import
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 载入 MNIST 数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=False)
# Visualize encoder setting
# 参数设置
learning_rate = 0.01 # 0.01 学习率
training_epochs = 1000
batch_size = 256
display_step = 1
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
# tf Graph input (only pictures)
X = tf.placeholder("float", [None, n_input])
# 隐层设置
n_hidden_1 = 128
n_hidden_2 = 64
n_hidden_3 = 10
n_hidden_4 = 2
weights = {
'encoder_h1': tf.Variable(tf.truncated_normal([n_input, n_hidden_1],)),
'encoder_h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2],)),
'encoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3],)),
'encoder_h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4],)),
'decoder_h1': tf.Variable(tf.truncated_normal([n_hidden_4, n_hidden_3],)),
'decoder_h2': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_2],)),
'decoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_1],)),
'decoder_h4': tf.Variable(tf.truncated_normal([n_hidden_1, n_input],)),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b4': tf.Variable(tf.random_normal([n_input])),
}
def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
def decoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4
# 建构网络
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
# Prediction
y_pred = decoder_op
# Targets (Labels) are the input data.
y_true = X
# 定义损失函数,最小化误差
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
# Launch the graph
with tf.Session() as sess:
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
total_batch = int(mnist.train.num_examples/batch_size)
# Training cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x) = 1, min(x) = 0
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# Display logs per epoch step
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c))
print("Optimization Finished!")
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:10]})
# Compare original images with their reconstructions
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(10):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()
encoder_result = sess.run(encoder_op, feed_dict={X: mnist.test.images})
plt.scatter(encoder_result[:, 0], encoder_result[:, 1], c=mnist.test.labels)
plt.colorbar()
plt.show()