1-数据挖掘环境搭建及numpy数据的介绍与使用
tags: python,数据挖掘,jupyer,numpy,ndarray
目录
文章目录
- 目录
- 需要安装的模块
- 打开`jupyter`
-
- `notebook`的快捷键
-
- 1、命令模式
- 2、编辑模式 ( Enter 键启动)
- 退出`jupyter`
- 创建`ndarray`
-
- 使用`np.array()`从`python list`中创建
- 2. 使用`np`的`routines`函数创建
-
- 经常使用的函数:
- 详细用法与解释
- `ndarray`的属性
- `ndarray`的基本操作
-
- 索引
- 切片
- 将数据反转
- 变形
- 级联
-
- `np.concatenate()`
- `np.hstack`与`np.vstack`
- 切分
- 副本
- `ndarray`的聚合操作
-
- 求和`np.sum()`
- 最大最小值:`np.max/ np.min`
- 其他聚合操作
- `ndarray`的矩阵操作
-
- 基本矩阵操作
- 广播机制
- `ndarray`的排序
-
- 快速排序
- 部分排序
需要安装的模块
首先使用pipenv的方式创建虚拟环境,然后在激活的虚拟环境中,安装以下模块:
numpy,pandas,matplotlib
上面的三个模块被称为数据分析三剑客
然后还要安装以下模块:
ipython
jupyter
打开jupyter
命令jupyter notebook,将会打开自动打开默认浏览器,见下图

该浏览器展示的是上面输入命令时所在的目录。
notebook的快捷键
1、命令模式
• Enter : 转入编辑模式
• Shift-Enter : 运行本单元,选中下个单元
• Ctrl-Enter : 运行本单元,选中下个单元
• Alt-Enter : 运行本单元,在下面插入一单元
• Y : 单元转入代码状态
• M :单元转入markdown状态
• A : 在上方插入新单元
• B : 在下方插入新单元
2、编辑模式 ( Enter 键启动)
• Tab : 代码补全或缩进
• Shift-Tab : 提示
• Ctrl-A : 全选
• Ctrl-Z : 复原
退出jupyter
在刚才的cmd命令窗口,输入ctrl+c即可退出。
创建ndarray
使用np.array()从python list中创建
import numpy as np
l = [1, 2, 3, 4, 5]
n = np.array(l)
display(l, n)
输出结果为:
[1, 2, 3, 4, 5]
array([1, 2, 3, 4, 5])
numpy默认ndarray的所有元素的类型是相同的
如果传进来的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int
2. 使用np的routines函数创建
经常使用的函数:
np.ones(shape, dtype=None, order='C')np.zeros(shape, dtype=float, order='C')np.full(shape, fill_value, dtype=None, order='C')np.eye(N, M=None, k=0, dtype=float)np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)np.arange([start, ]stop, [step, ]dtype=None)np.random.randint(low, high=None, size=None, dtype='l')np.random.randn(d0, d1, ..., dn)np.random.random(size=None)np.random.normal(loc=0.0, scale=1.0)np.random.rand(d0,d1,...dn)
详细用法与解释
np.ones(shape, dtype=None, order='C')

2) np.zeros(shape, dtype=float, order='C')

3) np.full(shape, fill_value, dtype=None, order='C')

4) np.eye(N, M=None, k=0, dtype=float)
对角线为1其他的位置为0,其中k的值为对角线开始位置的索引,为-1,则为最第一行的第一个元素的前面一位,由于该位置没有,所有第一行就没有1.

5) np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
将从start到stop组成的线段分为num份,endpoint表示stop对应的数值会不会在分好的结果里显示。retstep为真时,结果返回的是一个元组,元组里面一个是分好的数据,另一个是分好的数据之间的间距。

6) np.arange([start, ]stop, [step, ]dtype=None)
和python中的range是类似的,都是给的左闭右开的区间
注意,如果给的step是整数的话,可以使用这个函数,但是如果是小数的话,建议使用上面的函数。

7) np.random.randint(low, high=None, size=None, dtype='l')

8) np.random.randn(d0, d1, ..., dn)
标准正态分布,其中d0-dn为维度

9) np.random.normal(loc=0.0, scale=1.0, size=None)
正态分布(高斯分布)
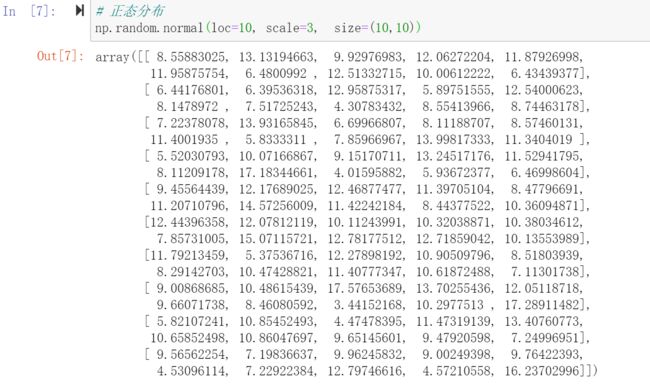
10) np.random.random(size=None)
生成0到1的随机数,左闭右开
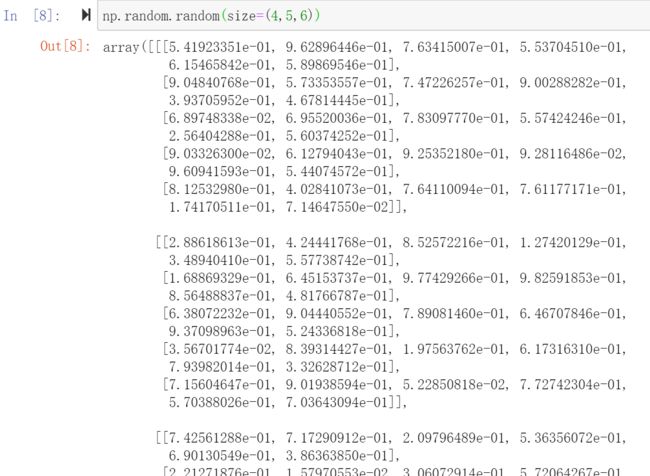
11) np.random.rand(d0, d1, ..., dn)
效果和上面的一样
12)np.random.uniform(low=0.0, high=1.0, size=None),生成符合指定均匀分布的数组

ndarray的属性
4个必记参数:
.ndim:维度.shape:形状(各维度的长度).size:总长度.dtype:元素类型
例如下面的代码输出结果:
n = np.random.randint(0, 150, size=(3, 4, 5))
print(n.ndim)
print(n.shape)
print(n.size)
print(n.dtype)
3
(3, 4, 5)
60
int32
ndarray的基本操作
索引
一维与列表完全一致,多维时同理
切片
一维与列表完全一致,多维时同理
将数据反转
例如[1,2,3]---->[3,2,1],使用[::-1]进行切片操作
变形
使用.reshape()函数,注意参数是一个tuple!
注意:
reshape的时候,元素个数不能变(元素个数就是所有维度个数的乘积)
级联
np.concatenate()
级联需要注意的点:
- 级联的参数是列表:一定要加中括号或小括号
- 维度必须相同
- 形状相符
- 【重点】级联的方向默认是
shape这个tuple的第一个值所代表的维度方向 - 可通过
axis参数改变级联的方向
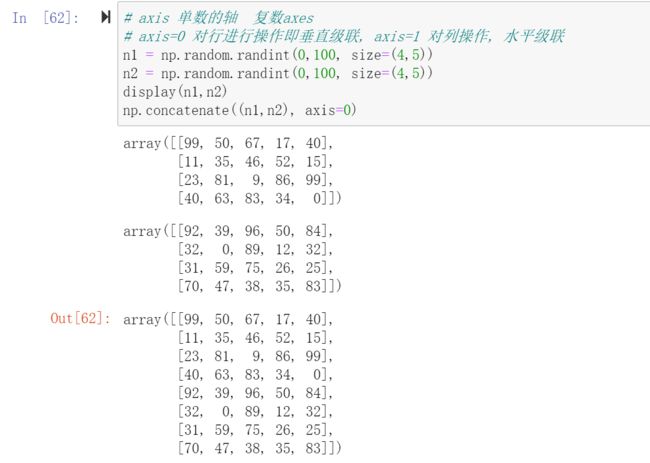
np.hstack与np.vstack
水平级联与垂直级联,进行维度的变更

切分
与级联类似,三个函数完成切分工作:
np.splitnp.vsplitnp.hsplit
下面的代码是axis=0的时候的结果(垂直方向对水平切,np.hsplit(n, [2, 4])代码效果一致)
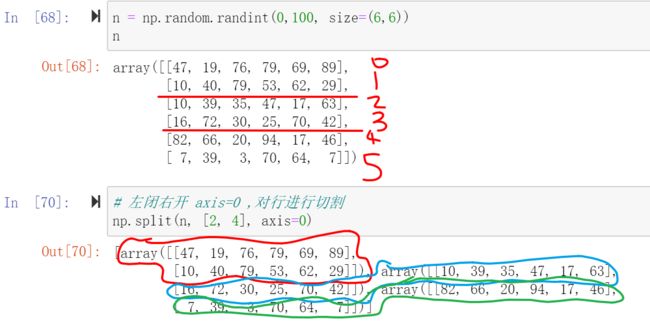
下面的是axis=1的时候的结果(水平方向对垂直切,np.vsplit(n, [2, 4])代码效果一致)
axis=0表示对行进行操作,axis=1表示对列进行操作。
副本
所有赋值运算不会为ndarray的任何元素创建副本。对赋值后的对象的操作也对原来的对象生效。 #F44336
为了避免对赋值后的对象的修改影响原来的对象,所以可以使用copy()函数来创建副本。

ndarray的聚合操作
求和np.sum()
可以直接对ndarray对象执行聚合操作,也可以使用np.sum()将需要聚合的ndarray对象传入,两者效果一样。

注意对指定
axix时操作的理解 #F44336,比如axix=0表示对行进行聚合,所以行都没了,也就是把每一列的所有行都相加,最后只剩下列;而axix=1表示对列进行聚合,也就是把每一行的所有列相加。
最大最小值:np.max/ np.min
具体使用方法和上面的类似。
其他聚合操作
Function Name |
NaN-safe Version |
Description |
|---|---|---|
np.sum |
np.nansum |
Compute sum of elements |
np.prod |
np.nanprod |
Compute product of elements(笛卡尔积) |
np.mean |
np.nanmean |
Compute mean of elements(平均值) |
np.std |
np.nanstd |
Compute standard deviation(标准偏差) |
np.var |
np.nanvar |
Compute variance(方差) |
np.min |
np.nanmin |
返回最小值 |
np.max |
np.nanmax |
返回最大值 |
np.argmin |
np.nanargmin |
返回最小值的索引 |
np.argmax |
np.nanargmax |
返回最大值的索引 |
np.median |
np.nanmedian |
返回中位数的值 |
np.percentile |
np.nanpercentile |
Compute rank-based statistics of elements |
np.any |
N/A | Evaluate whether any elements are true |
np.all |
N/A | Evaluate whether all elements are true |
np.power |
幂运算 |
在
numpy、pandas中,np.nan表示一个空数据。如果在ndarray数据中出现了np.nan数据时,聚合的结果总是np.nan,为了解决这种问题,可以调用上面表中NaN-safe Version的方法,该列中的方法,会把np.nan数据当作为0处理。
ndarray的矩阵操作
基本矩阵操作
- 算术运算符:
- 加减乘除
一个ndarray矩阵和一个数进行算术操作,结果为对矩阵中的每一个元素进行对应操作。
- 矩阵积(矩阵的点乘)
np.dot()
广播机制
【重要】ndarray广播机制的两条规则
- 规则一:为缺失的维度补维度(可以补多个维度)
- 规则二:假定缺失元素用已有值填充(假如已有的元素过多,不知道用那些元素填充,则会报错)
例1:
m = np.ones((2, 3))
a = np.arange(3)
求m+a
因为m为两维,a为一维,所以会给a补一维,将a从1*3变为2*3,其中多出来的一行,用已有的一行填充,所以a变为[[0,1,2], [0,1,2]],而m为[[1,1,1], [1,1,1]],所以相加的结果为[[1,2,3], [1,2,3]]
ndarray的排序
快速排序
np.sort()与ndarray.sort()都可以,但有区别:
np.sort()不改变输入ndarray.sort()本地处理,不占用空间,但改变输入
部分排序
np.partition(n, kth=5)意为返回一个和n一样的ndarray,其中最大的5个元素放在ndarray的末尾(但放的顺序不一定是按大小排列好的)。
np.partition(n, kth=-5)意为返回一个和n一样的ndarray,其中最小的5个元素放在ndarray的开始(但放的顺序不一定是按大小排列好的)。