知识图谱——用Python代码从文本中挖掘信息的强大数据科学技术
- 什么是知识图谱?
- 如何在图谱中表示知识?
- 依靠文本数据构建知识图谱
什么是知识图谱?
先明确一个概念:在本文中经常出现的术语“图谱”,并不是指柱状图、饼状图或线状图,而是相互关联的实体,它们可以是人、地点、组织,甚至是一个事件。
不妨说,图谱是节点和边*的组合。
看看下面的数据:
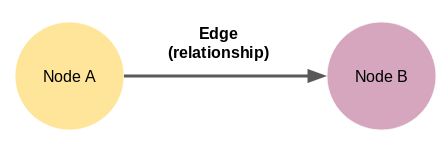
*边(Edge)是节点间的连线,用于表示节点间关系。
这里的节点a和节点b是两个不同的实体,节点通过边连接。如图是我们可以构建的最小的知识图谱——它也被称为三元组(实体-关系-实体)。
知识图谱有多种形状和大小。例如,截至2019年10月,维基数据(Wikidata)的知识图谱有59,910,568个节点。

如何在图谱中表示知识?
在开始构建知识图谱前,我们需要了解信息或知识是如何嵌入到这些图谱中的。
举例来解释:如果节点a=普京,节点b=俄罗斯,那么边很可能是“俄罗斯总统”:
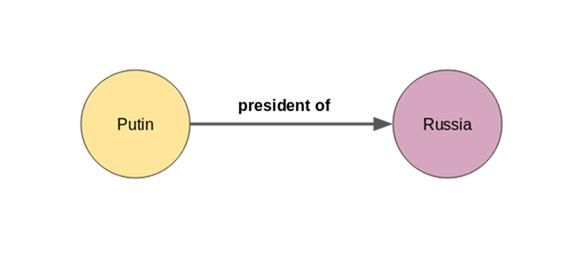
一个节点或实体也可以有不止一个关系。普京不仅是俄罗斯总统,他还曾为苏联安全机构克格勃工作。但是如何把这些关于普京的新信息,整合到上面的知识图谱中呢?
其实很简单。只需为新实体“克格勃”再添加一个节点:
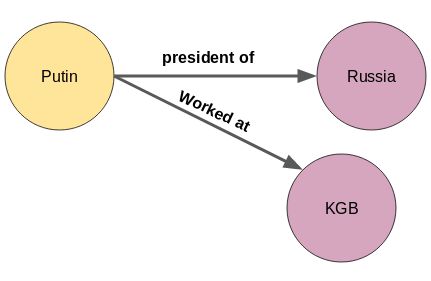
新的关系不仅可以添加在第一个节点,而且可以出现在知识图谱中的任何节点,如下所示:

俄罗斯是亚太经济合作组织(APEC)的成员国
识别实体和他们的相互关系并不是一项困难的任务。但是,手动构建知识图谱是难以处理大量信息的。没有人会浏览成千上万的文档,然后提取出所有的实体和它们之间的关系。
因此,机器无疑是更好的选择,浏览成百上千的文件对它们来说简直小菜一碟。但是还有另外一个挑战——机器不懂自然语言。这就轮到自然语言处理 (Natural Language Processing,简称NLP) 技术出场了。
想要从文本中构建知识图谱八字,让机器能理解自然语言就至关重要。这可以通过使用自然语言处理(NLP)技术来实现,如句子分割、依存句法分析、词性标注和实体识别。下文将更详细地对它们进行探讨。
句子分割
构建知识图谱的第一步是将文本或文章分割成句子。然后,列出那些只有一个主语和宾语的句子。下面是示例文本:
“在最新的男子单打排名中,印度网球选手苏米特纳加尔(Sumit Nagal)从135名上升了6个名次,达到职业生涯中的最好成绩129名。这位22岁的选手最近赢得了ATP挑战锦标赛。2019年美国网球公开赛中他首次亮相时,就在对阵费德勒的比赛中赢得了大满贯。纳加尔赢得了第一组比赛。(Indian tennis player Sumit Nagal moved up six places from 135to a career-best 129 in the latest men’s singles ranking. The 22-year-oldrecently won the ATP Challenger tournament. He madehis Grand Slam debut against Federer in the 2019 US Open. Nagal won the firstset.)”
我们把上面的段落分成几个句子:
1. 在最新的男子单打排名中,印度网球选手苏米特纳加尔(SumitNagal)从135名上升了6个名次,达到职业生涯中的最好成绩129名。(Indian tennis player Sumit Nagal moved up six places from135 to a career-best 129 in the latest men’s singles ranking.)
2. 这位22岁的选手最近赢得了ATP挑战锦标赛。(The 22-year-old recently won the ATP Challengertournament))
3. 2019年美国网球公开赛中他首次亮相时,就在对阵费德勒比赛中赢得了大满贯。(Hemade his Grand Slam debut against Federer in the 2019 US Open.)
4. 纳加尔赢得了第一组比赛。(Nagalwon the first set.)
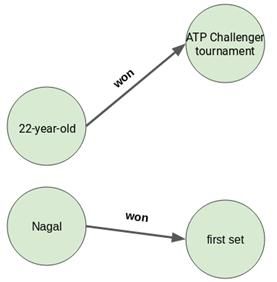
在这四个句子中,我们将选出第二个和第四个句子,因为每个句子都包含一个主语和一个宾语。第二句中,“22岁的选手(22-year-old)”是主语,宾语是“ATP挑战赛(ATP Challenger tournament)”。第四句中,主语是“纳加尔(Nagal)”,“第一组比赛(first set)”是宾语:

让机器理解文本是最大的挑战,特别是在主语和宾语不止一个的情况下。以上面两个句子为例,提取句子中的宾语有点棘手。你能想到解决这个问题的方法吗?
实体抽取
从句子中提取一个词实体并不是艰巨的任务。我们可以借助词性(POS)标签轻松做到这一点。名词和专有名词可以是我们的实体。
然而,当一个实体包括多个单词时,仅仅借助词性标记是不够的。我们需要解析句子间的复杂关系。先来获取其中一个句子的依存标记。使用流行的spaCy库来完成这个任务:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp("The 22-year-old recently won ATP Challenger tournament.")
for tok in doc:
print(tok.text, "...", tok.dep_)
输出:
The… det
22-year … amod
– … punct
old … nsubj
recently … advmod
won … ROOT
ATP … compound
Challenger … compound
tournament … dobj
. … punct
根据依存关系解析器,这个句子中的主语(nsubj)是“old”。这不是我们想要的实体。我们想要的是“22岁的选手(22-year-old)”。
“22岁的(22-year)”的依存关系标签是amod,这意味着它是(old)”的修饰语。因此,应该定义一个规则来提取这样的实体。
可以是这样的规则:提取主语/宾语及其修饰语,并提取它们之间的标点。
但是再看看句子中的宾语(dobj)。它只是“锦标赛(tournament)”而不是“ATP挑战锦标赛(ATPChallenger tournament)”。在这句里,没有修饰词,只有复合词。
复合词是指不同词组合起来所形成的新术语,它们有着和源词不同的意思。因此,我们可以更新上面的规则----提取主语/宾语及其修饰语、复合词,并提取它们之间的标点。
简而言之,我们使用依存句法分析来提取实体。
提取关系
实体提取仅仅是一半的工作。想要建立知识图谱,需要边来连接各个节点(实体)。这些边表示节点之间的关系。
回到上一节中的例子,选出几句话来构建一个知识图谱:
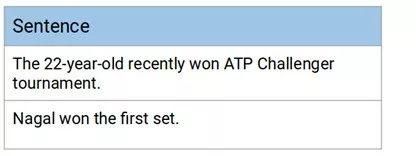
你能猜出这两个句子中主语和宾语的关系吗?
两个句子有相同的关系——“赢得(won)”。看看该如何提取这些关系。这里将再次使用依存项解析:
doc = nlp("Nagal won the first set.")
for tok in doc:
print(tok.text, "...", tok.dep_)
输出:
Nagal… nsubj
won … ROOT
the … det
first … amod
set … dobj
. … punct
为了提取关系,必须找到句子的根(root),它也是句子里的动词。因此,在这个句子里找到的关系就是“赢得(won)”。
最后,这两个句子的知识图谱是这样的:
从文本数据构建知识图谱
是时候进行代码操作了!打开Jupyter Notebooks(或者任何你喜欢的集成开发环境-IDE)。
使用一组从维基百科中找到的电影中的文本,从头开始构建一个知识图谱。我已经从500多篇维基百科文章中摘录了大约4300句话。每个句子都包含两个实体——一个主语和一个宾语。你可以点击这里下载这些句子。
推荐使用Google Colab,能加快计算的运行速度。
导入库
import re
import pandas as pd
import bs4
import requests
import spacy
from spacy import displacy
nlp = spacy.load('en_core_web_sm')
from spacy.matcher import Matcher
from spacy.tokens import Span
import networkx as nx
import matplotlib.pyplot as plt
from tqdm import tqdm
pd.set_option('display.max_colwidth', 200)
%matplotlib inline
读取数据
阅读包含维基百科句子的CSV文件:
# import wikipedia sentences
candidate_sentences = pd.read_csv("wiki_sentences_v2.csv")
candidate_sentences.shape
输出:(4318, 1)
来看几个例句:
candidate_sentences['sentence'].sample(5)
输出:

检查其中一个句子的主语和宾语。理想情况下,句子中应该有一个主语和一个宾语:
doc = nlp("the drawdown process is governed by astm standard d823")
for tok in doc:
print(tok.text, "...", tok.dep_)
输出:

很好!只有一个主语“过程”(process)和一个宾语“标准”(standard)。你可以用类似的方式检查其他句子。
实体对抽取
想要构架出一个知识图谱,最重要的是节点和它们之间的边。
这些节点是出现在维基百科语句中的实体。边是连接各个实体之间的关系。我们将以无监督的方式提取这些要素,也就是说,我们将依靠句子的语法。
其主要思想就是在浏览一个句子时,把遇到的主语和宾语提取出来。然而,还有其他挑战存在——实体可能不止一个单词,如“红酒(red wine)”,依存关系解析器只会将单个单词标记为主语或宾语。
因此,下面创建了一个函数来从一个句子中提取主语和宾语(也就是实体),同时解决了上面提到的挑战