知识图谱---Neo4J篇
一、什么是Neo4J
知识图谱由于其数据包含实体、属性、关系等,常见的关系型数据库诸如MySQL之类不能很好的体现数据的这些特点,因此知识图谱数据的存储一般是采用图数据库(Graph Databases)。而Neo4j是其中最为常见的图数据库。
Neo4j是基于Java的图形数据库,运行Neo4j需要启动JVM进程,因此必须安装JAVA SE的JDK,并且JDK版本需要和Neo4j版本兼容。
二、Neo4J安装
官网下载(下载很慢)
https://neo4j.com/download-center/#releases
国内的下载地址
http://neo4j.com.cn/topic/5b003eae9662eee704f31cee
步骤
- 将解压后的文件解压到任意盘符下:本文解压到D:\neo4j-community-3.5.5-windows
- 配置系统环境变量。
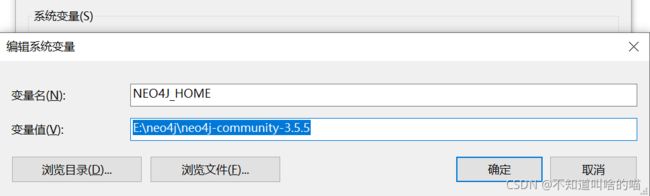
编辑path,且新建:

之后一直确定就行。 - 验证是否安装成功:输入neo4j.bat console,出现下图则安装成功

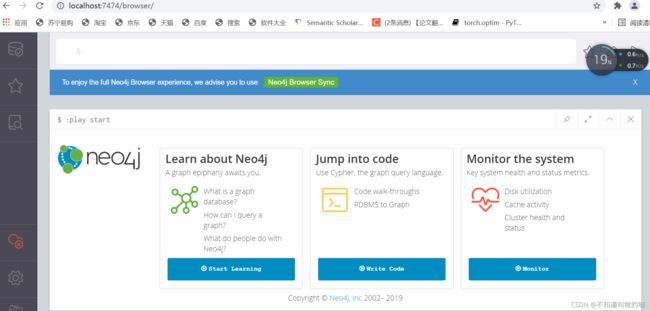
访问Neo4j数据库
访问http://localhost:7474,(Neo4j三种连接方式中的一种),默认用户名和密码为:neo4j,需要修改为自己的密码。访问后如下图:
- 注册neo4j服务
输入neo4j install-service

2.neo4j服务
输入 neo4j start 开启neo4j服务
输入 neo4j stop 停止neo4j服务
输入 neo4j restart 重启neo4j服务
输入 neo4j status 查询neo4j服务
可以使用Neo4j了
Cypher查询语言
Cypher是Neo4J的声明式图形查询语言,允许用户不必编写图形结构的遍历代码,就可以对图形数据进行高效的查询。Cypher的设计目的类似SQL,适合于开发者以及在数据库上做点对点模式(ad-hoc)查询的专业操作人员。
其具备的能力包括:
- 创建、更新、删除节点和关系
- 通过模式匹配来查询和修改节点和关系
- 管理索引和约束等
三、Neo4J实战教程
本文通过一个实际的案例来一步一步使用Cypher来操作Neo4J。
这个案例的节点主要包括人物和城市两类,人物和人物之间有朋友、夫妻等关系,人物和城市之间有出生地的关系。
- 首先,我们删除数据库中以往的图,确保一个空白的环境进行操作:
MATCH (n) DETACH DELETE n
这里,MATCH是匹配操作,而小括号()代表一个节点node(可理解为括号类似一个圆形),括号里面的n为标识符。
原有数据: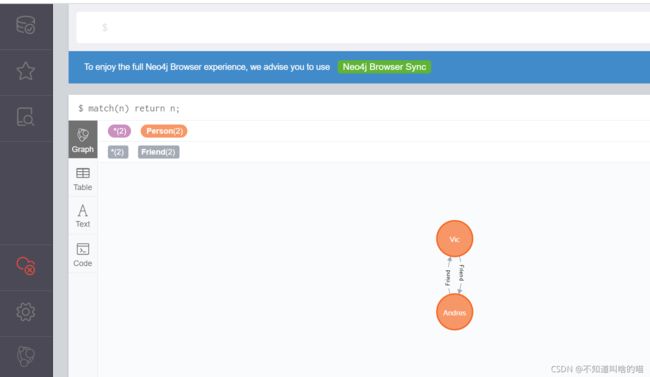
使用该语言后:

2. 接着,我们创建一个人物节点:
CREATE (n:Person {name:'John'}) RETURN n
CREATE是创建操作,Person是标签,代表节点的类型。花括号{}代表节点的属性,属性类似Python的字典。这条语句的含义就是创建一个标签为Person的节点,该节点具有一个name属性,属性值是John。
如图所示,在Neo4J的界面上可以看到创建成功的节点。

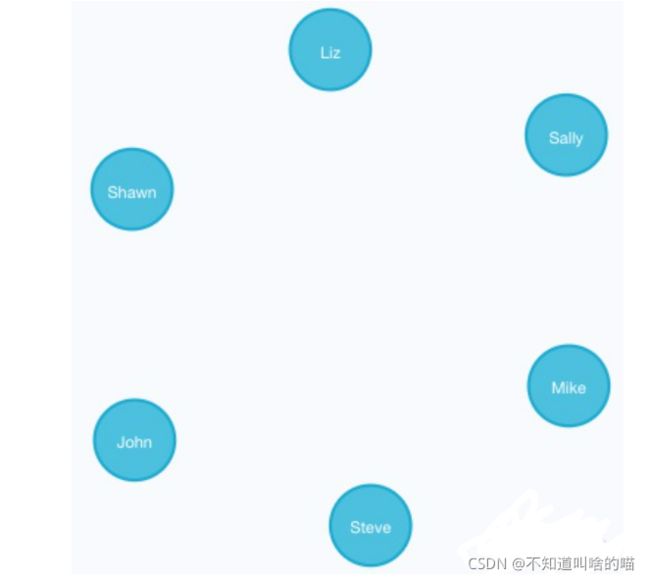
3. 我们继续来创建更多的人物节点,并分别命名:
CREATE (n:Person {name:'Sally'}) RETURN n
CREATE (n:Person {name:'Steve'}) RETURN n
CREATE (n:Person {name:'Mike'}) RETURN n
CREATE (n:Person {name:'Liz'}) RETURN n
CREATE (n:Person {name:'Shawn'}) RETURN n
如图所示,6个人物节点创建成功
4. 接下来创建地区节点
CREATE (n:Location {city:'Miami', state:'FL'})
CREATE (n:Location {city:'Boston', state:'MA'})
CREATE (n:Location {city:'Lynn', state:'MA'})
CREATE (n:Location {city:'Portland', state:'ME'})
CREATE (n:Location {city:'San Francisco', state:'CA'})
可以看到,节点类型为Location,属性包括city和state。
如图所示,共有6个人物节点、5个地区节点,Neo4J贴心地使用不用的颜色来表示不同类型的节点。
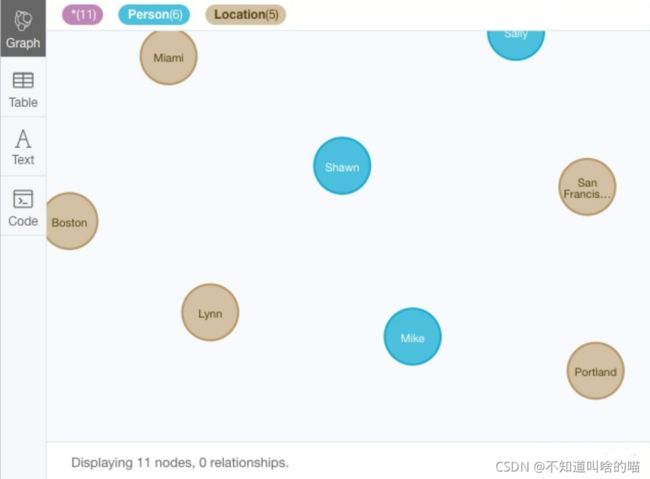
5. 接下来创建关系
MATCH (a:Person {name:'Liz'}),
(b:Person {name:'Mike'})
MERGE (a)-[:FRIENDS]->(b)
这里的方括号[]即为关系,FRIENDS为关系的类型。注意这里的箭头–>是有方向的,表示是从a到b的关系。 如图,Liz和Mike之间建立了FRIENDS关系,通过Neo4J的可视化很明显的可以看出:

6. 关系也可以增加属性
MATCH (a:Person {name:'Shawn'}),
(b:Person {name:'Sally'})
MERGE (a)-[:FRIENDS {since:2001}]->(b)
在关系中,同样的使用花括号{}来增加关系的属性,也是类似Python的字典,这里给FRIENDS关系增加了since属性,属性值为2001,表示他们建立朋友关系的时间。
- 接下来增加更多的关系
MATCH (a:Person {name:'Shawn'}), (b:Person {name:'John'}) MERGE (a)-[:FRIENDS {since:2012}]->(b)
MATCH (a:Person {name:'Mike'}), (b:Person {name:'Shawn'}) MERGE (a)-[:FRIENDS {since:2006}]->(b)
MATCH (a:Person {name:'Liz'}), (b:Person {name:'John'}) MERGE (a)-[:MARRIED {since:1998}]->(b)
如图,人物关系图已建立好

8. 然后,我们需要建立不同类型节点之间的关系-人物和地点的关系
MATCH (a:Person {name:'John'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1978}]->(b)
这里的关系是BORN_IN,表示出生地,同样有一个属性,表示出生年份。
如图,在人物节点和地区节点之间,人物出生地关系已建立好。

- 同样建立更多人的出生地
MATCH (a:Person {name:'Liz'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1981}]->(b)
MATCH (a:Person {name:'Mike'}), (b:Location {city:'San Francisco'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)
MATCH (a:Person {name:'Shawn'}), (b:Location {city:'Miami'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)
MATCH (a:Person {name:'Steve'}), (b:Location {city:'Lynn'}) MERGE (a)-[:BORN_IN {year:1970}]->(b)
建好以后,整个图如下

10. 至此,知识图谱的数据已经插入完毕,可以开始做查询了。我们查询下所有在Boston出生的人物
MATCH (a:Person)-[:BORN_IN]->(b:Location {city:'Boston'}) RETURN a,b

11. 查询所有对外有关系的节点
MATCH (a)-->() RETURN a
注意这里箭头的方向,返回结果不含任何地区节点,因为地区并没有指向其他节点(只是被指向)

12. 查询所有有关系的节点
MATCH (a)--() RETURN a

- 查询所有对外有关系的节点,以及关系类型
MATCH (a)-[r]->() RETURN a.name, type(r)
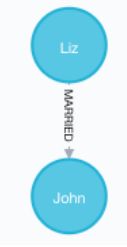
- 查询所有有结婚关系的节点
MATCH (n)-[:MARRIED]-() RETURN n
15. 创建节点的时候就建好关系
CREATE (a:Person {name:'Todd'})-[r:FRIENDS]->(b:Person {name:'Carlos'})

16. 查找某人的朋友的朋友
MATCH (a:Person {name:'Mike'})-[r1:FRIENDS]-()-[r2:FRIENDS]-(friend_of_a_friend) RETURN friend_of_a_friend.name AS fofName

17. 增加/修改节点的属性
MATCH (a:Person {name:'Liz'}) SET a.age=34
MATCH (a:Person {name:'Shawn'}) SET a.age=32
MATCH (a:Person {name:'John'}) SET a.age=44
MATCH (a:Person {name:'Mike'}) SET a.age=25
这里,SET表示修改操作
- 删除节点的属性
MATCH (a:Person {name:'Mike'}) SET a.test='test'
MATCH (a:Person {name:'Mike'}) REMOVE a.test
删除属性操作主要通过REMOVE
19. 删除节点
MATCH (a:Location {city:'Portland'}) DELETE a
删除节点操作是DELETE
- 删除有关系的节点
MATCH (a:Person {name:'Todd'})-[rel]-(b:Person) DELETE a,b,rel
总结
本文重点针对常见的知识图谱图数据库Neo4J进行了介绍、安装,并且采用一个实际的案例来说明Neo4J的查询语言Cypher的使用方法。
当然,类似MySQL一样,在实际的生产应用中,除了简单的查询操作会在Neo4J的web页面进行外,一般还是使用Python、Java等的driver来在程序中实现